KerasNLP 시작하기
- 원본 링크 : https://keras.io/guides/keras_nlp/getting_started/
- 최종 확인 : 2024-11-19
저자 : Jonathan Bischof
생성일 : 2022/12/15
최종 편집일 : 2023/07/01
설명 : KerasNLP API에 대한 소개입니다.
소개
KerasNLP는 전체 개발 주기를 지원하는 자연어 처리 라이브러리입니다. 우리의 워크플로우는 모듈형 구성 요소로 이루어져 있으며, 최첨단 사전 트레이닝된 가중치와 아키텍처를 제공하며, 사용자 필요에 따라 쉽게 커스터마이즈할 수 있습니다.
이 라이브러리는 코어 Keras API의 확장입니다.
모든 높은 레벨 모듈은 Layers 또는 Models입니다.
Keras에 익숙하다면, 축하합니다! 이미 대부분의 KerasNLP를 이해하고 있는 것입니다.
KerasNLP는 Keras 3를 사용하여, TensorFlow, Pytorch, Jax와 함께 작동합니다.
아래 가이드에서는, 모델 트레이닝을 위해 jax 백엔드를 사용하고,
입력 전처리를 효율적으로 처리하기 위해, tf.data를 사용합니다.
하지만, 자유롭게 다른 것을 사용해도 됩니다!
이 가이드는 백엔드를 TensorFlow 또는 PyTorch로 바꿔도 아무런 변경 없이 실행됩니다.
아래 KERAS_BACKEND를 업데이트하기만 하면 됩니다.
이 가이드는 감정 분석 예제를 통해, 모듈식 접근 방식을 여섯 가지 복잡도 레벨에서 보여줍니다:
- 사전 트레이닝된 분류기를 사용한 추론
- 사전 트레이닝된 백본을 미세 조정
- 사용자 제어 전처리로 미세 조정
- 커스텀 모델을 미세 조정
- 백본 모델을 사전 트레이닝
- 처음부터 직접 트랜스포머 모델 빌드 및 트레이닝
가이드 전체에서, 우리는 Keras 공식 마스코트인 Keras 교수(Professor Keras)를 시각적 참조로 사용하여 자료의 복잡성을 설명합니다:
!pip install -q --upgrade keras-nlp
!pip install -q --upgrade keras # Keras 3로 업그레이드.import os
os.environ["KERAS_BACKEND"] = "jax" # 또는 "tensorflow", "torch"
import keras_nlp
import keras
# 이 가이드에서 모든 트레이닝을 가속화하기 위해 혼합 정밀도 사용.
keras.mixed_precision.set_global_policy("mixed_float16")API 빠른 시작
가장 높은 레벨의 API는 keras_nlp.models입니다.
이 심볼들은 문자열을 토큰으로, 토큰을 dense 특성으로,
그리고 dense 특성을 작업별 출력으로 변환하는 전체 과정을 다룹니다.
각 XX 아키텍처(예: Bert)에 대해, 다음 모듈을 제공합니다:
Tokenizer:
keras_nlp.models.XXTokenizer- 기능: 문자열을 토큰 ID 시퀀스로 변환합니다.
- 중요성: 문자열의 raw 바이트는 유용한 특성으로 사용되기엔 차원이 너무 높으므로,
먼저 작은 수의 토큰으로 매핑합니다.
예를 들어,
"The quick brown fox"는["the", "qu", "##ick", "br", "##own", "fox"]로 변환됩니다. - 상속받는 클래스:
keras.layers.Layer.
Preprocessor:
keras_nlp.models.XXPreprocessor- 기능: 문자열을 토큰화로 시작하여, 백본이 사용할 수 있는 전처리된, 텐서 딕셔너리로 변환합니다.
- 중요성: 각 모델은 입력을 이해하기 위해, 구분 기호 토큰과 같은 특수 토큰 및 추가 텐서를 사용합니다. 예를 들어 입력 세그먼트를 구분하거나, 패딩 토큰을 식별하는 기능이 포함됩니다. 모든 시퀀스를 동일한 길이로 패딩하면, 계산 효율성이 높아집니다.
- 구성 요소:
XXTokenizer. - 상속받는 클래스:
keras.layers.Layer.
Backbone:
keras_nlp.models.XXBackbone- 기능: 전처리된 텐서를 dense 특성으로 변환합니다. 문자열 처리는 하지 않으므로, 먼저 전처리기를 호출해야 합니다.
- 중요성: 백본은 입력 토큰을 dense 특성으로 압축하여, 후속 작업에 사용할 수 있도록 합니다. 백본 모델은 일반적으로 대량의 비지도 학습 데이터를 사용하여, 언어 모델링 작업으로 사전 트레이닝된 것입니다. 이러한 정보를 새로운 작업에 전이하는 것은 현대 NLP에서 중요한 돌파구입니다.
- 상속받는 클래스:
keras.Model.
Task: 예를 들어,
keras_nlp.models.XXClassifier- 기능: 문자열을 작업별 출력(예: 분류 확률)으로 변환합니다.
- 중요성: 작업 모델은 문자열 전처리와 백본 모델을 작업별
Layers와 결합하여, 문장 분류, 토큰 분류, 텍스트 생성 등의 문제를 해결합니다. 추가된Layers는 라벨이 지정된 데이터를 사용하여 미세 조정해야 합니다. - 구성 요소:
XXBackbone과XXPreprocessor. - 상속받는 클래스:
keras.Model.
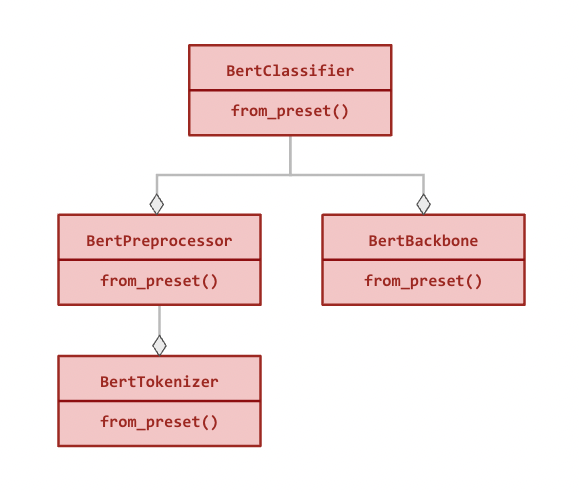
다음은 BertClassifier의 모듈 계층 구조입니다(모든 관계는 구성적 관계입니다):
모든 모듈은 독립적으로 사용할 수 있으며, 사전 설정된 아키텍처와 가중치로 클래스를 인스턴스화하는,
from_preset() 메서드를 갖고 있습니다. (아래 예 참조)
데이터
우리는 IMDB 영화 리뷰의 감정 분석 예시를 사용합니다.
이 작업에서는 텍스트를 사용하여 리뷰가 긍정적(label = 1)인지 부정적(label = 0)인지를 예측합니다.
데이터는 keras.utils.text_dataset_from_directory를 사용하여 로드되며,
이는 강력한 tf.data.Dataset 형식을 이용합니다.
!curl -O https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
!tar -xf aclImdb_v1.tar.gz
!# 비지도 학습 예제 제거
!rm -r aclImdb/train/unsupBATCH_SIZE = 16
imdb_train = keras.utils.text_dataset_from_directory(
"aclImdb/train",
batch_size=BATCH_SIZE,
)
imdb_test = keras.utils.text_dataset_from_directory(
"aclImdb/test",
batch_size=BATCH_SIZE,
)
# 첫 번째 리뷰 확인
# 형식은 (리뷰 텍스트 텐서, 라벨 텐서)
print(imdb_train.unbatch().take(1).get_single_element())결과
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 80.2M 100 80.2M 0 0 88.0M 0 --:--:-- --:--:-- --:--:-- 87.9M
Found 25000 files belonging to 2 classes.
Found 25000 files belonging to 2 classes.
(<tf.Tensor: shape=(), dtype=string, numpy=b'This is a very, very early Bugs Bunny cartoon. As a result, the character is still in a transition period--he is not drawn as elongated as he later was and his voice isn\'t quite right. In addition, the chemistry between Elmer and Bugs is a little unusual. Elmer is some poor sap who buys Bugs from a pet shop--there is no gun or desire on his part to blast the bunny to smithereens! However, despite this, this is still a very enjoyable film. The early Bugs was definitely more sassy and cruel than his later incarnations. In later films, he messed with Elmer, Yosimite Sam and others because they started it--they messed with the rabbit. But, in this film, he is much more like Daffy Duck of the late 30s and early 40s--a jerk who just loves irritating others!! A true "anarchist" instead of the hero of the later cartoons. While this isn\'t among the best Bug Bunny cartoons, it sure is fun to watch and it\'s interesting to see just how much he\'s changed over the years.'>, <tf.Tensor: shape=(), dtype=int32, numpy=1>)사전 트레이닝된 분류기로 추론하기

KerasNLP에서 가장 높은 레벨의 모듈은 태스크입니다.
태스크는 (일반적으로 사전 트레이닝된) 백본 모델과
태스크 특화 레이어들로 구성된
keras.Model입니다.
다음은 keras_nlp.models.BertClassifier를 사용하는 예시입니다.
참고: 출력은 클래스별 로짓입니다.
(예: [0, 0]은 긍정일 확률이 50%임을 나타냅니다)
출력은 이진 분류의 경우 [negative, positive]입니다.
classifier = keras_nlp.models.BertClassifier.from_preset("bert_tiny_en_uncased_sst2")
# 참고: 배치 입력이 필요하므로, 문자열을 iterable로 래핑해야 합니다.
classifier.predict(["I love modular workflows in keras-nlp!"])결과
1/1 ━━━━━━━━━━━━━━━━━━━━ 1s 689ms/step
array([[-1.539, 1.543]], dtype=float16)모든 태스크에는 사전 설정된 전처리, 아키텍처 및 가중치로
keras.Model
인스턴스를 생성하는 from_preset 메서드가 있습니다.
이는 우리가 keras.Model에서 허용하는 모든 형식의 raw 문자열을 전달하고, 태스크에 맞는 출력 값을 받을 수 있음을 의미합니다.
이 특정 프리셋은 "bert_tiny_uncased_en" 백본을 sst2로 파인 튜닝한 모델로,
이는 Rotten Tomatoes 영화 리뷰 감성 분석을 수행한 모델입니다.
데모에서는 tiny 아키텍처를 사용하지만, 더 큰 모델을 사용하면 최신 성능(SoTA)을 얻을 수 있습니다.
BertClassifier에 사용 가능한 모든 태스크별 프리셋은,
models 페이지에서 확인할 수 있습니다.
이제 IMDB 데이터셋에서 분류기를 평가해 봅시다.
여기서 keras.Model.compile를 호출할 필요는 없습니다.
BertClassifier와 같은 모든 태스크 모델은 기본적으로 컴파일된 상태로 제공되므로,
keras.Model.evaluate를 바로 호출할 수 있습니다.
물론, 원한다면 새로운 메트릭을 추가하기 위해, 일반적인 컴파일 방식을 사용할 수 있습니다.
출력 값은 [loss, accuracy]입니다.
classifier.evaluate(imdb_test)결과
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 4s 2ms/step - loss: 0.4610 - sparse_categorical_accuracy: 0.7882
[0.4630218744277954, 0.783519983291626]결과는 78%의 정확도로, 아무런 트레이닝 없이 이 정도 성능을 얻었습니다. 나쁘지 않네요!
사전 트레이닝된 BERT 백본 파인 튜닝

태스크에 맞는 라벨링된 텍스트가 있으면, 커스텀 분류기를 파인 튜닝하여 성능을 향상시킬 수 있습니다. IMDB 리뷰 감성을 예측하려면, Rotten Tomatoes 데이터보다 IMDB 데이터를 사용하는 것이 더 나은 성능을 낼 것입니다. 또한, 많은 태스크에서 관련 사전 트레이닝된 모델이 없을 수도 있습니다. (예: 고객 리뷰 분류(categorizing))
파인 튜닝의 워크플로우는 위와 거의 동일하지만,
전체 분류기 대신 백본 전용 프리셋을 요청하는 차이만 있습니다.
백본 프리셋이 전달되면,
태스크 Model은 태스크에 맞는 레이어들을 무작위로 초기화하고 트레이닝 준비를 합니다.
BertClassifier에 사용 가능한 모든 백본 프리셋은,
models 페이지에서 확인할 수 있습니다.
분류기를 트레이닝하려면, 다른 keras.Model처럼 keras.Model.fit를 사용하면 됩니다.
위에서와 마찬가지로 태스크에 대해, keras.Model.compile을 스킵하고, 컴파일 기본값을 사용할 수 있습니다.
전처리가 포함되어 있으므로, raw 데이터를 바로 전달할 수 있습니다.
classifier = keras_nlp.models.BertClassifier.from_preset(
"bert_tiny_en_uncased",
num_classes=2,
)
classifier.fit(
imdb_train,
validation_data=imdb_test,
epochs=1,
)결과
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 16s 9ms/step - loss: 0.5202 - sparse_categorical_accuracy: 0.7281 - val_loss: 0.3254 - val_sparse_categorical_accuracy: 0.8621
<keras.src.callbacks.history.History at 0x7f281ffc9f90>여기서는 한 번의 트레이닝만으로 검증 정확도가 0.78에서 0.87로 크게 상승하는 것을 볼 수 있습니다.
IMDB 데이터셋이 sst2보다 훨씬 작음에도 불구하고 말이죠.
사용자 제어 전처리로 파인 튜닝

일부 고급 트레이닝 시나리오에서는, 사용자가 전처리를 직접 제어하기를 원할 수 있습니다.
대규모 데이터셋의 경우, 예제를 미리 전처리하여 디스크에 저장하거나,
tf.data.experimental.service를 사용하여 별도의 작업자 풀에서 전처리할 수 있습니다.
또는, 입력을 다루기 위해 커스텀 전처리가 필요한 경우도 있습니다.
태스크 Model 생성자에 preprocessor=None을 전달하여 자동 전처리를 건너뛰거나,
대신 커스텀 BertPreprocessor를 전달할 수 있습니다.
동일한 프리셋에서 전처리 분리하기
각 모델 아키텍처에는 자체 from_preset 생성자가 있는, 병렬 전처리 Layer가 있습니다.
이 Layer에 대해 동일한 프리셋을 사용하면, 태스크와 일치하는 전처리를 반환합니다.
이 워크플로우에서는 tf.data.Dataset.cache()를 사용하여,
fit 시작 전에 전처리를 한 번만 계산하고 그 결과를 캐시한 다음,
3번의 에포크 동안 모델을 트레이닝합니다.
참고: tf.data를 사용하여,
Jax 또는 PyTorch 백엔드에서 전처리를 실행할 수 있습니다.
입력 데이터셋은 트레이닝 중에 백엔드 네이티브 텐서 타입으로 자동 변환됩니다.
실제로 tf.data의
전처리 효율성을 고려할 때,
모든 백엔드에서 이를 사용하는 것이 좋은 관행입니다.
import tensorflow as tf
preprocessor = keras_nlp.models.BertPreprocessor.from_preset(
"bert_tiny_en_uncased",
sequence_length=512,
)
# 전처리를 `map()`을 사용해, 트레이닝 및 테스트 데이터의 각 샘플에 적용합니다.
# 성능을 조정하려면 [`tf.data.AUTOTUNE`](https://www.tensorflow.org/api_docs/python/tf/data/AUTOTUNE)과
# `prefetch()` 옵션을 사용할 수 있습니다.
# 성능 세부 사항은 https://www.tensorflow.org/guide/data_performance에서 확인하세요.
# 참고: `cache()`는 트레이닝 데이터가 CPU 메모리에 맞는 경우에만 호출하세요!
imdb_train_cached = (
imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
)
imdb_test_cached = (
imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
)
classifier = keras_nlp.models.BertClassifier.from_preset(
"bert_tiny_en_uncased", preprocessor=None, num_classes=2
)
classifier.fit(
imdb_train_cached,
validation_data=imdb_test_cached,
epochs=3,
)결과
Epoch 1/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 15s 8ms/step - loss: 0.5194 - sparse_categorical_accuracy: 0.7272 - val_loss: 0.3032 - val_sparse_categorical_accuracy: 0.8728
Epoch 2/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 10s 7ms/step - loss: 0.2871 - sparse_categorical_accuracy: 0.8805 - val_loss: 0.2809 - val_sparse_categorical_accuracy: 0.8818
Epoch 3/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 10s 7ms/step - loss: 0.2134 - sparse_categorical_accuracy: 0.9178 - val_loss: 0.3043 - val_sparse_categorical_accuracy: 0.8790
<keras.src.callbacks.history.History at 0x7f281ffc87f0>세 번의 에포크 후, 우리의 검증 정확도는 0.88로 증가했습니다.
이는 데이터셋의 크기와 모델의 크기에 의해 결정됩니다.
90% 이상의 정확도를 달성하려면, "bert_base_en_uncased"와 같은 더 큰 프리셋을 시도해 보세요.
사용 가능한 모든 백본 프리셋은,
keras.io 모델 페이지에서 확인할 수 있습니다.
커스텀 전처리
커스텀 전처리가 필요한 경우, raw 문자열을 토큰으로 매핑하는 Tokenizer 클래스를 직접 사용할 수 있습니다.
이 클래스에는 사전 트레이닝과 일치하는 어휘를 얻기 위한, from_preset() 생성자가 있습니다.
참고: BertTokenizer는 기본적으로 시퀀스를 패딩하지 않으므로,
출력은 길이가 가변적인 형식으로 나타납니다.
아래의 MultiSegmentPacker는 이러한 가변 길이 시퀀스를
dense 텐서 타입(tf.Tensor
또는 torch.Tensor)으로 패딩 처리합니다.
tokenizer = keras_nlp.models.BertTokenizer.from_preset("bert_tiny_en_uncased")
tokenizer(["I love modular workflows!", "Libraries over frameworks!"])
# 직접 패커를 작성하거나 `Layers` 중 하나를 사용할 수 있습니다.
packer = keras_nlp.layers.MultiSegmentPacker(
start_value=tokenizer.cls_token_id,
end_value=tokenizer.sep_token_id,
# 참고: 이 값은 프리셋의 `sequence_length`보다 길 수 없으며,
# 커스텀 전처리기에는 이를 확인하는 과정이 없습니다!
sequence_length=64,
)
# 이 함수는 텍스트 샘플 `x`와 해당 레이블 `y`를 입력받아,
# 텍스트를 BERT 모델에 적합한 형식으로 변환합니다.
def preprocessor(x, y):
token_ids, segment_ids = packer(tokenizer(x))
x = {
"token_ids": token_ids,
"segment_ids": segment_ids,
"padding_mask": token_ids != 0,
}
return x, y
imdb_train_preprocessed = imdb_train.map(preprocessor, tf.data.AUTOTUNE).prefetch(
tf.data.AUTOTUNE
)
imdb_test_preprocessed = imdb_test.map(preprocessor, tf.data.AUTOTUNE).prefetch(
tf.data.AUTOTUNE
)
# 전처리된 예시 출력
print(imdb_train_preprocessed.unbatch().take(1).get_single_element())결과
({'token_ids': <tf.Tensor: shape=(64,), dtype=int32, numpy=
array([ 101, 2023, 2003, 2941, 2028, 1997, 2026, 5440, 3152,
1010, 1045, 2052, 16755, 2008, 3071, 12197, 2009, 1012,
2045, 2003, 2070, 2307, 3772, 1999, 2009, 1998, 2009,
3065, 2008, 2025, 2035, 1000, 2204, 1000, 3152, 2024,
2137, 1012, 1012, 1012, 1012, 102, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0], dtype=int32)>, 'segment_ids': <tf.Tensor: shape=(64,), dtype=int32, numpy=
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
dtype=int32)>, 'padding_mask': <tf.Tensor: shape=(64,), dtype=bool, numpy=
array([ True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False])>}, <tf.Tensor: shape=(), dtype=int32, numpy=1>)커스텀 모델을 사용한 파인 튜닝
더 고급 응용 프로그램의 경우, 적절한 태스크 Model이 제공되지 않을 수 있습니다.
이 경우, 커스텀 Layer와 함께 사용할 수 있는 백본 Model에 직접 액세스할 수 있으며,
이는 자체 from_preset 생성자를 가지고 있습니다.
자세한 예시는 전이 학습 가이드에서 확인할 수 있습니다.
백본 Model은 자동 전처리를 포함하지 않지만,
이전 워크플로우에서 보여준 것처럼,
동일한 프리셋을 사용하는 일치하는 전처리기와 함께 사용할 수 있습니다.
이번 워크플로우에서는, 백본 모델을 동결하고, 새로운 입력에 맞게, 두 개의 트레이닝 가능한 트랜스포머 레이어를 추가하여 실험합니다.
참고: 우리는 BERT의 시퀀스 출력을 사용하고 있으므로,
pooled_dense 레이어에 대한 경고를 무시할 수 있습니다.
preprocessor = keras_nlp.models.BertPreprocessor.from_preset("bert_tiny_en_uncased")
backbone = keras_nlp.models.BertBackbone.from_preset("bert_tiny_en_uncased")
imdb_train_preprocessed = (
imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
)
imdb_test_preprocessed = (
imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
)
backbone.trainable = False
inputs = backbone.input
sequence = backbone(inputs)["sequence_output"]
for _ in range(2):
sequence = keras_nlp.layers.TransformerEncoder(
num_heads=2,
intermediate_dim=512,
dropout=0.1,
)(sequence)
# [CLS] 토큰 출력을 사용하여 분류
outputs = keras.layers.Dense(2)(sequence[:, backbone.cls_token_index, :])
model = keras.Model(inputs, outputs)
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.AdamW(5e-5),
metrics=[keras.metrics.SparseCategoricalAccuracy()],
jit_compile=True,
)
model.summary()
model.fit(
imdb_train_preprocessed,
validation_data=imdb_test_preprocessed,
epochs=3,
)결과
Model: "functional_1"
┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃
┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩
│ padding_mask │ (None, None) │ 0 │ - │
│ (InputLayer) │ │ │ │
├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
│ segment_ids │ (None, None) │ 0 │ - │
│ (InputLayer) │ │ │ │
├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
│ token_ids │ (None, None) │ 0 │ - │
│ (InputLayer) │ │ │ │
├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
│ bert_backbone_3 │ [(None, 128), │ 4,385,… │ padding_mask[0][0], │
│ (BertBackbone) │ (None, None, │ │ segment_ids[0][0], │
│ │ 128)] │ │ token_ids[0][0] │
├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
│ transformer_encoder │ (None, None, 128) │ 198,272 │ bert_backbone_3[0][… │
│ (TransformerEncode… │ │ │ │
├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
│ transformer_encode… │ (None, None, 128) │ 198,272 │ transformer_encoder… │
│ (TransformerEncode… │ │ │ │
├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
│ get_item_4 │ (None, 128) │ 0 │ transformer_encoder… │
│ (GetItem) │ │ │ │
├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
│ dense (Dense) │ (None, 2) │ 258 │ get_item_4[0][0] │
└─────────────────────┴───────────────────┴─────────┴──────────────────────┘
Total params: 4,782,722 (18.24 MB)
Trainable params: 396,802 (1.51 MB)
Non-trainable params: 4,385,920 (16.73 MB)Epoch 1/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 17s 10ms/step - loss: 0.6208 - sparse_categorical_accuracy: 0.6612 - val_loss: 0.6119 - val_sparse_categorical_accuracy: 0.6758
Epoch 2/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 12s 8ms/step - loss: 0.5324 - sparse_categorical_accuracy: 0.7347 - val_loss: 0.5484 - val_sparse_categorical_accuracy: 0.7320
Epoch 3/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 12s 8ms/step - loss: 0.4735 - sparse_categorical_accuracy: 0.7723 - val_loss: 0.4874 - val_sparse_categorical_accuracy: 0.7742
<keras.src.callbacks.history.History at 0x7f2790170220>이 모델은 BertClassifier 모델에 비해 트레이닝 가능한 파라미터 수가 10%밖에 되지 않지만,
상당히 좋은 정확도를 달성합니다.
캐시된 전처리를 감안해도, 각 트레이닝 단계가 약 1/3의 시간을 소요합니다.
백본 모델 사전 트레이닝

당신의 도메인에서, 대규모 라벨이 없는 데이터셋에 접근할 수 있나요? 이러한 데이터셋의 크기가 BERT, RoBERTa 또는 GPT2와 같은 유명한 백본 모델을 트레이닝시키는 데 사용된 데이터와 유사한 크기(XX+ GiB)인가요? 만약 그렇다면, 도메인에 특화된 사전 트레이닝을 통해 자체 백본 모델을 학습하는 것이 도움이 될 수 있습니다.
NLP 모델은 일반적으로 언어 모델링 작업을 통해 사전 트레이닝되며,
이는 입력 문장에 보이는 단어를 기준으로 가려진 단어를 예측하는 방식입니다.
예를 들어, "The fox [MASK] over the [MASK] dog"라는 입력에서,
모델은 ["jumped", "lazy"]를 예측해야 합니다.
이 모델의 하위 레이어는 백본으로 패키징되어, 새로운 작업과 관련된 레이어와 결합됩니다.
KerasNLP 라이브러리는 SoTA 백본과 토크나이저를 프리셋 없이 처음부터 트레이닝할 수 있도록 지원합니다.
이번 워크플로우에서는, IMDB 리뷰 텍스트를 사용하여 BERT 백본을 사전 학습합니다. 데이터 처리 복잡성을 줄이기 위해, “next sentence prediction” (NSP) 손실을 생략하였으며, 이는 RoBERTa와 같은 이후 모델에서도 제외되었습니다. 자세한 내용은 원본 논문을 복제하는 단계별 가이드를 제공하는, Transformer 사전 트레이닝을 참조하세요.
전처리
# 모든 BERT `en` 모델들은 동일한 어휘집을 사용하므로,
# "bert_tiny_en_uncased"의 전처리기를 재사용합니다.
preprocessor = keras_nlp.models.BertPreprocessor.from_preset(
"bert_tiny_en_uncased",
sequence_length=256,
)
packer = preprocessor.packer
tokenizer = preprocessor.tokenizer
# 일부 입력 토큰을 "[MASK]" 토큰으로 교체하는 keras.Layer
masker = keras_nlp.layers.MaskedLMMaskGenerator(
vocabulary_size=tokenizer.vocabulary_size(),
mask_selection_rate=0.25,
mask_selection_length=64,
mask_token_id=tokenizer.token_to_id("[MASK]"),
unselectable_token_ids=[
tokenizer.token_to_id(x) for x in ["[CLS]", "[PAD]", "[SEP]"]
],
)
def preprocess(inputs, label):
inputs = preprocessor(inputs)
masked_inputs = masker(inputs["token_ids"])
# 마스킹 레이어 출력을 (features, labels, weights)로 분리하여
# keras.Model.fit()에서 사용할 수 있도록 합니다.
features = {
"token_ids": masked_inputs["token_ids"],
"segment_ids": inputs["segment_ids"],
"padding_mask": inputs["padding_mask"],
"mask_positions": masked_inputs["mask_positions"],
}
labels = masked_inputs["mask_ids"]
weights = masked_inputs["mask_weights"]
return features, labels, weights
pretrain_ds = imdb_train.map(preprocess, num_parallel_calls=tf.data.AUTOTUNE).prefetch(
tf.data.AUTOTUNE
)
pretrain_val_ds = imdb_test.map(
preprocess, num_parallel_calls=tf.data.AUTOTUNE
).prefetch(tf.data.AUTOTUNE)
# ID 103은 "masked"된 토큰입니다.
print(pretrain_ds.unbatch().take(1).get_single_element())결과
({'token_ids': <tf.Tensor: shape=(256,), dtype=int32, numpy=
array([ 101, 103, 2332, 103, 1006, 103, 103, 2332, 2370,
1007, 103, 2029, 103, 2402, 2155, 1010, 24159, 2000,
3541, 7081, 1010, 2424, 2041, 2055, 1996, 9004, 4528,
103, 103, 2037, 2188, 103, 1996, 2269, 1006, 8512,
3054, 103, 4246, 1007, 2059, 4858, 1555, 2055, 1996,
23025, 22911, 8940, 2598, 3458, 1996, 25483, 4528, 2008,
2038, 103, 1997, 15218, 1011, 103, 1997, 103, 2505,
3950, 2045, 3310, 2067, 2025, 3243, 2157, 1012, 103,
7987, 1013, 1028, 103, 7987, 1013, 1028, 2917, 103,
1000, 5469, 1000, 103, 103, 2041, 22902, 1010, 23979,
1010, 1998, 1999, 23606, 103, 1998, 4247, 2008, 2126,
2005, 1037, 2096, 1010, 2007, 1996, 103, 5409, 103,
2108, 3054, 3211, 4246, 1005, 1055, 22692, 2836, 1012,
2009, 103, 1037, 2210, 2488, 103, 103, 2203, 1010,
2007, 103, 103, 9599, 1012, 103, 2391, 1997, 2755,
1010, 1996, 2878, 3185, 2003, 2428, 103, 1010, 103,
103, 103, 1045, 2064, 1005, 1056, 3294, 19776, 2009,
1011, 2012, 2560, 2009, 2038, 2242, 2000, 103, 2009,
13432, 1012, 11519, 4637, 4616, 2011, 5965, 1043, 11761,
103, 103, 2004, 103, 7968, 3243, 4793, 11429, 1010,
1998, 8226, 2665, 18331, 1010, 1219, 1996, 4487, 22747,
8004, 12165, 4382, 5125, 103, 3597, 103, 2024, 2025,
2438, 2000, 103, 2417, 21564, 2143, 103, 103, 7987,
1013, 1028, 1026, 103, 1013, 1028, 2332, 2038, 103,
5156, 12081, 2004, 1996, 103, 1012, 1026, 14216, 103,
103, 1026, 7987, 1013, 1028, 184, 2011, 1037, 8297,
2036, 103, 2011, 2984, 103, 1006, 2003, 2009, 2151,
4687, 2008, 2016, 1005, 1055, 2018, 2053, 7731, 103,
103, 2144, 1029, 102], dtype=int32)>, 'segment_ids': <tf.Tensor: shape=(256,), dtype=int32, numpy=
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], dtype=int32)>, 'padding_mask': <tf.Tensor: shape=(256,), dtype=bool, numpy=
array([ True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True])>, 'mask_positions': <tf.Tensor: shape=(64,), dtype=int64, numpy=
array([ 1, 3, 5, 6, 10, 12, 13, 27, 28, 31, 37, 42, 51,
55, 59, 61, 65, 71, 75, 80, 83, 84, 85, 94, 105, 107,
108, 118, 122, 123, 127, 128, 131, 141, 143, 144, 145, 149, 160,
167, 170, 171, 172, 174, 176, 185, 193, 195, 200, 204, 205, 208,
210, 215, 220, 223, 224, 225, 230, 231, 235, 238, 251, 252])>}, <tf.Tensor: shape=(64,), dtype=int32, numpy=
array([ 4459, 6789, 22892, 2011, 1999, 1037, 2402, 2485, 2000,
1012, 3211, 2041, 9004, 4204, 2069, 2607, 3310, 1026,
1026, 2779, 1000, 3861, 4627, 1010, 7619, 5783, 2108,
4152, 2646, 1996, 15958, 14888, 1999, 14888, 2029, 2003,
2339, 1056, 2191, 2011, 11761, 2638, 1010, 1996, 2214,
2004, 14674, 2860, 2428, 1012, 1026, 1028, 7987, 2010,
2704, 7987, 1013, 1028, 2628, 2011, 2856, 12838, 2143,
2147], dtype=int32)>, <tf.Tensor: shape=(64,), dtype=float16, numpy=
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.], dtype=float16)>)사전 트레이닝 모델
# BERT 백본 모델
backbone = keras_nlp.models.BertBackbone(
vocabulary_size=tokenizer.vocabulary_size(),
num_layers=2,
num_heads=2,
hidden_dim=128,
intermediate_dim=512,
)
# 언어 모델링 헤드
mlm_head = keras_nlp.layers.MaskedLMHead(
token_embedding=backbone.token_embedding,
)
inputs = {
"token_ids": keras.Input(shape=(None,), dtype=tf.int32, name="token_ids"),
"segment_ids": keras.Input(shape=(None,), dtype=tf.int32, name="segment_ids"),
"padding_mask": keras.Input(shape=(None,), dtype=tf.int32, name="padding_mask"),
"mask_positions": keras.Input(shape=(None,), dtype=tf.int32, name="mask_positions"),
}
# 인코딩된 토큰 시퀀스
sequence = backbone(inputs)["sequence_output"]
# 각 마스킹된 입력 토큰에 대해 출력 단어 예측.
# 입력 토큰 임베딩을 사용해 인코딩된 벡터에서 어휘 로짓으로 프로젝션합니다.
# 이는 트레이닝 효율성을 향상시키는 것으로 알려져 있습니다.
outputs = mlm_head(sequence, mask_positions=inputs["mask_positions"])
# 사전 트레이닝 모델 정의 및 컴파일
pretraining_model = keras.Model(inputs, outputs)
pretraining_model.summary()
pretraining_model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.AdamW(learning_rate=5e-4),
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
jit_compile=True,
)
# IMDB 데이터셋으로 사전 트레이닝 진행
pretraining_model.fit(
pretrain_ds,
validation_data=pretrain_val_ds,
epochs=3, # 더 높은 정확도를 위해 6으로 증가 가능
)결과
Model: "functional_3"
┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃
┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩
│ mask_positions │ (None, None) │ 0 │ - │
│ (InputLayer) │ │ │ │
├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
│ padding_mask │ (None, None) │ 0 │ - │
│ (InputLayer) │ │ │ │
├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
│ segment_ids │ (None, None) │ 0 │ - │
│ (InputLayer) │ │ │ │
├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
│ token_ids │ (None, None) │ 0 │ - │
│ (InputLayer) │ │ │ │
├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
│ bert_backbone_4 │ [(None, 128), │ 4,385,… │ mask_positions[0][0… │
│ (BertBackbone) │ (None, None, │ │ padding_mask[0][0], │
│ │ 128)] │ │ segment_ids[0][0], │
│ │ │ │ token_ids[0][0] │
├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
│ masked_lm_head │ (None, None, │ 3,954,… │ bert_backbone_4[0][… │
│ (MaskedLMHead) │ 30522) │ │ mask_positions[0][0] │
└─────────────────────┴───────────────────┴─────────┴──────────────────────┘
Total params: 4,433,210 (16.91 MB)
Trainable params: 4,433,210 (16.91 MB)
Non-trainable params: 0 (0.00 B)Epoch 1/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 22s 12ms/step - loss: 5.7032 - sparse_categorical_accuracy: 0.0566 - val_loss: 5.0685 - val_sparse_categorical_accuracy: 0.1044
Epoch 2/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 13s 8ms/step - loss: 5.0701 - sparse_categorical_accuracy: 0.1096 - val_loss: 4.9363 - val_sparse_categorical_accuracy: 0.1239
Epoch 3/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 13s 8ms/step - loss: 4.9607 - sparse_categorical_accuracy: 0.1240 - val_loss: 4.7913 - val_sparse_categorical_accuracy: 0.1417
<keras.src.callbacks.history.History at 0x7f2738299330>사전 트레이닝 후, backbone 서브모델을 저장하여 새로운 작업에 사용하세요!
처음부터 직접 트랜스포머 빌드 및 트레이닝
새로운 트랜스포머 아키텍처를 구현하고 싶으신가요?
KerasNLP 라이브러리는 SoTA(최첨단) 아키텍처를 구축하는 데 사용되는,
모든 낮은 레벨 모듈을 models API에 제공합니다.
여기에는 keras_nlp.tokenizers API가 포함되어 있어,
WordPieceTokenizer, BytePairTokenizer, 또는 SentencePieceTokenizer를 사용하여,
직접 서브워드 토크나이저를 트레이닝할 수 있습니다.
이 워크플로우에서는, IMDB 데이터에 대해 커스텀 토크나이저를 트레이닝하고, 커스텀 트랜스포머 아키텍처로 백본을 설계합니다. 간단하게 하기 위해, 바로 분류 작업에 대해 트레이닝을 진행합니다. 더 자세한 내용이 궁금하신가요? 커스텀 트랜스포머를 프리트레이닝하고 파인튜닝하는 전체 가이드를, keras.io에 작성했습니다.
IMDB 데이터에서 커스텀 어휘 트레이닝
vocab = keras_nlp.tokenizers.compute_word_piece_vocabulary(
imdb_train.map(lambda x, y: x),
vocabulary_size=20_000,
lowercase=True,
strip_accents=True,
reserved_tokens=["[PAD]", "[START]", "[END]", "[MASK]", "[UNK]"],
)
tokenizer = keras_nlp.tokenizers.WordPieceTokenizer(
vocabulary=vocab,
lowercase=True,
strip_accents=True,
oov_token="[UNK]",
)커스텀 토크나이저로 데이터 전처리
packer = keras_nlp.layers.StartEndPacker(
start_value=tokenizer.token_to_id("[START]"),
end_value=tokenizer.token_to_id("[END]"),
pad_value=tokenizer.token_to_id("[PAD]"),
sequence_length=512,
)
def preprocess(x, y):
token_ids = packer(tokenizer(x))
return token_ids, y
imdb_preproc_train_ds = imdb_train.map(
preprocess, num_parallel_calls=tf.data.AUTOTUNE
).prefetch(tf.data.AUTOTUNE)
imdb_preproc_val_ds = imdb_test.map(
preprocess, num_parallel_calls=tf.data.AUTOTUNE
).prefetch(tf.data.AUTOTUNE)
print(imdb_preproc_train_ds.unbatch().take(1).get_single_element())결과
(<tf.Tensor: shape=(512,), dtype=int32, numpy=
array([ 1, 102, 11, 61, 43, 771, 16, 340, 916,
1259, 155, 16, 135, 207, 18, 501, 10568, 344,
16, 51, 206, 612, 211, 232, 43, 1094, 17,
215, 155, 103, 238, 202, 18, 111, 16, 51,
143, 1583, 131, 100, 18, 32, 101, 19, 34,
32, 101, 19, 34, 102, 11, 61, 43, 155,
105, 5337, 99, 120, 6, 1289, 6, 129, 96,
526, 18, 111, 16, 193, 51, 197, 102, 16,
51, 252, 11, 62, 167, 104, 642, 98, 6,
8572, 6, 154, 51, 153, 1464, 119, 3005, 990,
2393, 18, 102, 11, 61, 233, 404, 103, 104,
110, 18, 18, 18, 233, 1259, 18, 18, 18,
154, 51, 659, 16273, 867, 192, 1632, 133, 990,
2393, 18, 32, 101, 19, 34, 32, 101, 19,
34, 96, 110, 2886, 761, 114, 4905, 293, 12337,
97, 2375, 18, 113, 143, 158, 179, 104, 4905,
610, 16, 12585, 97, 516, 725, 18, 113, 323,
96, 651, 146, 104, 207, 17649, 16, 96, 176,
16022, 136, 16, 1414, 136, 18, 113, 323, 96,
2184, 18, 97, 150, 651, 51, 242, 104, 100,
11722, 18, 113, 151, 543, 102, 171, 115, 1081,
103, 96, 222, 18, 18, 18, 18, 102, 659,
1081, 18, 18, 18, 102, 11, 61, 115, 299,
18, 113, 323, 96, 1579, 98, 203, 4438, 2033,
103, 96, 222, 18, 18, 18, 32, 101, 19,
34, 32, 101, 19, 34, 111, 16, 51, 455,
174, 99, 859, 43, 1687, 3330, 99, 104, 1021,
18, 18, 18, 51, 181, 11, 62, 214, 138,
96, 155, 100, 115, 916, 14, 1286, 14, 99,
296, 96, 642, 105, 224, 4598, 117, 1289, 156,
103, 904, 16, 111, 115, 103, 1628, 18, 113,
181, 11, 62, 119, 96, 1054, 155, 16, 111,
156, 14665, 18, 146, 110, 139, 742, 16, 96,
4905, 293, 12337, 97, 7042, 1104, 106, 557, 103,
366, 18, 128, 16, 150, 2446, 135, 96, 960,
98, 96, 4905, 18, 113, 323, 156, 43, 1174,
293, 188, 18, 18, 18, 43, 639, 293, 96,
455, 108, 207, 97, 1893, 99, 1081, 104, 4905,
18, 51, 194, 104, 440, 98, 12337, 99, 7042,
1104, 654, 122, 30, 6, 51, 276, 99, 663,
18, 18, 18, 97, 138, 113, 207, 163, 16,
113, 171, 172, 107, 51, 1027, 113, 6, 18,
32, 101, 19, 34, 32, 101, 19, 34, 104,
110, 171, 333, 10311, 141, 1311, 135, 140, 100,
207, 97, 140, 100, 99, 120, 1632, 18, 18,
18, 97, 210, 11, 61, 96, 6236, 293, 188,
18, 51, 181, 11, 62, 214, 138, 96, 421,
98, 104, 110, 100, 6, 207, 14129, 122, 18,
18, 18, 151, 1128, 97, 1632, 1675, 6, 133,
6, 207, 100, 404, 18, 18, 18, 150, 646,
179, 133, 210, 6, 18, 111, 103, 152, 744,
16, 104, 110, 100, 557, 43, 1120, 108, 96,
701, 382, 105, 102, 260, 113, 194, 18, 18,
18, 2, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0],
dtype=int32)>, <tf.Tensor: shape=(), dtype=int32, numpy=1>)작은 트랜스포머 설계
token_id_input = keras.Input(
shape=(None,),
dtype="int32",
name="token_ids",
)
outputs = keras_nlp.layers.TokenAndPositionEmbedding(
vocabulary_size=len(vocab),
sequence_length=packer.sequence_length,
embedding_dim=64,
)(token_id_input)
outputs = keras_nlp.layers.TransformerEncoder(
num_heads=2,
intermediate_dim=128,
dropout=0.1,
)(outputs)
# "[START]" 토큰을 사용하여 분류
outputs = keras.layers.Dense(2)(outputs[:, 0, :])
model = keras.Model(
inputs=token_id_input,
outputs=outputs,
)
model.summary()결과
Model: "functional_5"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━┩
│ token_ids (InputLayer) │ (None, None) │ 0 │
├─────────────────────────────────┼───────────────────────────┼────────────┤
│ token_and_position_embedding │ (None, None, 64) │ 1,259,648 │
│ (TokenAndPositionEmbedding) │ │ │
├─────────────────────────────────┼───────────────────────────┼────────────┤
│ transformer_encoder_2 │ (None, None, 64) │ 33,472 │
│ (TransformerEncoder) │ │ │
├─────────────────────────────────┼───────────────────────────┼────────────┤
│ get_item_6 (GetItem) │ (None, 64) │ 0 │
├─────────────────────────────────┼───────────────────────────┼────────────┤
│ dense_1 (Dense) │ (None, 2) │ 130 │
└─────────────────────────────────┴───────────────────────────┴────────────┘
Total params: 1,293,250 (4.93 MB)
Trainable params: 1,293,250 (4.93 MB)
Non-trainable params: 0 (0.00 B)트랜스포머를 직접 분류 목표(objective)에 맞춰 트레이닝
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.AdamW(5e-5),
metrics=[keras.metrics.SparseCategoricalAccuracy()],
jit_compile=True,
)
model.fit(
imdb_preproc_train_ds,
validation_data=imdb_preproc_val_ds,
epochs=3,
)결과
Epoch 1/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 8s 4ms/step - loss: 0.7790 - sparse_categorical_accuracy: 0.5367 - val_loss: 0.4420 - val_sparse_categorical_accuracy: 0.8120
Epoch 2/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 5s 3ms/step - loss: 0.3654 - sparse_categorical_accuracy: 0.8443 - val_loss: 0.3046 - val_sparse_categorical_accuracy: 0.8752
Epoch 3/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 5s 3ms/step - loss: 0.2471 - sparse_categorical_accuracy: 0.9019 - val_loss: 0.3060 - val_sparse_categorical_accuracy: 0.8748
<keras.src.callbacks.history.History at 0x7f26d032a4d0>흥미롭게도, 우리가 설계한 커스텀 분류기는 "bert_tiny_en_uncased"를 미세 조정한 성능과 비슷합니다!
90% 이상의 정확도를 달성하고,
사전 트레이닝의 장점을 보기 위해서는 "bert_base_en_uncased"와 같은,
더 큰 프리셋을 사용해야 합니다.