Keras 3.0
- 원본 링크 : https://keras.io/keras_3/
- 최종 확인 : 2024-11-18
5개월에 걸친 광범위한 공개 베타 테스트를 거쳐, Keras 3.0의 공식 출시를 발표하게 되어 기쁩니다. Keras 3은 Keras를 완전히 다시 작성하여, JAX, TensorFlow 또는 PyTorch에서 Keras 워크플로를 실행할 수 있게 해주고, 완전히 새로운 대규모 모델 트레이닝 및 배포 기능을 제공합니다. 자신에게 가장 적합한 프레임워크를 선택하고, 현재 목표에 따라 하나에서 다른 프레임워크로 전환할 수 있습니다. 또한 Keras를 낮은 레벨 크로스 프레임워크 언어로 사용하여, JAX, TensorFlow 또는 PyTorch의 기본 워크플로에서 사용할 수 있는 레이어, 모델 또는 메트릭과 같은 커스텀 구성 요소를 하나의 코드베이스로 개발할 수 있습니다.
멀티 프레임워크 머신러닝에 오신 것을 환영합니다.
Keras를 사용하면 훌륭한 UX, API 디자인 및 디버깅 가능성에 대한 강박관념을 통해, 고속 개발이 가능하다는 이점을 이미 알고 계실 것입니다. 또한 250만 명 이상의 개발자가 선택한 실전 테스트 프레임워크로, Waymo 자율주행 차량과 YouTube 추천 엔진과 같이, 세계에서 가장 정교하고 규모가 큰 ML 시스템을 구동합니다. 하지만 새로운 멀티 백엔드 Keras 3를 사용하는 것의 추가 이점은 무엇일까요?
- 항상 모델에 최상의 성능을 제공합니다. 우리의 벤치마크에서, JAX는 일반적으로 GPU, TPU 및 CPU에서 최상의 트레이닝 및 추론 성능을 제공하지만, 비 XLA TensorFlow가 GPU에서 더 빠른 경우가 있으므로 결과는 모델마다 다릅니다. 코드의 어떤 부분도 변경하지 않고, 모델에 최상의 성능을 제공하는 백엔드를 동적으로 선택할 수 있으므로, 가능한 가장 높은 효율성으로 트레이닝하고 제공할 수 있습니다.
- 모델에 대한 생태계 선택권 잠금 해제.
모든 Keras 3 모델은 PyTorch
Module로 인스턴스화하거나, TensorFlowSavedModel로 내보내거나, stateless JAX 함수로 인스턴스화할 수 있습니다. 즉, PyTorch 생태계 패키지, TensorFlow 배포 및 프로덕션 도구(TF-Serving, TF.js 및 TFLite 등)의 전체 범위, JAX 대규모 TPU 트레이닝 인프라와 함께 Keras 3 모델을 사용할 수 있습니다. Keras 3 API를 사용하여,model.py하나를 작성하고 ML 세계가 제공하는 모든 것에 액세스하세요. - JAX로 대규모 모델 병렬 처리 및 데이터 병렬 처리 활용.
Keras 3에는 현재 JAX 백엔드에 구현된 완전히 새로운 배포 API인,
keras.distribution네임스페이스가 포함되어 있습니다. (곧 TensorFlow 및 PyTorch 백엔드에 제공) 임의의 모델 규모와 클러스터 규모에서 모델 병렬 처리, 데이터 병렬 처리 및 두 가지의 조합을 쉽게 수행할 수 있습니다. 모델 정의, 트레이닝 논리 및 샤딩 구성을 모두 서로 분리하여, 배포 워크플로를 쉽게 개발하고 유지 관리할 수 있습니다. 시작 가이드를 참조하세요. - 오픈 소스 모델 릴리스의 도달 범위를 극대화하세요. 사전 트레이닝된 모델을 릴리스하고 싶으신가요? 가능한 한 많은 사람이 사용할 수 있게 하고 싶으신가요? 순수 TensorFlow 또는 PyTorch로 구현하면, 커뮤니티의 약 절반이 사용할 수 있습니다. Keras 3로 구현하면, 선택한 프레임워크와 관계없이 누구나 즉시 사용할 수 있습니다. (Keras 사용자가 아니더라도) 추가 개발 비용 없이 두 배의 효과를 얻을 수 있습니다.
- 어떠한 소스로부터의 데이터 파이프라인이라도 사용합니다.
Keras 3
fit()/evaluate()/predict()루틴은tf.data.Dataset객체, PyTorchDataLoader객체, NumPy 배열, Pandas 데이터프레임과 호환됩니다. 사용하는 백엔드와 상관이 가능합니다. PyTorchDataLoader에서 Keras 3 + TensorFlow 모델을 트레이닝하거나,tf.data.Dataset에서 Keras 3 + PyTorch 모델을 트레이닝할 수 있습니다.
JAX, TensorFlow 및 PyTorch에서 사용 가능한 전체 Keras API.
Keras 3은 전체 Keras API를 구현하고, TensorFlow, JAX 및 PyTorch에서 사용할 수 있도록 합니다. 100개가 넘는 레이어, 수십 개의 메트릭, 손실 함수, 옵티마이저 및 콜백, Keras 트레이닝 및 평가 루프, Keras 저장 및 직렬화 인프라가 있습니다. 여러분이 알고 사랑하는 모든 API가 여기에 있습니다.
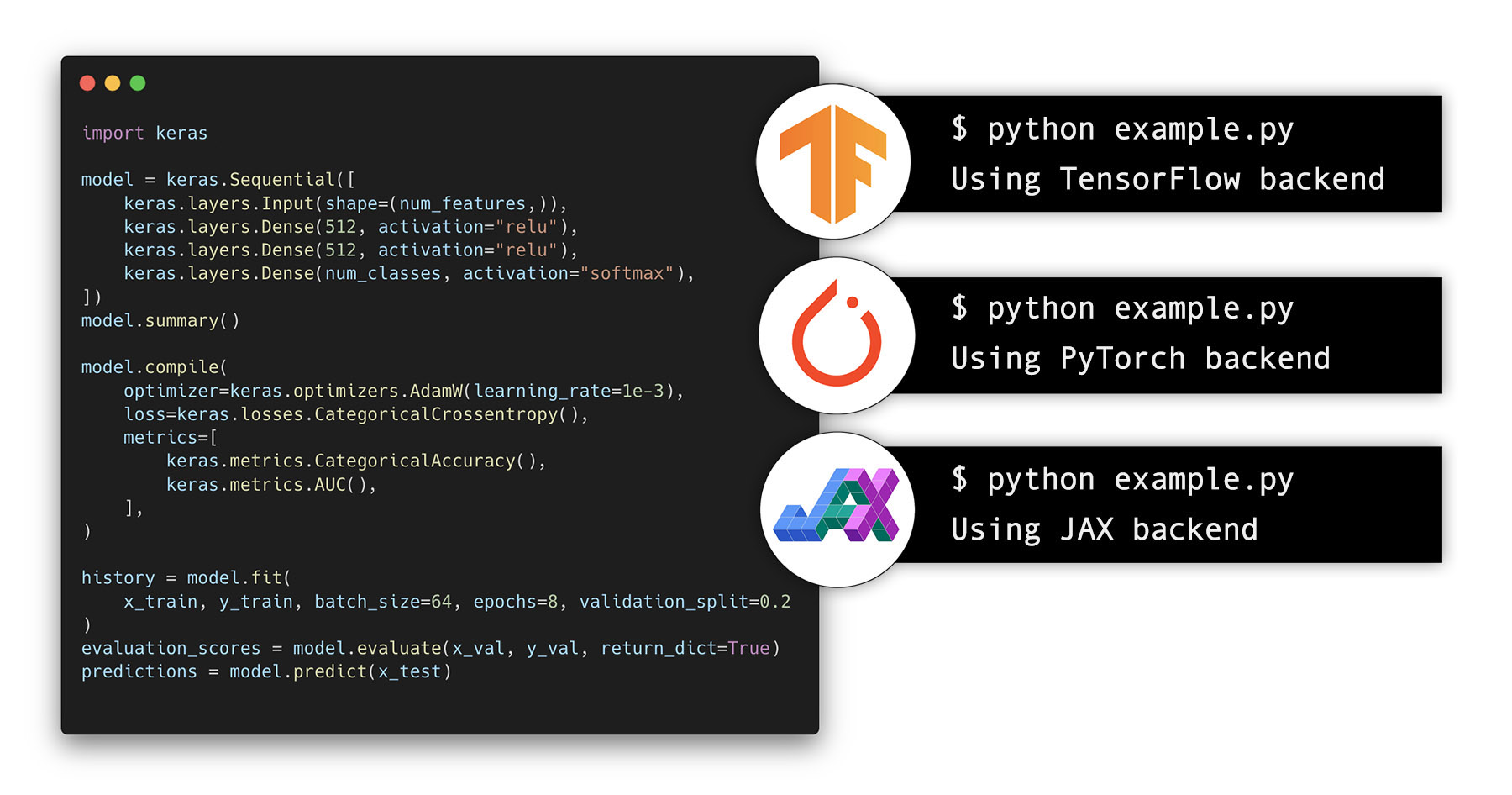
기본 제공 레이어만 사용하는 모든 Keras 모델은 지원되는 모든 백엔드에서 즉시 작동합니다.
사실, 기본 제공 레이어만 사용하는 기존 tf.keras 모델은 JAX 및 PyTorch에서 바로 실행을 시작할 수 있습니다!
맞습니다. 당신의 코드베이스에 완전히 새로운 기능 세트가 추가된 것입니다.
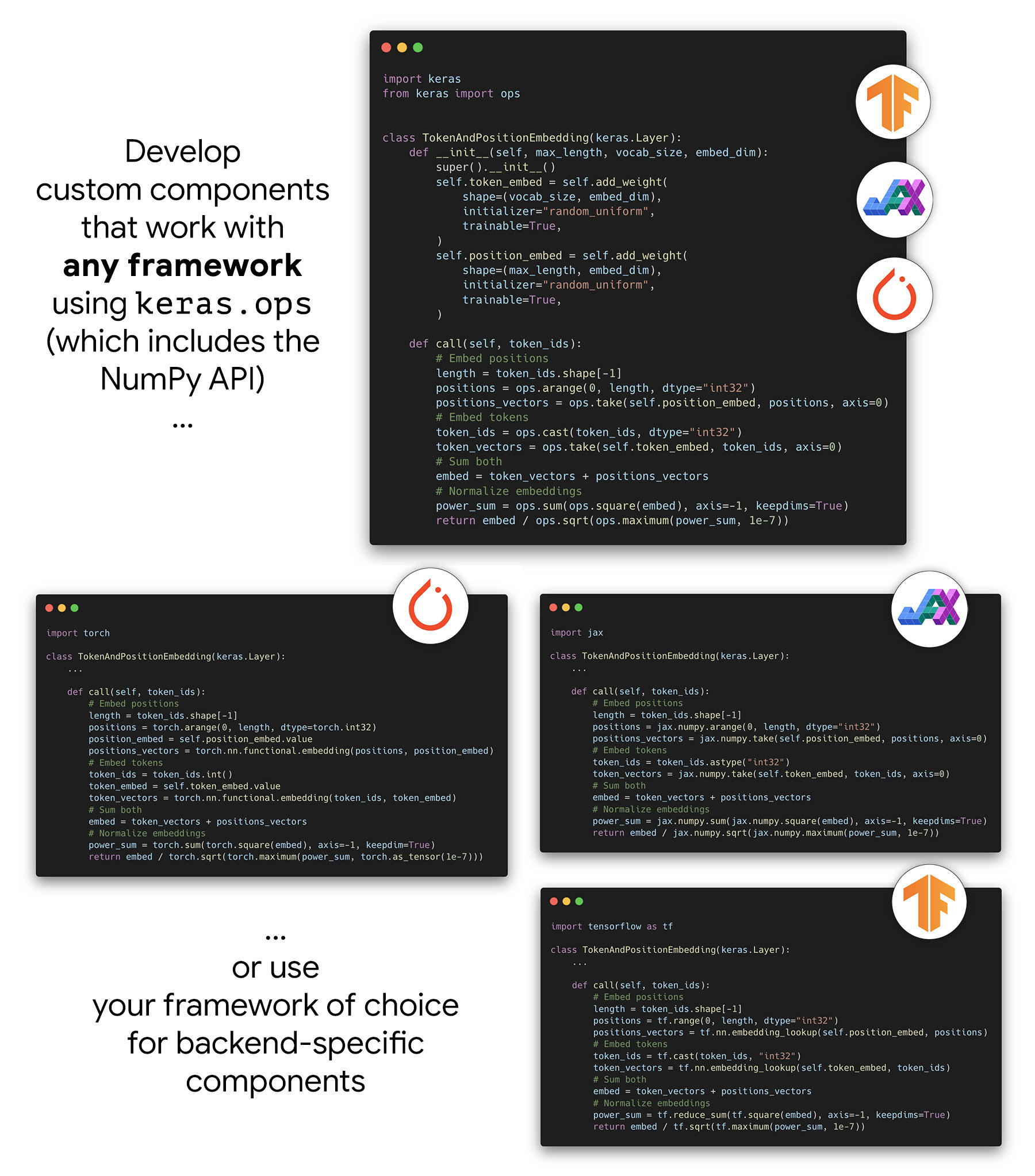
Author 멀티 프레임워크 레이어, 모델, 메트릭…
Keras 3를 사용하면, 모든 프레임워크에서 동일하게 작동하는 구성 요소
(임의의 커스텀 레이어 또는 사전 트레이닝된 모델 등)를 만들 수 있습니다.
특히, Keras 3는 모든 백엔드에서 작동하는 keras.ops 네임스페이스에 대한 액세스를 제공합니다. 여기에는 다음이 포함됩니다.
- NumPy API의 전체 구현.
“NumPy와 유사한” 것이 아니라, 문자 그대로 NumPy API이며, 동일한 함수와 동일한 인수가 있습니다.
ops.matmul,ops.sum,ops.stack,ops.einsum등을 살펴보세요. - 신경망 특정 함수 세트
NumPy에 없는
ops.softmax,ops.binary_crossentropy,ops.conv등과 같은 함수들.
keras.ops의 ops만 사용하는 한,
커스텀 레이어, 커스텀 손실, 커스텀 메트릭 및 커스텀 옵티마이저는
JAX, PyTorch 및 TensorFlow에서 동일한 코드로 작동합니다.
즉, 하나의 구성 요소 구현(예: 단일 model.py와 단일 체크포인트 파일)만 유지할 수 있으며,
모든 프레임워크에서 정확히 동일한 수치로 사용할 수 있습니다.
…모든 JAX, TensorFlow 및 PyTorch 워크플로와 원활하게 작동합니다.
Keras 3는 Keras 모델, Keras 옵티마이저, Keras 손실 및 메트릭을 정의하고,
fit(), evaluate() 및 predict()를 호출하는 Keras 중심 워크플로에만 사용하도록 설계된 것이 아닙니다.
또한 낮은 레벨 백엔드 네이티브 워크플로와도 원활하게 작동하도록 설계되었습니다.
Keras 모델(또는 손실이나 메트릭과 같은 다른 구성 요소)을 가져와,
JAX 트레이닝 루프, TensorFlow 트레이닝 루프 또는 PyTorch 트레이닝 루프에서 사용하거나,
JAX 또는 PyTorch 모델의 일부로 사용할 수 있으며, 아무런 마찰이 없습니다.
Keras 3은 이전에 TensorFlow에서 tf.keras가 제공했던 것과 정확히 같은 수준의 낮은 레벨 구현 유연성을 JAX 및 PyTorch에서 제공합니다.
다음을 수행할 수 있습니다.
optax옵티마이저,jax.grad,jax.jit,jax.pmap을 사용하여, Keras 모델을 트레이닝하는 낮은 레벨 JAX 트레이닝 루프를 작성합니다.tf.GradientTape및tf.distribute를 사용하여, Keras 모델을 트레이닝하는 낮은 레벨 TensorFlow 트레이닝 루프를 작성합니다.torch.optim옵티마이저,torch손실 함수 및torch.nn.parallel.DistributedDataParallel래퍼를 사용하여, Keras 모델을 트레이닝하는 낮은 레벨 PyTorch 트레이닝 루프를 작성합니다.- PyTorch
Module에서 Keras 레이어를 사용합니다. (이것 역시Module인스턴스이기 때문입니다!) - Keras 모델에서 PyTorch
Module을 마치 Keras 레이어인 것처럼 사용합니다. - 등등.

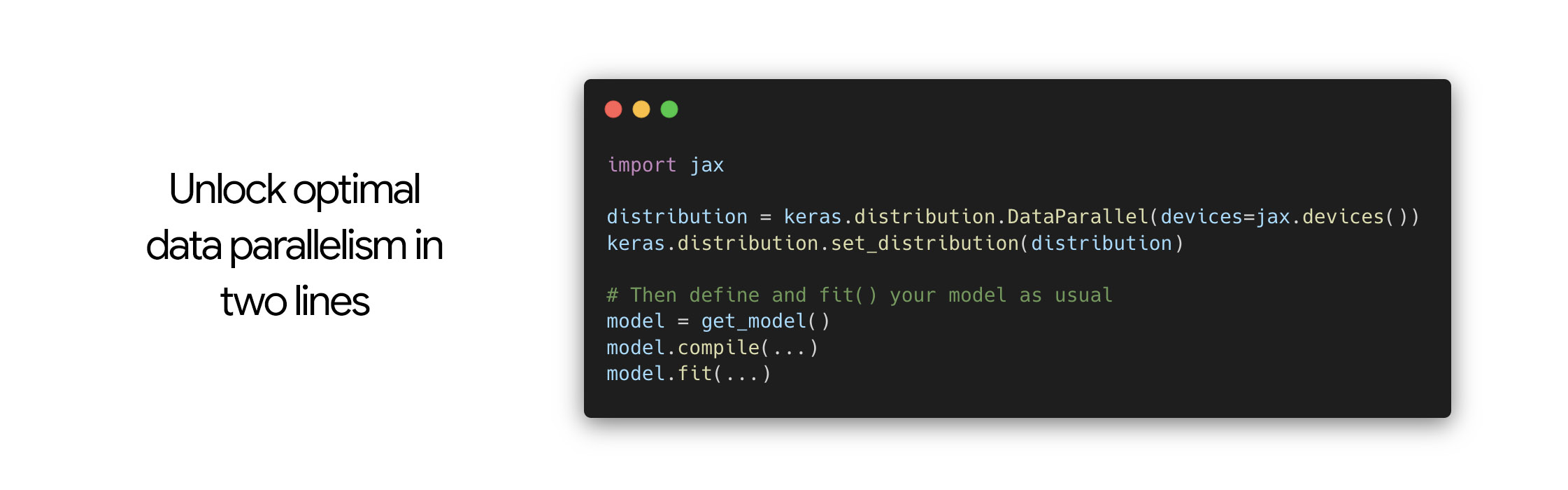
대규모 데이터 병렬 처리 및 모델 병렬 처리를 위한 새로운 배포 API.
우리가 작업한 모델은 점점 더 커졌기 때문에, 다중 기기 모델 샤딩 문제에 대한 Kerasic 솔루션을 제공하고 싶었습니다. 우리가 설계한 API는 모델 정의, 트레이닝 로직, 샤딩 구성을 완전히 분리하여, 모델을 단일 기기에서 실행되는 것처럼 작성할 수 있습니다. 그런 다음 모델을 트레이닝할 때 임의의 샤딩 구성을 임의의 모델에 추가할 수 있습니다.
데이터 병렬 처리(여러 기기에서 작은 모델을 동일하게 복제)는 두 줄로 처리할 수 있습니다.
모델 병렬 처리를 사용하면, 여러 이름 지어진 차원을 따라, 모델 변수와 중간 출력 텐서에 대한 샤딩 레이아웃을 지정할 수 있습니다. 일반적인 경우, 사용 가능한 장치를 2D 그리드( 장치 메시 라고 함)로 구성합니다. 여기서 첫 번째 차원은 데이터 병렬 처리에 사용되고, 두 번째 차원은 모델 병렬 처리에 사용됩니다. 그런 다음 모델이 모델 차원을 따라 샤딩되고, 데이터 차원을 따라 복제되도록 구성합니다.
API를 사용하면 정규 표현식을 통해 모든 변수와 모든 출력 텐서의 레이아웃을 구성할 수 있습니다. 이를 통해 전체 변수 범주에 대해 동일한 레이아웃을 빠르게 지정하기 쉽습니다.

새로운 배포 API는 멀티 백엔드가 되도록 의도되었지만, 현재로서는 JAX 백엔드에서만 사용할 수 있습니다. TensorFlow와 PyTorch 지원은 곧 제공될 예정입니다. 이 가이드로 시작하세요!
사전 트레이닝된 모델.
Keras 3에서 오늘부터 사용할 수 있는 광범위한 사전 학습된 모델이 있습니다.
모든 40개 Keras 애플리케이션 모델(keras.applications 네임스페이스)은 모든 백엔드에서 사용할 수 있습니다.
KerasCV 및
KerasHub의 광범위한 사전 트레이닝된 모델도 모든 백엔드에서 작동합니다.
여기에는 다음이 포함됩니다.
- BERT
- OPT
- Whisper
- T5
- StableDiffusion
- YOLOv8
- SegmentAnything
- etc.
모든 백엔드로 크로스 프레임워크 데이터 파이프라인 지원.
멀티 프레임워크 ML은 멀티 프레임워크 데이터 로딩 및 전처리도 의미합니다. Keras 3 모델은 JAX, PyTorch 또는 TensorFlow 백엔드를 사용하든 관계없이, 광범위한 데이터 파이프라인을 사용하여 트레이닝할 수 있습니다. 그냥 작동합니다.
tf.data.Dataset파이프라인: 확장 가능한 프로덕션 ML에 대한 참조.torch.utils.data.DataLoader객체.- NumPy 배열 및 Pandas 데이터프레임.
- Keras 자체
keras.utils.PyDataset객체.
복잡성의 점진적 공개.
복잡성의 점진적 공개 는 Keras API의 핵심 디자인 원칙입니다. Keras는 모델을 빌드하고 트레이닝하는데 “진정한” 단일 방식을 따르도록 강요하지 않습니다. 대신, 매우 높은 레벨에서 매우 낮은 레벨까지 다양한 사용자 프로필에 해당하는 광범위한 워크플로를 지원합니다.
즉, Sequential 및 Functional 모델을 사용하여, fit()로 트레이닝하는 것과 같은,
간단한 워크플로로 시작할 수 있으며, 더 많은 유연성이 필요할 때 이전 코드 대부분을 재사용하면서,
다양한 구성 요소를 쉽게 커스터마이즈할 수 있습니다.
요구 사항이 더 구체적이 되어도, 갑자기 복잡성 절벽에서 떨어지지 않고, 다른 도구 세트로 전환할 필요가 없습니다.
이 원칙을 모든 백엔드에 적용했습니다.
예를 들어, fit()의 힘을 활용하면서도 트레이닝 루프에서 일어나는 일을 커스터마이즈할 수 있으며,
처음부터 자신의 트레이닝 루프를 작성할 필요 없이, train_step 메서드를 재정의하기만 하면 됩니다.
PyTorch와 TensorFlow에서 작동하는 방식은 다음과 같습니다.
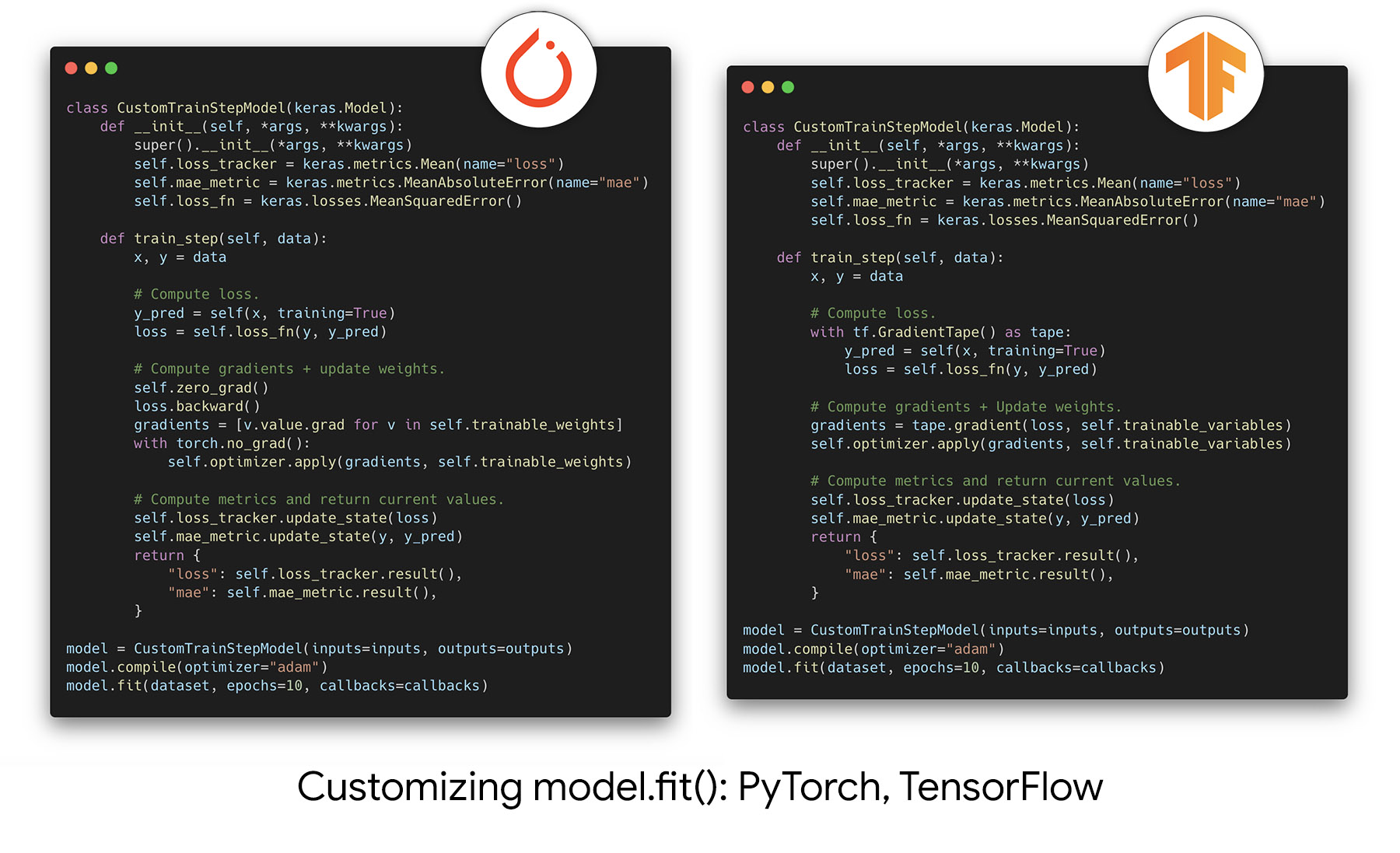
그리고 JAX 버전에 대한 링크가 있습니다.
레이어, 모델, 메트릭 및 옵티마이저를 위한 새로운 stateless API.
함수형 프로그래밍을 즐기시나요? 정말 재밌을 겁니다.
Keras의 모든 stateful 객체(즉, 트레이닝 또는 평가 중에 업데이트되는 숫자 변수를 소유한 객체)는 이제 stateless API를 가지므로, JAX 함수(완전히 stateless여야 함)에서 사용할 수 있습니다.
- 모든 레이어와 모델에는
__call__()를 미러링하는stateless_call()메서드가 있습니다. - 모든 옵티마이저에는
apply()를 미러링하는stateless_apply()메서드가 있습니다. - 모든 메트릭에는
update_state()를 미러링하는stateless_update_state()메서드와result()를 미러링하는stateless_result()메서드가 있습니다.
이러한 메서드에는 어떠한 부수 효과도 없습니다. 대상 객체의 상태 변수의 현재 값을 입력으로 받고, 업데이트 값을 출력의 일부로 반환합니다. 예:
outputs, updated_non_trainable_variables = layer.stateless_call(
trainable_variables,
non_trainable_variables,
inputs,
)이러한 메서드를 직접 구현할 필요는 없습니다.
stateful 버전(예: call() 또는 update_state())을 구현해 놓았다면, 자동으로 사용할 수 있습니다.
Keras 2에서 Keras 3으로 이동
Keras 3은 Keras 2와 매우 높은 이전 버전 호환성을 가집니다. Keras 2의 퍼블릭 API 표면을 구현하며, 여기에 나열된 제한된 수의 예외가 있습니다. 대부분 사용자는 Keras 3에서 Keras 스크립트를 실행하기 위해 코드를 변경할 필요가 없습니다.
대규모 코드베이스는 위에 나열된 예외 중 하나에 걸릴 가능성이 더 높고,
비공개 API나 더 이상 사용되지 않는 API(tf.compat.v1.keras 네임스페이스, experimental 네임스페이스, keras.src 비공개 네임스페이스)를 사용했을 가능성이 더 높기 때문에,
일부 코드 변경이 필요할 가능성이 높습니다.
Keras 3으로의 이전을 돕기 위해,
여러분이 겪을 수 있는 모든 문제에 대한 빠른 해결책이 담긴 완전한
마이그레이션 가이드를 출시합니다.
Keras 3의 변경 사항을 무시하고, TensorFlow와 함께 Keras 2를 계속 사용할 수도 있습니다. 이는 적극적으로 개발되지는 않지만, 업데이트된 종속성으로 계속 실행해야 하는 프로젝트에 좋은 옵션이 될 수 있습니다. 두 가지 가능성이 있습니다.
keras를 독립형 패키지로 액세스했다면,pip install tf_keras를 통해 설치할 수 있는 Python 패키지 대신,tf_keras를 사용하도록 전환하기만 하면 됩니다. 코드와 API는 전혀 변경되지 않았습니다. 다른 패키지 이름을 가진 Keras 2.15입니다.tf_keras의 버그를 계속 수정하고 정기적으로 새 버전을 출시할 것입니다. 그러나, 패키지가 현재 유지 관리 모드에 있으므로, 새로운 기능이나 성능 개선 사항은 추가되지 않습니다.tf.keras를 통해keras에 액세스했다면, TensorFlow 2.16까지 즉각적인 변경 사항은 없습니다. TensorFlow 2.16 이상에서는 기본적으로 Keras 3을 사용합니다. TensorFlow 2.16 이상에서 Keras 2를 계속 사용하려면, 먼저tf_keras를 설치한 다음, 환경 변수TF_USE_LEGACY_KERAS=1을 export 할 수 있습니다. 이렇게 하면, TensorFlow 2.16 이상에서 tf.keras를 로컬에 설치된tf_keras패키지로 확인하게 됩니다. 그러나 이는 자신의 코드에만 영향을 미칠 수 있다는 점에 유의하세요. Python 프로세스에서tf.keras를 import 하는 모든 패키지에 영향을 미칩니다. 변경 사항이 자신의 코드에만 영향을 미치도록 하려면,tf_keras패키지를 사용해야 합니다.
라이브러리를 즐기세요!
새로운 Keras를 시도하고 다중 프레임워크 ML을 활용하여 워크플로를 개선할 수 있게 되어 기쁩니다. 문제점, 마찰 지점, 기능 요청 또는 성공 사례 등 어떤 결과가 나왔는지 알려주세요. 여러분의 의견을 듣고 싶습니다!
FAQ
Q: Keras 3는 레거시 Keras 2와 호환되나요?
tf.keras로 개발한 코드는 일반적으로 Keras 3(TensorFlow 백엔드 포함)에서 그대로 실행할 수 있습니다.
주의해야 할 몇 가지 비호환성이 있으며,
모두 이 마이그레이션 가이드에서 다룹니다.
tf.keras와 Keras 3의 API를 나란히 사용하는 것은 불가능합니다.
서로 다른 패키지이며, 완전히 별도의 엔진에서 실행되기 때문입니다.
Q: 레거시 Keras 2에서 개발된 사전 트레이닝된 모델이 Keras 3에서 작동합니까?
일반적으로 그렇습니다.
모든 tf.keras 모델은 TensorFlow 백엔드가 있는 Keras 3에서 바로 작동해야 합니다.
(.keras v3 형식으로 저장해야 함)
또한 모델이 기본 제공 Keras 레이어만 사용하는 경우,
JAX 및 PyTorch 백엔드가 있는 Keras 3에서도 바로 작동합니다.
모델에 TensorFlow API를 사용하여 작성된 커스텀 레이어가 포함된 경우,
일반적으로 코드를 백엔드에 구애받지 않도록 변환하는 것이 쉽습니다.
예를 들어, Keras 애플리케이션의 모든 40개 레거시 tf.keras 모델을
백엔드에 구애받지 않도록 변환하는 데 몇 시간 밖에 걸리지 않았습니다.
Q: Keras 3 모델을 한 백엔드에 저장하고 다른 백엔드에 다시 로드할 수 있나요?
네, 가능합니다. 저장된 .keras 파일에는 백엔드 특수화가 전혀 없습니다.
저장된 Keras 모델은 프레임워크에 구애받지 않으며, 어떤 백엔드에라도 다시 로드할 수 있습니다.
그러나 다른 백엔드로 커스텀 구성 요소가 포함된 모델을 다시 로드하려면,
커스텀 구성 요소를 백엔드에 구애받지 않는 API(예: keras.ops)를 사용하여 구현해야 합니다.
Q: tf.data 파이프라인 내부에서 Keras 3 구성 요소를 사용할 수 있나요?
TensorFlow 백엔드를 사용하면, Keras 3는 tf.data와 완벽하게 호환됩니다.
(예: Sequential 모델을 tf.data 파이프라인으로 .map()할 수 있음)
다른 백엔드를 사용하면, Keras 3는 tf.data에 대한 지원이 제한적입니다.
임의의 레이어나 모델을 tf.data 파이프라인으로 .map()할 수 없습니다.
그러나, IntegerLookup 또는 CategoryEncoding과 같이
tf.data와 함께 특정 Keras 3 전처리 레이어를 사용할 수 있습니다.
tf.data 파이프라인(Keras를 사용하지 않음)을 사용하여,
.fit(), .evaluate() 또는 .predict()에 대한 호출을 제공하는 경우,
모든 백엔드에서 바로 작동합니다.
Q: Keras 3 모델은 다른 백엔드로 실행해도 동일하게 동작합니까?
예, 숫자는 백엔드 간에 동일합니다. 그러나 다음 경고 사항을 명심하세요.
- RNG 동작은 백엔드 간에 다릅니다. (시드 후에도 결과는 각 백엔드에서 결정적이지만 백엔드 간에는 다릅니다) 따라서, 랜덤 가중치 초기화 값과 드롭아웃 값은 백엔드 간에 다릅니다.
- 부동 소수점 구현의 특성으로 인해 결과는 함수 실행당 float32에서 최대
1e-7정밀도까지만 동일합니다. 따라서 모델을 오랫동안 트레이닝하면, 작은 숫자 차이가 누적되어 눈에 띄는 숫자 차이가 발생할 수 있습니다. - PyTorch에서 비대칭 패딩을 사용한 평균 풀링에 대한 지원이 부족하기 때문에,
padding="same"을 사용한 평균 풀링 레이어는 경계 행/열에 다른 숫자를 생성할 수 있습니다. 실제로 이런 일은 자주 발생하지 않습니다. 40개의 Keras Applications 비전 모델 중 하나만 영향을 받았습니다.
Q: Keras 3는 분산 트레이닝을 지원합니까?
데이터 병렬 분산은 JAX, TensorFlow, PyTorch에서 기본적으로 지원됩니다.
모델 병렬 분산은 keras.distribution API를 사용하여 JAX에서 기본적으로 지원됩니다.
TensorFlow 사용 시:
Keras 3는 tf.distribute와 호환됩니다.
Distribution Strategy scope를 열고, 그 안에서 모델을 생성/트레이닝하기만 하면 됩니다.
여기에 예시가 있습니다.
PyTorch 사용 시:
Keras 3는 PyTorch의 DistributedDataParallel 유틸리티와 호환됩니다.
여기에 예시가 있습니다.
JAX 사용:
keras.distribution API를 사용하여 JAX에서 데이터 병렬 및 모델 병렬 분산을 모두 수행할 수 있습니다.
예를 들어, 데이터 병렬 분산을 수행하려면, 다음 코드 조각만 있으면 됩니다.
distribution = keras.distribution.DataParallel(devices=keras.distribution.list_devices())
keras.distribution.set_distribution(distribution)모델 병렬 분포에 대해서는, 다음 가이드를 참조하세요.
jax.sharding과 같은 JAX API를 통해 직접 트레이닝을 분산할 수도 있습니다.
여기에 예시가 있습니다.
Q: 내 커스텀 Keras 레이어를 네이티브 PyTorch Modules 또는 Flax Modules에서 사용할 수 있나요?
Keras API(예: keras.ops 네임스페이스)로만 작성된 경우, 그렇습니다.
Keras 레이어는 네이티브 PyTorch 및 JAX 코드와 함께 바로 작동합니다.
PyTorch에서는 다른 PyTorch Module처럼 Keras 레이어를 사용하면 됩니다.
JAX에서는 stateless 레이어 API인 layer.stateless_call()를 사용해야 합니다.
Q: 앞으로 백엔드를 더 추가하시겠습니까? 프레임워크 XYZ는 어떻습니까?
대상 프레임워크에 사용자 기반이 크거나 다른 고유한 기술적 이점이 있는 한 새로운 백엔드를 추가하는 데 열려 있습니다. 그러나 새로운 백엔드를 추가하고 유지하는 것은 큰 부담이므로 각 새로운 백엔드 후보를 사례별로 신중하게 고려할 것이며, 많은 새로운 백엔드를 추가할 가능성은 없습니다. 아직 잘 확립되지 않은 새로운 프레임워크는 추가하지 않을 것입니다. 현재 Mojo로 작성된 백엔드를 추가하는 것을 고려하고 있습니다. 유용하다고 생각되면 Mojo 팀에 알려주십시오.