하이퍼파라미터 튜닝 과정 시각화
- 원본 링크 : https://keras.io/guides/keras_tuner/visualize_tuning/
- 최종 확인 : 2024-11-19
저자 : Haifeng Jin
생성일 : 2021/06/25
최종 편집일 : 2021/06/05
설명 : TensorBoard 사용하여, KerasTuner에서 하이퍼파라미터 튜닝 과정을 시각화.
!pip install keras-tuner -q소개
KerasTuner는 각 시도에서 하이퍼파라미터의 값을 포함한 로그를 화면에 출력하여, 사용자가 진행 상황을 모니터링할 수 있게 합니다. 그러나 로그만 읽는 것은 하이퍼파라미터가 결과에 미치는 영향을 직관적으로 이해하기에 충분하지 않을 수 있습니다. 따라서, TensorBoard를 사용하여 상호작용 가능한 그림을 통해, 하이퍼파라미터 값과 해당 평가 결과를 시각화하는 방법을 제공합니다.
TensorBoard는 머신 러닝 실험을 시각화하는 데 유용한 도구입니다. 모델 트레이닝 중 손실과 메트릭을 모니터링하고 모델 아키텍처를 시각화할 수 있습니다. KerasTuner를 TensorBoard와 함께 사용하면, HParams 플러그인을 통해 하이퍼파라미터 튜닝 결과를 시각화하는 추가 기능을 제공받을 수 있습니다.
여기서는 KerasTuner와 TensorBoard를 사용하는 방법을 보여주기 위해, MNIST 이미지 분류 데이터셋을 튜닝하는 간단한 예를 사용합니다.
첫 번째 단계는 데이터를 다운로드하고 형식을 지정하는 것입니다.
import numpy as np
import keras_tuner
import keras
from keras import layers
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# 픽셀 값을 [0, 1] 범위로 정규화합니다.
x_train = x_train.astype("float32") / 255
x_test = x_test.astype("float32") / 255
# 이미지에 채널 차원을 추가합니다.
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
# 데이터의 모양을 출력합니다.
print(x_train.shape)
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)결과
(60000, 28, 28, 1)
(60000,)
(10000, 28, 28, 1)
(10000,)그런 다음, build_model 함수를 작성하여,
하이퍼파라미터와 함께 모델을 빌드하고 해당 모델을 반환합니다.
하이퍼파라미터에는 사용할 모델 타입(다층 퍼셉트론(MLP) 또는 컨볼루션 신경망(CNN)),
레이어 수, 유닛 또는 필터의 수, 드롭아웃 사용 여부가 포함됩니다.
def build_model(hp):
inputs = keras.Input(shape=(28, 28, 1))
# 모델 타입은 MLP 또는 CNN일 수 있습니다.
model_type = hp.Choice("model_type", ["mlp", "cnn"])
x = inputs
if model_type == "mlp":
x = layers.Flatten()(x)
# MLP의 레이어 수는 하이퍼파라미터입니다.
for i in range(hp.Int("mlp_layers", 1, 3)):
# 각 레이어의 유닛 수는, 다른 이름을 가진 하이퍼파라미터입니다.
x = layers.Dense(
units=hp.Int(f"units_{i}", 32, 128, step=32),
activation="relu",
)(x)
else:
# CNN의 레이어 수도 하이퍼파라미터입니다.
for i in range(hp.Int("cnn_layers", 1, 3)):
x = layers.Conv2D(
hp.Int(f"filters_{i}", 32, 128, step=32),
kernel_size=(3, 3),
activation="relu",
)(x)
x = layers.MaxPooling2D(pool_size=(2, 2))(x)
x = layers.Flatten()(x)
# 드롭아웃 레이어를 사용할지 여부는 하이퍼파라미터입니다.
if hp.Boolean("dropout"):
x = layers.Dropout(0.5)(x)
# 마지막 레이어는 10개의 유닛을 포함하며, 이는 클래스 수와 동일합니다.
outputs = layers.Dense(units=10, activation="softmax")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
# 모델을 컴파일합니다.
model.compile(
loss="sparse_categorical_crossentropy",
metrics=["accuracy"],
optimizer="adam",
)
return modelCNN과 MLP 모두에 대해 모델이 성공적으로 빌드되는지 확인하기 위해 빠르게 테스트할 수 있습니다.
# `HyperParameters`를 초기화하고 값을 설정합니다.
hp = keras_tuner.HyperParameters()
hp.values["model_type"] = "cnn"
# `HyperParameters`를 사용하여 모델을 빌드합니다.
model = build_model(hp)
# 모델이 데이터에서 실행되는지 테스트합니다.
model(x_train[:100])
# 모델의 요약을 출력합니다.
model.summary()
# MLP 모델에 대해서도 동일하게 실행합니다.
hp.values["model_type"] = "mlp"
model = build_model(hp)
model(x_train[:100])
model.summary()결과
Model: "functional_1"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━┩
│ input_layer (InputLayer) │ (None, 28, 28, 1) │ 0 │
├─────────────────────────────────┼───────────────────────────┼────────────┤
│ conv2d (Conv2D) │ (None, 26, 26, 32) │ 320 │
├─────────────────────────────────┼───────────────────────────┼────────────┤
│ max_pooling2d (MaxPooling2D) │ (None, 13, 13, 32) │ 0 │
├─────────────────────────────────┼───────────────────────────┼────────────┤
│ flatten (Flatten) │ (None, 5408) │ 0 │
├─────────────────────────────────┼───────────────────────────┼────────────┤
│ dense (Dense) │ (None, 10) │ 54,090 │
└─────────────────────────────────┴───────────────────────────┴────────────┘
Total params: 54,410 (212.54 KB)
Trainable params: 54,410 (212.54 KB)
Non-trainable params: 0 (0.00 B)
Model: "functional_3"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━┩
│ input_layer_1 (InputLayer) │ (None, 28, 28, 1) │ 0 │
├─────────────────────────────────┼───────────────────────────┼────────────┤
│ flatten_1 (Flatten) │ (None, 784) │ 0 │
├─────────────────────────────────┼───────────────────────────┼────────────┤
│ dense_1 (Dense) │ (None, 32) │ 25,120 │
├─────────────────────────────────┼───────────────────────────┼────────────┤
│ dense_2 (Dense) │ (None, 10) │ 330 │
└─────────────────────────────────┴───────────────────────────┴────────────┘
Total params: 25,450 (99.41 KB)
Trainable params: 25,450 (99.41 KB)
Non-trainable params: 0 (0.00 B)RandomSearch 튜너를 10번의 시도와 함께 초기화하고,
모델 선택을 위한 지표로 검증 정확도(val_accuracy)를 사용합니다.
tuner = keras_tuner.RandomSearch(
build_model,
max_trials=10,
# 같은 디렉토리에서 이전 검색을 다시 시작하지 않도록 설정합니다.
overwrite=True,
objective="val_accuracy",
# 중간 결과를 저장할 디렉토리를 설정합니다.
directory="/tmp/tb",
)tuner.search(...)를 호출하여 하이퍼파라미터 검색을 시작합니다.
TensorBoard를 사용하려면,
콜백에 keras.callbacks.TensorBoard 인스턴스를 전달해야 합니다.
tuner.search(
x_train,
y_train,
validation_split=0.2,
epochs=2,
# TensorBoard 콜백을 사용합니다.
# 로그는 "/tmp/tb_logs"에 기록됩니다.
callbacks=[keras.callbacks.TensorBoard("/tmp/tb_logs")],
)결과
Trial 10 Complete [00h 00m 06s]
val_accuracy: 0.9617499709129333Best val_accuracy So Far: 0.9837499856948853
Total elapsed time: 00h 08m 32sColab에서 실행 중인 경우, 아래 두 명령어로 TensorBoard를 Colab 내부에서 확인할 수 있습니다.
%load_ext tensorboard
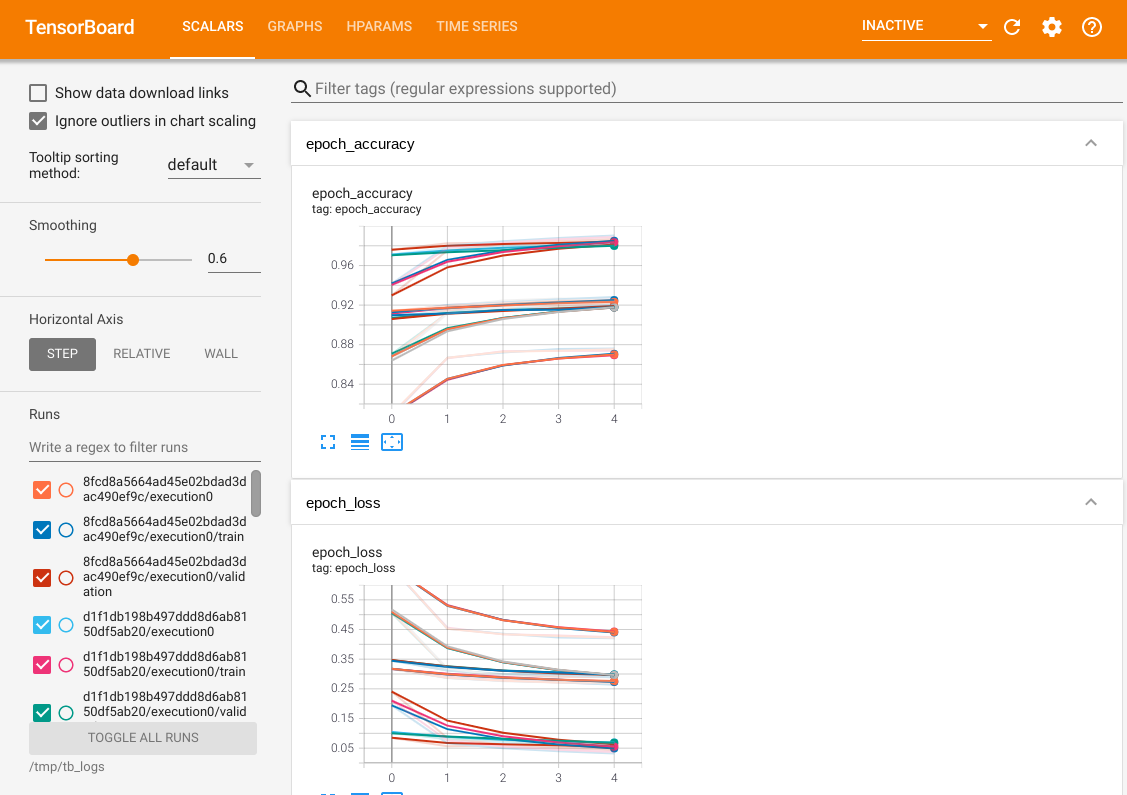
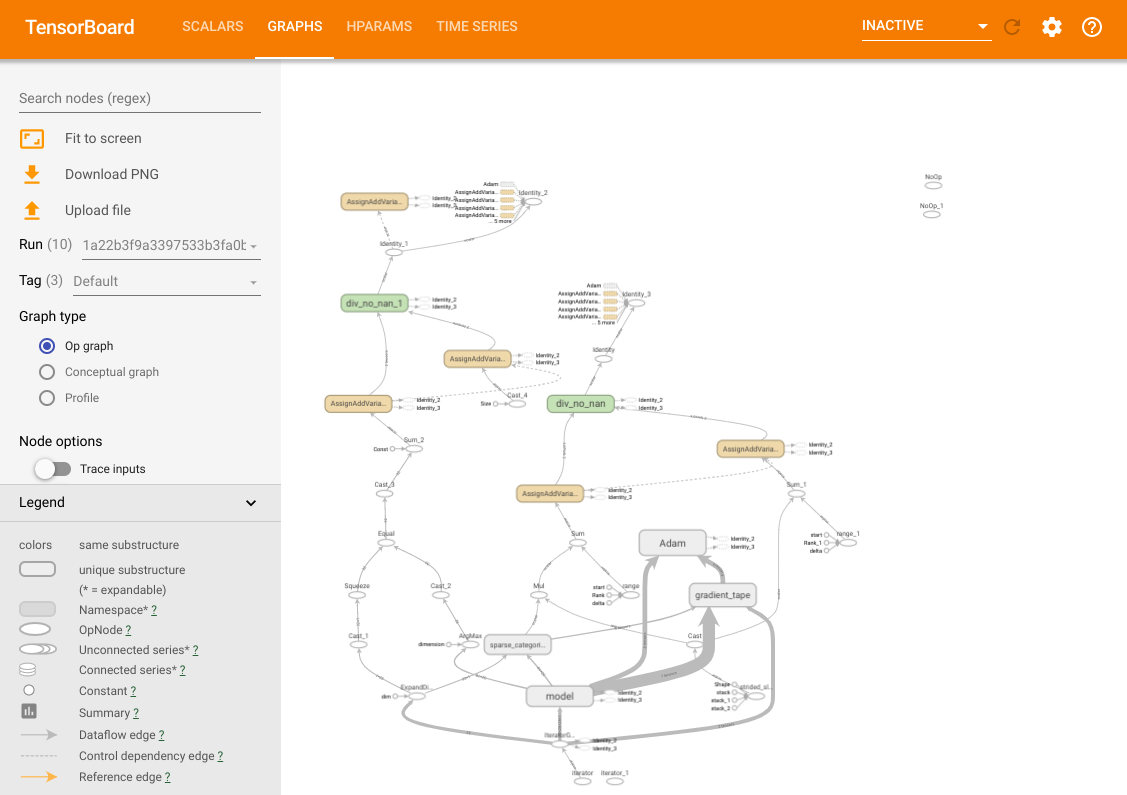
%tensorboard --logdir /tmp/tb_logs모든 일반적인 TensorBoard 기능을 사용할 수 있습니다. 예를 들어, 손실과 메트릭 곡선을 확인하거나, 다양한 시도에서 생성된 모델의 계산 그래프를 시각화할 수 있습니다.
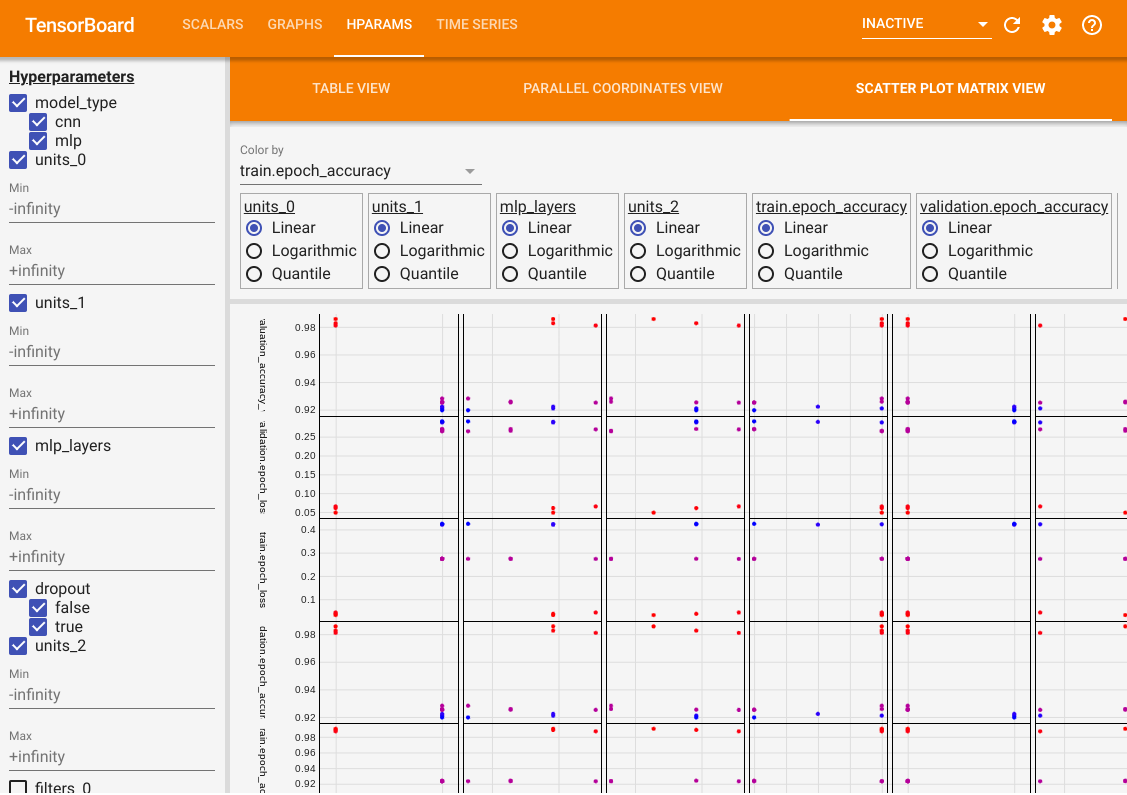
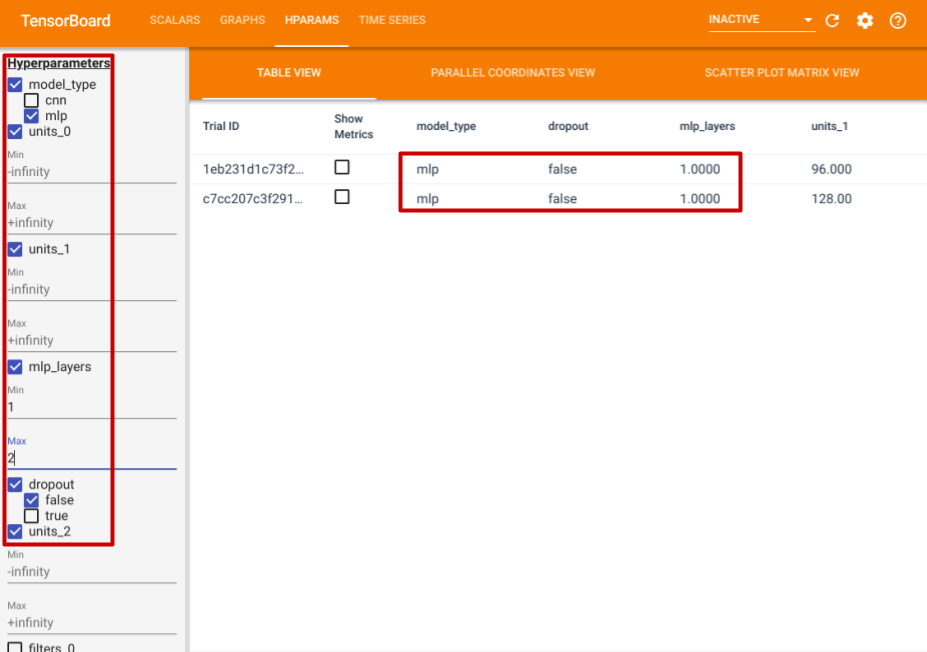
이 기능 외에도 HParams 탭이 있으며, 여기에는 세 가지 뷰가 제공됩니다. 테이블 뷰에서는, 서로 다른 하이퍼파라미터 값과 평가 메트릭을 포함한, 10개의 서로 다른 시도를 테이블 형식으로 확인할 수 있습니다.
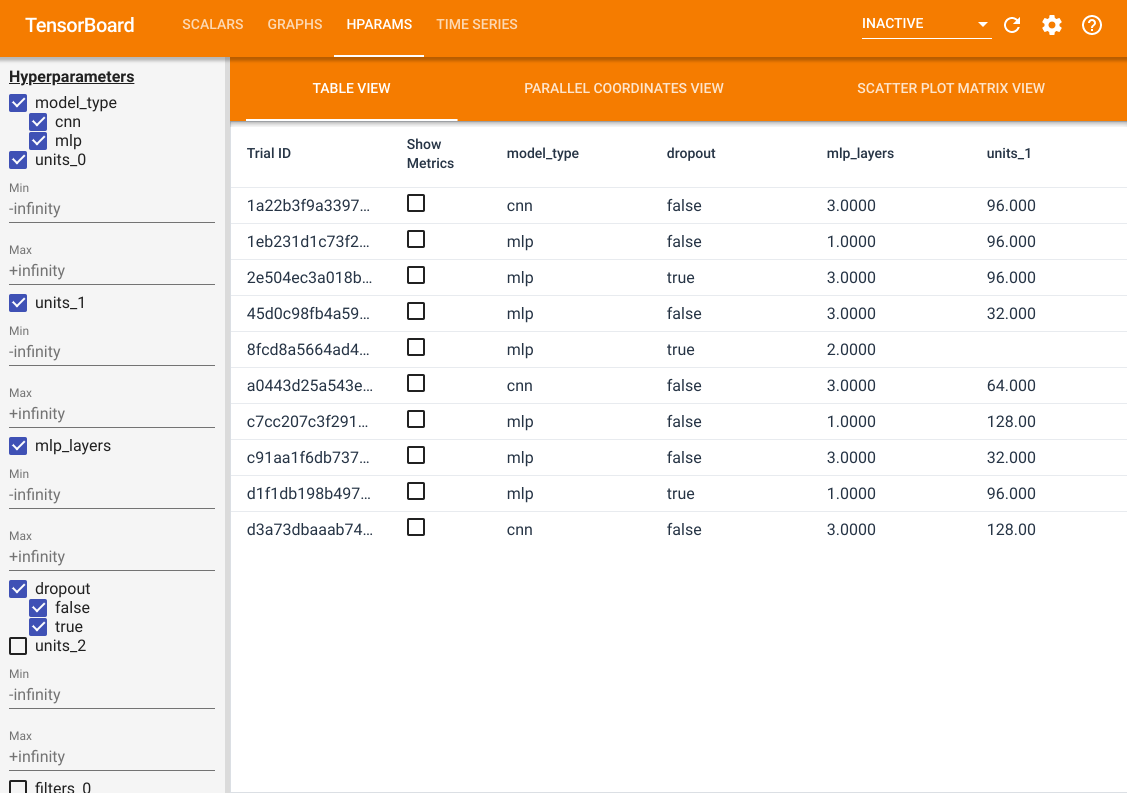
왼쪽에서, 특정 하이퍼파라미터에 대한 필터를 지정할 수 있습니다. 예를 들어, 드롭아웃 레이어가 없는 MLP 모델만 표시하고, 1~2개의 dense 레이어를 가진 모델만 선택할 수 있습니다.
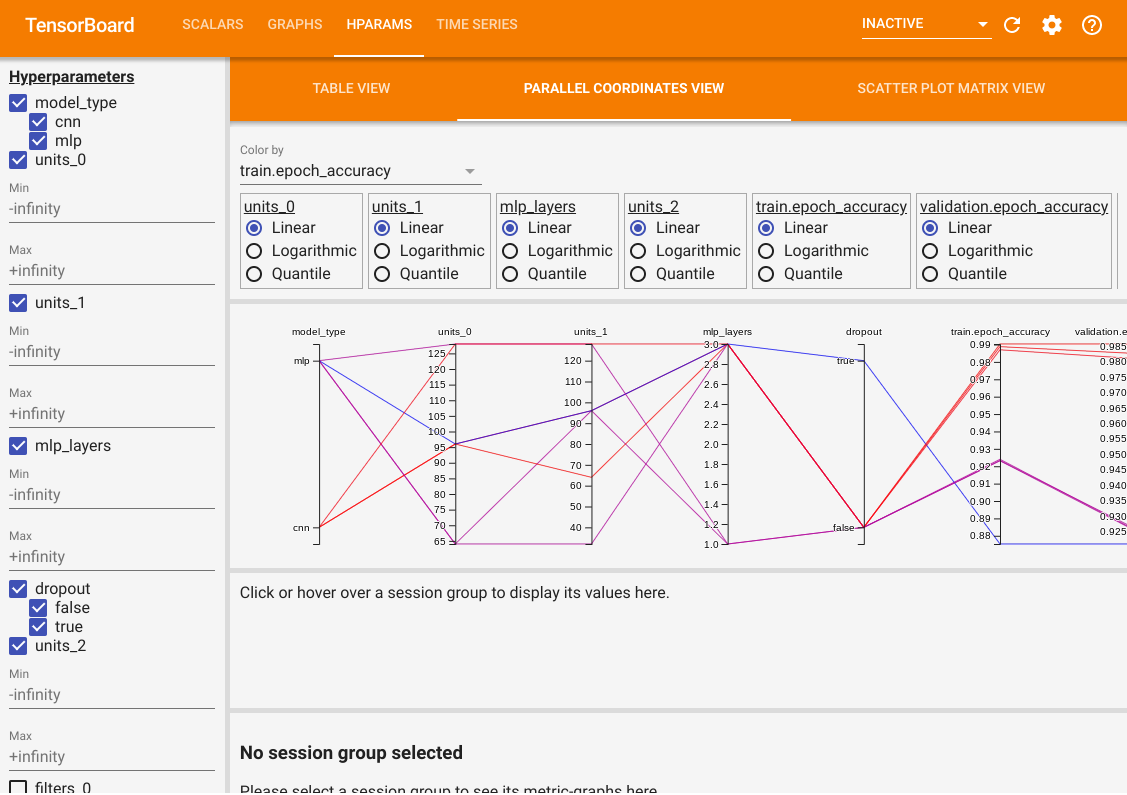
테이블 뷰 외에도, 평행 좌표 뷰(parallel coordinates view)와 산점도 행렬 뷰(scatter plot matrix view)라는 두 가지 추가 뷰를 제공합니다. 동일한 데이터를 다른 방식으로 시각화한 것입니다. 왼쪽 패널을 사용하여 결과를 필터링할 수 있습니다.
평행 좌표 뷰에서는, 각 색상이 다른 시도를 나타냅니다. 축은 하이퍼파라미터와 평가 메트릭을 나타냅니다.
산점도 행렬 뷰에서는, 각 점이 하나의 시도를 나타냅니다. 이 뷰는 하이퍼파라미터와 메트릭을 축으로 하는 평면에 시도 결과를 프로젝션한 것입니다.