KerasCV에서 Stable Diffusion을 사용한 고성능 이미지 생성
- 원본 링크 : https://keras.io/guides/keras_cv/generate_images_with_stable_diffusion/
- 최종 확인 : 2024-11-19
저자 : fchollet, lukewood, divamgupta
생성일 : 2022/09/25
최종 편집일 : 2022/09/25
설명 : KerasCV의 Stable Diffusion 모델을 사용하여 새로운 이미지를 생성합니다.
개요
이 가이드에서는, stability.ai의 텍스트-이미지 모델인 Stable Diffusion의 KerasCV 구현을 사용하여, 텍스트 프롬프트를 기반으로 새로운 이미지를 생성하는 방법을 보여줍니다.
Stable Diffusion은 강력한 오픈소스 텍스트-이미지 생성 모델입니다. 텍스트 프롬프트에서 이미지를 쉽게 생성할 수 있는 오픈소스 구현이 여러 개 있지만, KerasCV는 몇 가지 뚜렷한 이점을 제공합니다. 여기에는 XLA 컴파일과 혼합 정밀도 지원이 포함되며, 이를 통해 최첨단 생성 속도를 달성합니다.
이 가이드에서는, KerasCV의 Stable Diffusion 구현을 살펴보고, 이러한 강력한 성능 향상을 사용하는 방법을 보여주고, 이러한 향상이 제공하는 성능 이점을 살펴보겠습니다.
참고: torch 백엔드에서 이 가이드를 실행하려면,
모든 곳에서 jit_compile=False를 설정하세요.
Stable Diffusion을 위한 XLA 컴파일은 현재 torch에서 작동하지 않습니다.
시작하려면, 몇 가지 종속성을 설치하고 몇 가지 import를 정리하겠습니다.
!pip install -q --upgrade keras-cv
!pip install -q --upgrade keras # Keras 3으로 업그레이드.import time
import keras_cv
import keras
import matplotlib.pyplot as plt소개
(먼저 주제를 설명한 다음 구현 방법을 보여주는) 대부분 튜토리얼과 달리, 텍스트-이미지 생성은 말하기보다는 보여주기가 더 쉽습니다.
keras_cv.models.StableDiffusion()의 힘을 확인해 보세요.
먼저 모델을 구성합니다.
model = keras_cv.models.StableDiffusion(
img_width=512, img_height=512, jit_compile=False
)결과
By using this model checkpoint, you acknowledge that its usage is subject to the terms of the CreativeML Open RAIL-M license at https://raw.githubusercontent.com/CompVis/stable-diffusion/main/LICENSE다음으로, 프롬프트를 제공합니다.
images = model.text_to_image("photograph of an astronaut riding a horse", batch_size=3)
def plot_images(images):
plt.figure(figsize=(20, 20))
for i in range(len(images)):
ax = plt.subplot(1, len(images), i + 1)
plt.imshow(images[i])
plt.axis("off")
plot_images(images)결과
50/50 ━━━━━━━━━━━━━━━━━━━━ 63s 211ms/step
꽤 놀랍네요!
하지만 이 모델이 할 수 있는 일은 그게 전부가 아닙니다. 좀 더 복잡한 프롬프트를 시도해 보겠습니다.
images = model.text_to_image(
"cute magical flying dog, fantasy art, "
"golden color, high quality, highly detailed, elegant, sharp focus, "
"concept art, character concepts, digital painting, mystery, adventure",
batch_size=3,
)
plot_images(images)결과
50/50 ━━━━━━━━━━━━━━━━━━━━ 10s 209ms/step
가능성은 문자 그대로 무한(또는 적어도 Stable Diffusion의 잠재 매니폴드의 경계까지 확장됩니다)합니다.
잠깐, 이게 어떻게 작동하는 걸까요?
이 시점에서 예상할 수 있는 것과 달리, Stable Diffusion은 실제로 마법으로 실행되지 않습니다. 일종의 “잠재적 확산 모델"입니다. 그것이 무슨 뜻인지 살펴보겠습니다.
super-resolution 이라는 개념에 익숙할 수 있습니다. 딥러닝 모델을 트레이닝하여, 입력 이미지의 노이즈 제거(denoise) 를 수행하고, 이를 통해 고해상도 버전으로 변환할 수 있습니다. 딥러닝 모델은 노이즈가 많고 해상도가 낮은 입력에서, 누락된 정보를 마법처럼 복구하여 이를 수행하지 않습니다. 대신 모델은 트레이닝 데이터 분포를 사용하여 입력이 주어졌을 때, 가장 가능성이 높은 시각적 세부 사항을 환각합니다. super-resolution에 대해 자세히 알아보려면, 다음 Keras.io 튜토리얼을 확인하세요.
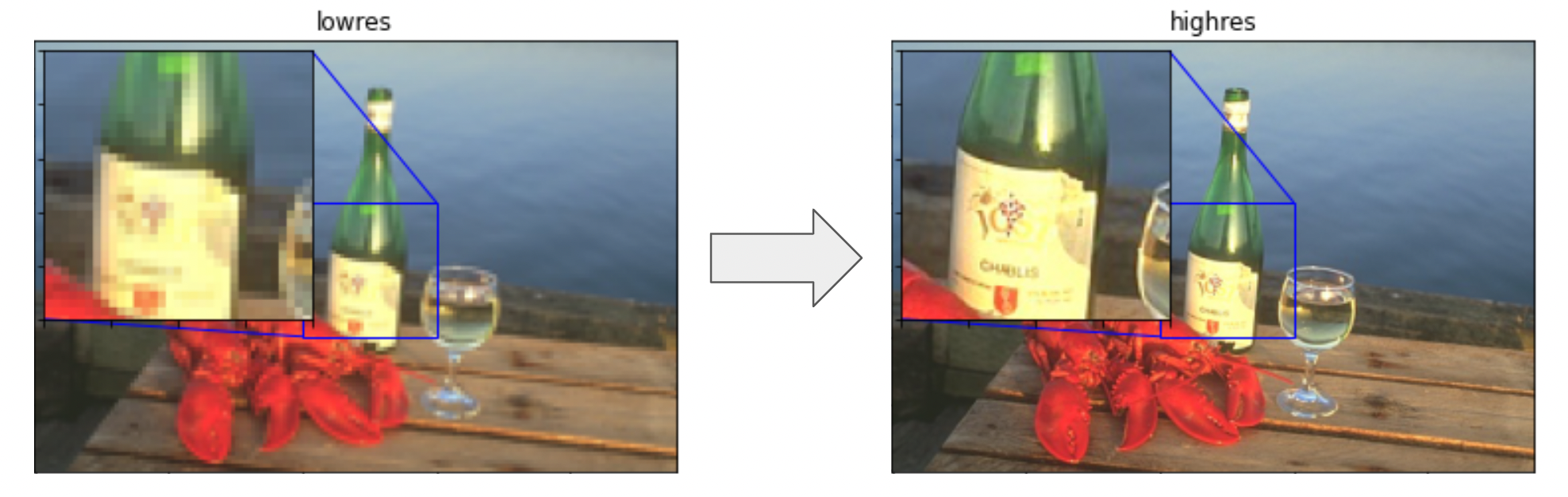
이 아이디어를 한계까지 밀고 나가면, 그냥 순수한 노이즈에 그런 모델을 실행하면 어떨까 하고 생각하게 될 수 있습니다. 그러면, 모델은 “노이즈를 제거하고” 완전히 새로운 이미지를 환각하기 시작할 것입니다. 이 과정을 여러 번 반복하면, 작은 노이즈 패치를 점점 더 선명하고 고해상도의 인공적인 그림으로 바꿀 수 있습니다.
이것은 2020년 잠재 확산(Latent Diffusion) 모델을 사용한 고해상도 이미지 합성에서 제안된, 잠재 확산의 핵심 아이디어입니다. 확산을 심층적으로 이해하려면, Keras.io 튜토리얼 Diffusion 암묵적 모델 노이즈 제거를 확인할 수 있습니다.
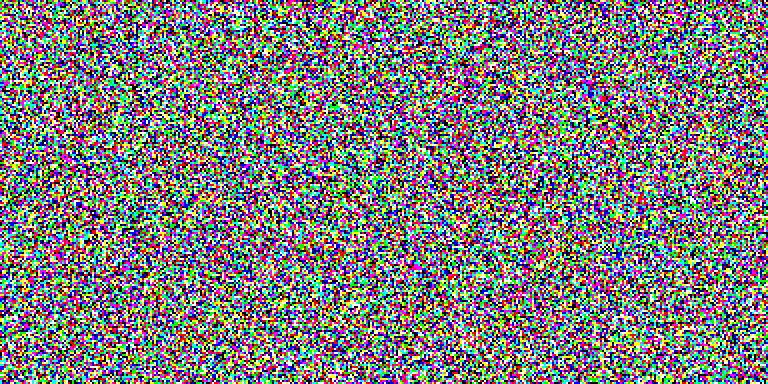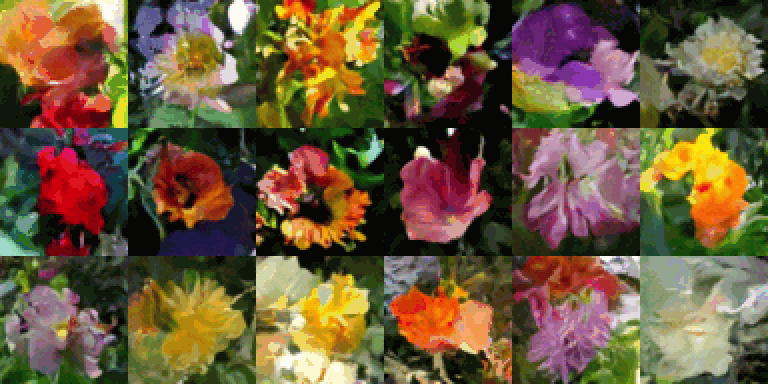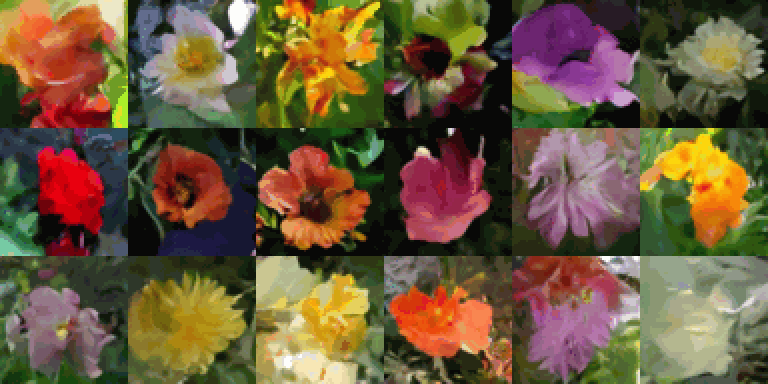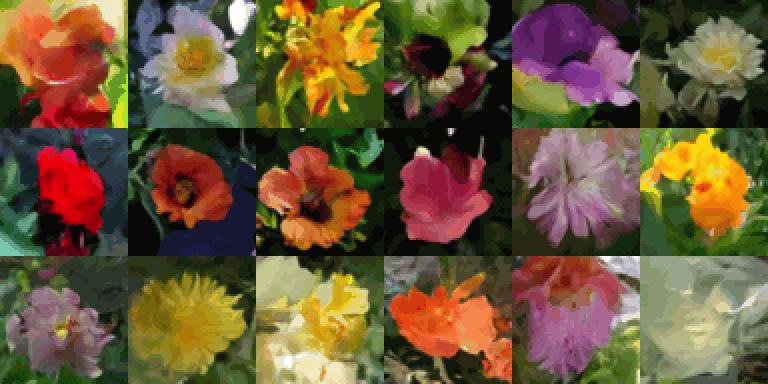
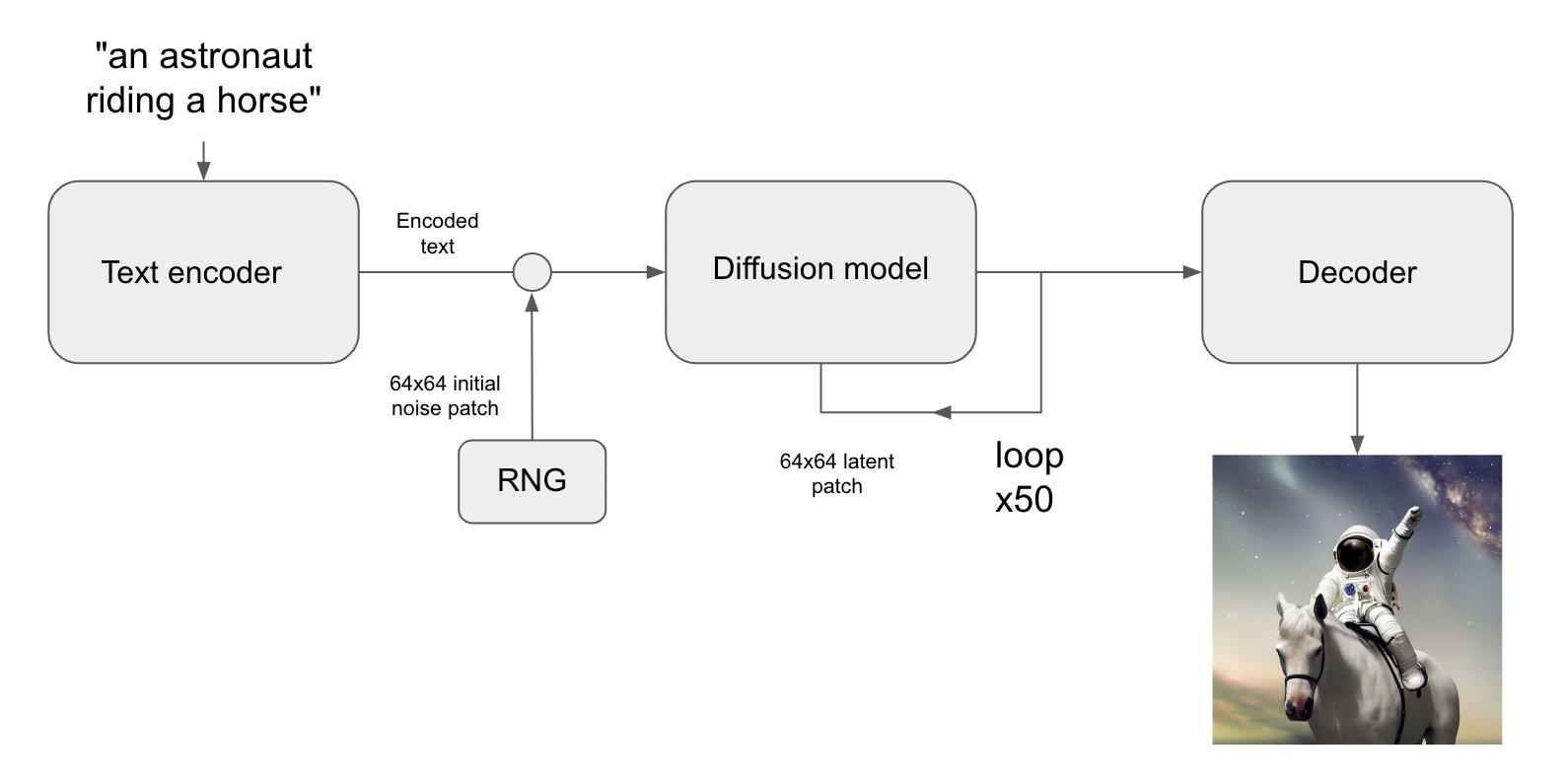
이제, 잠재 확산에서 텍스트-이미지 시스템으로 전환하려면, 여전히 하나의 핵심 기능을 추가해야 합니다. 프롬프트 키워드를 통해 생성된 시각적 콘텐츠를 제어하는 기능입니다. 이는 “컨디셔닝(conditioning)“을 통해 수행됩니다. 이는 노이즈 패치에 텍스트 조각을 나타내는 벡터를 연결(concatenating)한 다음, {image: caption} 쌍의 데이터 세트에 대해 모델을 트레이닝하는, 고전적인 딥러닝 기술입니다.
이를 통해, Stable Diffusion 아키텍처가 탄생했습니다. Stable Diffusion은 세 부분으로 구성됩니다.
- 텍스트 인코더
- 프롬프트를 잠재 벡터로 변환하는 텍스트 인코더.
- 확산 모델
- 64x64 잠재 이미지 패치를 반복적으로 “노이즈 제거"하는 확산 모델.
- 디코더
- 최종 64x64 잠재 패치를 고해상도 512x512 이미지로 변환하는 디코더.
먼저, 텍스트 프롬프트는 텍스트 인코더에 의해 잠재 벡터 공간에 프로젝션됩니다. 텍스트 인코더는 단순히 사전 트레이닝된, 동결된 언어 모델입니다. 그런 다음, 해당 프롬프트 벡터는 무작위로 생성된 노이즈 패치에 연결(concatenated)되고, 이는 일련의 “단계"에 걸쳐 확산 모델에 의해 반복적으로 “노이즈 제거"됩니다. (단계를 많이 실행할수록 이미지가 더 선명하고 좋아집니다. 기본값은 50 단계입니다)
마지막으로, 64x64 잠재 이미지는 디코더를 통해 전송되어, 고해상도로 적절하게 렌더링됩니다.
전반적으로 매우 간단한 시스템입니다. Keras 구현은 총 500줄 미만의 코드를 나타내는 4개의 파일에 들어맞습니다.
- text_encoder.py: 87 LOC
- diffusion_model.py: 181 LOC
- decoder.py: 86 LOC
- stable_diffusion.py: 106 LOC
하지만 이 비교적 간단한 시스템은 수십억 개의 사진과 캡션으로 트레이닝하면 마법처럼 보이기 시작합니다. 파인만이 우주에 대해 말했듯이: “복잡하지 않아, 그저 양이 많을 뿐이야!”
KerasCV의 장점
여러 가지 Stable Diffusion 구현이 공개적으로 제공되고 있는데,
왜 keras_cv.models.StableDiffusion을 사용해야 할까요?
사용하기 쉬운 API 외에도, KerasCV의 Stable Diffusion 모델은 다음과 같은 강력한 장점을 제공합니다.
- 그래프 모드 실행
jit_compile=True를 통한 XLA 컴파일- 혼합 정밀도 계산 지원
이러한 기능을 결합하면, KerasCV Stable Diffusion 모델은 naive 구현보다 훨씬 빠르게 실행됩니다. 이 섹션에서는 이러한 모든 기능을 활성화하는 방법과, 이를 사용하여 얻은 성능 향상을 보여줍니다.
비교를 위해, Stable Diffusion의 HuggingFace 디퓨저 구현의 런타임을 KerasCV 구현과 비교하는 벤치마크를 실행했습니다. 두 구현 모두 각 이미지에 대해 50단계의 스텝 카운트로 3개의 이미지를 생성하도록 했습니다. 이 벤치마크에서는, Tesla T4 GPU를 사용했습니다.
모든 벤치마크는 GitHub에서 오픈 소스이며, Colab에서 다시 실행하여 결과를 재현할 수 있습니다. 벤치마크의 결과는 아래 표에 표시됩니다.
| GPU | 모델 | 실행 시간 |
|---|---|---|
| Tesla T4 | KerasCV (Warm Start) | 28.97s |
| Tesla T4 | diffusers (Warm Start) | 41.33s |
| Tesla V100 | KerasCV (Warm Start) | 12.45 |
| Tesla V100 | diffusers (Warm Start) | 12.72 |
Tesla T4에서 실행 시간이 30% 향상되었습니다! V100에서는 개선 폭이 훨씬 낮지만, 일반적으로 벤치마크 결과는 모든 NVIDIA GPU에 걸쳐 KerasCV를 일관되게 선호할 것으로 예상합니다.
완전성을 위해, 콜드 스타트와 웜 스타트 생성 시간을 모두 보고합니다. 콜드 스타트 실행 시간에는 모델 생성 및 컴파일의 일회성 비용이 포함되므로, 프로덕션 환경(동일한 모델 인스턴스를 여러 번 재사용하는 환경)에서는 무시할 수 있습니다. 그럼에도 불구하고, 콜드 스타트의 숫자는 다음과 같습니다.
| GPU | 모델 | 실행 시간 |
|---|---|---|
| Tesla T4 | KerasCV (Cold Start) | 83.47s |
| Tesla T4 | diffusers (Cold Start) | 46.27s |
| Tesla V100 | KerasCV (Cold Start) | 76.43 |
| Tesla V100 | diffusers (Cold Start) | 13.90 |
이 가이드를 실행한 런타임 결과는 다양할 수 있지만, 우리의 테스트에서 KerasCV의 Stable Diffusion 구현은 PyTorch 대응 제품보다 상당히 빠릅니다. 이는 주로 XLA 컴파일 때문일 수 있습니다.
참고: 각 최적화의 성능 이점은 하드웨어 설정에 따라 상당히 다를 수 있습니다.
시작하려면, 먼저 최적화되지 않은 모델을 벤치마킹해 보겠습니다.
benchmark_result = []
start = time.time()
images = model.text_to_image(
"A cute otter in a rainbow whirlpool holding shells, watercolor",
batch_size=3,
)
end = time.time()
benchmark_result.append(["Standard", end - start])
plot_images(images)
print(f"Standard model: {(end - start):.2f} seconds")
keras.backend.clear_session() # Clear session to preserve memory.결과
50/50 ━━━━━━━━━━━━━━━━━━━━ 10s 209ms/step
Standard model: 10.57 seconds
혼합 정밀도 (Mixed precision)
“혼합 정밀도"는 float32 형식으로 가중치를 저장하는 동안,
float16 정밀도를 사용하여 계산을 수행하는 것으로 구성됩니다.
이는 float16 연산이 최신 NVIDIA GPU에서 float32 대응 연산보다,
훨씬 빠른 커널에 의해 지원된다는 사실을 이용하기 위해 수행됩니다.
Keras에서 혼합 정밀도 계산을 활성화하는 것(따라서 keras_cv.models.StableDiffusion)은,
다음을 호출하는 것만큼 간단합니다.
keras.mixed_precision.set_global_policy("mixed_float16")그게 전부입니다. 상자에서 꺼내자마자, 바로 작동합니다.
model = keras_cv.models.StableDiffusion(jit_compile=False)
print("Compute dtype:", model.diffusion_model.compute_dtype)
print(
"Variable dtype:",
model.diffusion_model.variable_dtype,
)결과
By using this model checkpoint, you acknowledge that its usage is subject to the terms of the CreativeML Open RAIL-M license at https://raw.githubusercontent.com/CompVis/stable-diffusion/main/LICENSE
Compute dtype: float16
Variable dtype: float32위에서 구성한 모델은, 이제 혼합 정밀도 계산을 사용합니다.
즉, 계산을 위해 float16 연산의 속도를 활용하는 동시에,
float32 정밀도로 변수를 저장합니다.
# 벤치마킹을 하기 전에, 그래프 추적을 실행하기 위해 모델을 워밍업합니다.
model.text_to_image("warming up the model", batch_size=3)
start = time.time()
images = model.text_to_image(
"a cute magical flying dog, fantasy art, "
"golden color, high quality, highly detailed, elegant, sharp focus, "
"concept art, character concepts, digital painting, mystery, adventure",
batch_size=3,
)
end = time.time()
benchmark_result.append(["Mixed Precision", end - start])
plot_images(images)
print(f"Mixed precision model: {(end - start):.2f} seconds")
keras.backend.clear_session()결과
50/50 ━━━━━━━━━━━━━━━━━━━━ 42s 132ms/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 6s 129ms/step
Mixed precision model: 6.65 seconds
XLA 컴파일
TensorFlow와 JAX에는 XLA: Accelerated Linear Algebra 컴파일러가 기본 제공됩니다.
keras_cv.models.StableDiffusion는 기본적으로 jit_compile 인수를 지원합니다.
이 인수를 True로 설정하면, XLA 컴파일이 활성화되어 속도가 상당히 향상됩니다.
아래에서 이것을 사용해 보겠습니다.
# 벤치마킹 목적으로 기본값으로 되돌립니다.
keras.mixed_precision.set_global_policy("float32")
model = keras_cv.models.StableDiffusion(jit_compile=True)
# 모델을 벤치마킹하기 전에,
# 추론을 한 번 실행하여,
# TensorFlow 그래프가 이미 추적되었는지 확인합니다.
images = model.text_to_image("An avocado armchair", batch_size=3)
plot_images(images)결과
By using this model checkpoint, you acknowledge that its usage is subject to the terms of the CreativeML Open RAIL-M license at https://raw.githubusercontent.com/CompVis/stable-diffusion/main/LICENSE
50/50 ━━━━━━━━━━━━━━━━━━━━ 48s 209ms/step
XLA 모델을 벤치마킹해 보겠습니다.
start = time.time()
images = model.text_to_image(
"A cute otter in a rainbow whirlpool holding shells, watercolor",
batch_size=3,
)
end = time.time()
benchmark_result.append(["XLA", end - start])
plot_images(images)
print(f"With XLA: {(end - start):.2f} seconds")
keras.backend.clear_session()결과
50/50 ━━━━━━━━━━━━━━━━━━━━ 11s 210ms/step
With XLA: 10.63 seconds
A100 GPU에서는, 약 2배의 속도 향상을 얻습니다. 환상적이죠!
모두 합치기
그렇다면, (2022년 9월 기준으로) 세계에서 가장 성능이 뛰어난, stable diffusion 추론 파이프라인을 어떻게 조립합니까?
다음 두 줄의 코드면 됩니다:
keras.mixed_precision.set_global_policy("mixed_float16")
model = keras_cv.models.StableDiffusion(jit_compile=True)결과
By using this model checkpoint, you acknowledge that its usage is subject to the terms of the CreativeML Open RAIL-M license at https://raw.githubusercontent.com/CompVis/stable-diffusion/main/LICENSE그리고 그것을 사용하려면…
# 모델을 워밍업하는 것을 잊지 마세요.
images = model.text_to_image(
"Teddy bears conducting machine learning research",
batch_size=3,
)
plot_images(images)결과
50/50 ━━━━━━━━━━━━━━━━━━━━ 48s 131ms/step
정확히 얼마나 빠른가요? 알아보죠!
start = time.time()
images = model.text_to_image(
"A mysterious dark stranger visits the great pyramids of egypt, "
"high quality, highly detailed, elegant, sharp focus, "
"concept art, character concepts, digital painting",
batch_size=3,
)
end = time.time()
benchmark_result.append(["XLA + Mixed Precision", end - start])
plot_images(images)
print(f"XLA + mixed precision: {(end - start):.2f} seconds")결과
50/50 ━━━━━━━━━━━━━━━━━━━━ 6s 130ms/step
XLA + mixed precision: 6.66 seconds
결과를 확인해 보겠습니다.
print("{:<22} {:<22}".format("Model", "Runtime"))
for result in benchmark_result:
name, runtime = result
print("{:<22} {:<22}".format(name, runtime))결과
Model Runtime
Standard 10.572920799255371
Mixed Precision 6.651048421859741
XLA 10.632121562957764
XLA + Mixed Precision 6.659237861633301완전히 최적화된 모델은, A100 GPU에서 텍스트 프롬프트로부터 세 개의 새로운 이미지를 생성하는 데 불과 4초가 걸렸습니다.
결론
KerasCV는 Stable Diffusion의 최첨단 구현을 제공하며, XLA와 혼합 정밀도를 사용하여, (2022년 9월 현재) 사용 가능한 가장 빠른 Stable Diffusion 파이프라인을 제공합니다.
일반적으로, keras.io 튜토리얼의 마지막에 학습을 계속할 수 있는 몇 가지 향후 지침을 제공합니다. 이번에는 한 가지 아이디어를 제공합니다.
모델에서 직접 프롬프트를 실행해 보세요! 정말 최고예요!
NVIDIA GPU나 M1 MacBookPro가 있는 경우, 머신에서 로컬로 모델을 실행할 수도 있습니다. (M1 MacBookPro에서 실행할 때는 아직 Apple의 Metal 런타임에서 잘 지원되지 않으므로, 혼합 정밀도를 활성화해서는 안 됩니다.)