KerasCV를 사용하여 강력한 이미지 분류기를 트레이닝
- 원본 링크 : https://keras.io/guides/keras_cv/classification_with_keras_cv/
- 최종 확인 : 2024-11-19
저자 : lukewood
생성일 : 03/28/2023
최종 편집일 : 03/28/2023
설명 : KerasCV를 사용하여 강력한 이미지 분류기를 트레이닝하세요.
분류는 주어진 입력 이미지에 대한 카테고리형 레이블을 예측하는 프로세스입니다. 분류는 비교적 간단한 컴퓨터 비전 작업이지만, 최신 접근 방식은 여전히 여러 복잡한 구성 요소로 구성되어 있습니다. 다행히도, KerasCV는 일반적으로 사용되는 구성 요소를 구성하는 API를 제공합니다.
이 가이드는 세 가지 레벨의 복잡성에서, 이미지 분류 문제를 해결하는 KerasCV의 모듈식 접근 방식을 보여줍니다.
- 사전 트레이닝된 분류기를 사용한 추론
- 사전 트레이닝된 백본 미세 조정
- 처음부터 이미지 분류기 트레이닝
KerasCV는 Keras 3를 사용하여 TensorFlow, PyTorch 또는 Jax로 작동합니다.
아래 가이드에서는 jax 백엔드를 사용합니다.
이 가이드는 변경 사항 없이 TensorFlow 또는 PyTorch 백엔드에서 실행되므로,
아래의 KERAS_BACKEND를 업데이트하기만 하면 됩니다.
공식 Keras 마스코트인 Professor Keras를 자료의 복잡성에 대한 시각적 참조로 사용합니다.
!pip install -q --upgrade keras-cv
!pip install -q --upgrade keras # Keras 3으로 업그레이드하세요.import os
os.environ["KERAS_BACKEND"] = "jax" # @param ["tensorflow", "jax", "torch"]
import json
import math
import numpy as np
import keras
from keras import losses
from keras import ops
from keras import optimizers
from keras.optimizers import schedules
from keras import metrics
import keras_cv
# [`tf.data`](https://www.tensorflow.org/api_docs/python/tf/data) 및
# 해당 전처리 함수를 위해 tensorflow를 import 합니다.
import tensorflow as tf
import tensorflow_datasets as tfds사전 트레이닝된 분류기를 사용한 추론

가장 간단한 KerasCV API인 사전 트레이닝된 분류기로 시작해 보겠습니다. 이 예에서는, ImageNet 데이터 세트에 대해 사전 트레이닝된 분류기를 구성합니다. 이 모델을 사용하여 오래된 “Cat or Dog” 문제를 해결합니다.
KerasCV의 가장 높은 레벨의 모듈은 task 입니다.
task 는 (일반적으로 사전 트레이닝된) 백본 모델과 작업별 레이어로 구성된
keras.Model입니다.
다음은 EfficientNetV2B0 백본과 함께 keras_cv.models.ImageClassifier를 사용하는 예입니다.
EfficientNetV2B0은 이미지 분류 파이프라인을 구성할 때 좋은 시작 모델입니다. 이 아키텍처는 7M의 매개변수 수를 사용하면서도 높은 정확도를 달성합니다. EfficientNetV2B0가 해결하고자 하는 작업에 충분히 강력하지 않다면, KerasCV의 다른 사용 가능한 백본을 확인하세요!
classifier = keras_cv.models.ImageClassifier.from_preset(
"efficientnetv2_b0_imagenet_classifier"
)이전 keras.applications API에서 약간 차이가 있음을 알 수 있습니다.
이전 API에서는 EfficientNetV2B0(weights="imagenet")로 클래스를 구성했습니다.
이전 API는 분류에 매우 좋았지만, 객체 감지 및 시맨틱 세그멘테이션과 같이,
복잡한 아키텍처가 필요한 다른 사용 사례에는 효과적으로 확장되지 않았습니다.
이제 분류기가 구축되었으니, 이 귀여운 고양이 사진에 적용해 보겠습니다!
filepath = keras.utils.get_file(origin="https://i.imgur.com/9i63gLN.jpg")
image = keras.utils.load_img(filepath)
image = np.array(image)
keras_cv.visualization.plot_image_gallery(
np.array([image]), rows=1, cols=1, value_range=(0, 255), show=True, scale=4
)
다음으로, 분류기로부터 몇 가지 예측을 얻어 보겠습니다.
predictions = classifier.predict(np.expand_dims(image, axis=0))결과
1/1 ━━━━━━━━━━━━━━━━━━━━ 4s 4s/step예측은 소프트맥스된 카테고리 순위의 형태로 제공됩니다. 간단한 argsort 함수를 사용하여, 상위 클래스의 인덱스를 찾을 수 있습니다.
top_classes = predictions[0].argsort(axis=-1)클래스 매핑을 디코딩하기 위해, 카테고리 인덱스에서 ImageNet 클래스 이름으로 매핑을 구성할 수 있습니다. 편의상, ImageNet 클래스 매핑을 GitHub gist에 저장했습니다. 지금 다운로드하여 로드해 보겠습니다.
classes = keras.utils.get_file(
origin="https://gist.githubusercontent.com/LukeWood/62eebcd5c5c4a4d0e0b7845780f76d55/raw/fde63e5e4c09e2fa0a3436680f436bdcb8325aac/ImagenetClassnames.json"
)
with open(classes, "rb") as f:
classes = json.load(f)결과
Downloading data from https://gist.githubusercontent.com/LukeWood/62eebcd5c5c4a4d0e0b7845780f76d55/raw/fde63e5e4c09e2fa0a3436680f436bdcb8325aac/ImagenetClassnames.json
33567/33567 ━━━━━━━━━━━━━━━━━━━━ 0s 0us/step이제 우리는 인덱스를 통해 간단히 클래스 이름을 조회할 수 있습니다.
top_two = [classes[str(i)] for i in top_classes[-2:]]
print("Top two classes are:", top_two)결과
Top two classes are: ['Egyptian cat', 'velvet']좋습니다! 둘 다 맞는 것 같습니다! 하지만 클래스 중 하나는 “Velvet"입니다. 우리는 Cats VS Dogs를 분류하려고 합니다. 벨벳 담요는 신경 쓰지 않습니다!
이상적으로는, 이미지가 고양이인지 개인지 판별하기 위한 계산만 수행하고, 모든 리소스를 이 작업에 전념하는 분류기를 갖게 될 것입니다. 이는 우리 자신의 분류기를 미세 조정하여 해결할 수 있습니다.
사전 트레이닝된 분류기 미세 조정

작업에 특화된 레이블이 지정된 이미지가 있는 경우, 커스텀 분류기를 미세 조정하면 성능이 향상될 수 있습니다. Cats vs Dogs 분류기를 트레이닝하려면, 명시적으로 레이블이 지정된 Cat vs Dog 데이터를 사용하면, 일반 분류기보다 성능이 더 좋아야 합니다! 많은 작업의 경우, 관련 사전 트레이닝된 모델을 사용할 수 없습니다. (예: 당신의 애플리케이션에 특화된 이미지 분류)
먼저 데이터를 로드하여 시작해 보겠습니다.
BATCH_SIZE = 32
IMAGE_SIZE = (224, 224)
AUTOTUNE = tf.data.AUTOTUNE
tfds.disable_progress_bar()
data, dataset_info = tfds.load("cats_vs_dogs", with_info=True, as_supervised=True)
train_steps_per_epoch = dataset_info.splits["train"].num_examples // BATCH_SIZE
train_dataset = data["train"]
num_classes = dataset_info.features["label"].num_classes
resizing = keras_cv.layers.Resizing(
IMAGE_SIZE[0], IMAGE_SIZE[1], crop_to_aspect_ratio=True
)
def preprocess_inputs(image, label):
image = tf.cast(image, tf.float32)
# 데이터 세트를 한 번만 반복하므로 이미지 크기를 정적으로 조정합니다.
return resizing(image), tf.one_hot(label, num_classes)
# 배치의 다양성을 높이기 위해 데이터 세트를 셔플합니다.
# 10*BATCH_SIZE는 더 큰 머신이 더 큰 셔플 버퍼를 처리할 수 있다는 가정을 따릅니다.
train_dataset = train_dataset.shuffle(
10 * BATCH_SIZE, reshuffle_each_iteration=True
).map(preprocess_inputs, num_parallel_calls=AUTOTUNE)
train_dataset = train_dataset.batch(BATCH_SIZE)
images = next(iter(train_dataset.take(1)))[0]
keras_cv.visualization.plot_image_gallery(images, value_range=(0, 255))

야옹!
다음으로 모델을 구성해 보겠습니다. 사전 설정 이름에 imagenet을 사용한 것은, 백본이 ImageNet 데이터 세트에 대해 사전 트레이닝되었음을 나타냅니다. 사전 트레이닝된 백본은 잠재적으로 훨씬 더 큰 데이터 세트에서 추출한 패턴을 활용하여, 레이블이 지정된 예제에서 더 많은 정보를 추출합니다.
다음으로 분류기를 구성해 보겠습니다.
model = keras_cv.models.ImageClassifier.from_preset(
"efficientnetv2_b0_imagenet", num_classes=2
)
model.compile(
loss="categorical_crossentropy",
optimizer=keras.optimizers.SGD(learning_rate=0.01),
metrics=["accuracy"],
)결과
Downloading data from https://storage.googleapis.com/keras-cv/models/efficientnetv2b0/imagenet/classification-v0-notop.h5
24029184/24029184 ━━━━━━━━━━━━━━━━━━━━ 1s 0us/step여기서 우리의 분류기는 단순한 keras.Sequential입니다.
남은 것은 model.fit()를 호출하는 것뿐입니다.
model.fit(train_dataset)결과
216/727 ━━━━━[37m━━━━━━━━━━━━━━━ 15s 30ms/step - accuracy: 0.8433 - loss: 0.5113
Corrupt JPEG data: 99 extraneous bytes before marker 0xd9
254/727 ━━━━━━[37m━━━━━━━━━━━━━━ 14s 30ms/step - accuracy: 0.8535 - loss: 0.4941
Warning: unknown JFIF revision number 0.00
266/727 ━━━━━━━[37m━━━━━━━━━━━━━ 14s 30ms/step - accuracy: 0.8563 - loss: 0.4891
Corrupt JPEG data: 396 extraneous bytes before marker 0xd9
310/727 ━━━━━━━━[37m━━━━━━━━━━━━ 12s 30ms/step - accuracy: 0.8651 - loss: 0.4719
Corrupt JPEG data: 162 extraneous bytes before marker 0xd9
358/727 ━━━━━━━━━[37m━━━━━━━━━━━ 11s 30ms/step - accuracy: 0.8729 - loss: 0.4550
Corrupt JPEG data: 252 extraneous bytes before marker 0xd9
Corrupt JPEG data: 65 extraneous bytes before marker 0xd9
374/727 ━━━━━━━━━━[37m━━━━━━━━━━ 10s 30ms/step - accuracy: 0.8752 - loss: 0.4497
Corrupt JPEG data: 1403 extraneous bytes before marker 0xd9
534/727 ━━━━━━━━━━━━━━[37m━━━━━━ 5s 30ms/step - accuracy: 0.8921 - loss: 0.4056
Corrupt JPEG data: 214 extraneous bytes before marker 0xd9
636/727 ━━━━━━━━━━━━━━━━━[37m━━━ 2s 30ms/step - accuracy: 0.8993 - loss: 0.3837
Corrupt JPEG data: 2226 extraneous bytes before marker 0xd9
654/727 ━━━━━━━━━━━━━━━━━[37m━━━ 2s 30ms/step - accuracy: 0.9004 - loss: 0.3802
Corrupt JPEG data: 128 extraneous bytes before marker 0xd9
668/727 ━━━━━━━━━━━━━━━━━━[37m━━ 1s 30ms/step - accuracy: 0.9012 - loss: 0.3775
Corrupt JPEG data: 239 extraneous bytes before marker 0xd9
704/727 ━━━━━━━━━━━━━━━━━━━[37m━ 0s 30ms/step - accuracy: 0.9032 - loss: 0.3709
Corrupt JPEG data: 1153 extraneous bytes before marker 0xd9
712/727 ━━━━━━━━━━━━━━━━━━━[37m━ 0s 30ms/step - accuracy: 0.9036 - loss: 0.3695
Corrupt JPEG data: 228 extraneous bytes before marker 0xd9
727/727 ━━━━━━━━━━━━━━━━━━━━ 69s 62ms/step - accuracy: 0.9045 - loss: 0.3667
<keras.src.callbacks.history.History at 0x7fce380df100>미세 조정 후 모델이 어떻게 수행되는지 살펴보겠습니다.
predictions = model.predict(np.expand_dims(image, axis=0))
classes = {0: "cat", 1: "dog"}
print("Top class is:", classes[predictions[0].argmax()])결과
1/1 ━━━━━━━━━━━━━━━━━━━━ 3s 3s/step
Top class is: cat훌륭하네요. 모델이 이미지를 올바르게 분류한 것 같습니다.
처음부터 분류기 트레이닝

이제 분류에 대해 자세히 알아보았으니, 마지막 과제를 하나 해보겠습니다. 분류 모델을 처음부터 트레이닝하는 것입니다! 이미지 분류의 표준 벤치마크는 ImageNet 데이터 세트이지만, 라이선스 제약으로 인해 이 튜토리얼에서는 CalTech 101 이미지 분류 데이터 세트를 사용합니다. 이 가이드에서는 더 간단한 CalTech 101 데이터 세트를 사용하지만, ImageNet에서는 동일한 트레이닝 템플릿을 사용하여 최신 수준에 가까운 점수를 얻을 수 있습니다.
데이터 로딩부터 시작해 보겠습니다.
NUM_CLASSES = 101
# 완전히 트레이닝하려면 에포크를 100~로 변경하세요.
EPOCHS = 1
def package_inputs(image, label):
return {"images": image, "labels": tf.one_hot(label, NUM_CLASSES)}
train_ds, eval_ds = tfds.load(
"caltech101", split=["train", "test"], as_supervised="true"
)
train_ds = train_ds.map(package_inputs, num_parallel_calls=tf.data.AUTOTUNE)
eval_ds = eval_ds.map(package_inputs, num_parallel_calls=tf.data.AUTOTUNE)
train_ds = train_ds.shuffle(BATCH_SIZE * 16)결과
Downloading and preparing dataset 125.64 MiB (download: 125.64 MiB, generated: 132.86 MiB, total: 258.50 MiB) to /usr/local/google/home/rameshsampath/tensorflow_datasets/caltech101/3.0.1...
Dataset caltech101 downloaded and prepared to /usr/local/google/home/rameshsampath/tensorflow_datasets/caltech101/3.0.1. Subsequent calls will reuse this data.CalTech101 데이터 세트는 각 이미지의 크기가 다르기 때문에,
ragged_batch() API를 사용하여 각 개별 이미지의 모양 정보를 유지하면서 이를 배치 처리합니다.
train_ds = train_ds.ragged_batch(BATCH_SIZE)
eval_ds = eval_ds.ragged_batch(BATCH_SIZE)
batch = next(iter(train_ds.take(1)))
image_batch = batch["images"]
label_batch = batch["labels"]
keras_cv.visualization.plot_image_gallery(
image_batch.to_tensor(),
rows=3,
cols=3,
value_range=(0, 255),
show=True,
)
데이터 보강
이전 미세 조정 예제에서, 정적 크기 조정 작업을 수행했으며 이미지 보강을 활용하지 않았습니다. 그 이유는 트레이닝 세트에 대한 단일 패스로 적절한 결과를 얻기에 충분했기 때문입니다. 더 어려운 작업을 해결하기 위해, 트레이닝할 때는 데이터 파이프라인에 데이터 보강을 포함해야 합니다.
데이터 보강은 조명(lighting), 자르기(cropping), 방향(orientation)과 같은,
입력 데이터의 변경에 대해 모델을 견고하게 만드는 기술입니다.
KerasCV에는 keras_cv.layers API에서 가장 유용한 보강 중 일부가 포함되어 있습니다.
보강의 최적 파이프라인을 만드는 것은 예술이지만,
이 가이드의 이 섹션에서는 분류에 대한 모범 사례에 대한 몇 가지 팁을 제공합니다.
이미지 데이터 보강에 주의해야 할 한 가지 주의 사항은, 보강된 데이터 분포를 원래 데이터 분포에서 너무 멀리 옮기지 않도록 주의해야 한다는 것입니다. 목표는 과적합을 방지하고 일반화를 증가시키는 것이지만, 데이터 분포에서 완전히 벗어난 샘플은 단순히 트레이닝 과정에 노이즈를 추가합니다.
사용할 첫 번째 보강은 RandomFlip입니다. 이 보강은 예상한 대로 동작합니다.
즉, 이미지를 뒤집거나 뒤집지 않습니다.
이 보강은 CalTech101 및 ImageNet에서 유용하지만,
데이터 분포가 수직 거울 불변이 아닌 작업에는 사용해서는 안 됩니다.
이런 일이 발생하는 데이터 세트의 예로는 MNIST 손으로 쓴 숫자가 있습니다.
수직 축에서 6을 뒤집으면, 숫자가 6보다는 7처럼 보이지만, 레이블에는 여전히 6이 표시됩니다.
random_flip = keras_cv.layers.RandomFlip()
augmenters = [random_flip]
image_batch = random_flip(image_batch)
keras_cv.visualization.plot_image_gallery(
image_batch.to_tensor(),
rows=3,
cols=3,
value_range=(0, 255),
show=True,
)
이미지의 절반이 뒤집혔습니다!
우리가 사용할 다음 보강은 RandomCropAndResize입니다.
이 작업은 이미지의 무작위 하위 집합을 선택한 다음, 제공된 대상 크기로 크기를 조정합니다.
이 보강을 사용하면, 분류기가 공간적으로 불변이 되도록 강제합니다.
또한 이 레이어는 이미지의 종횡비를 왜곡하는 데 사용할 수 있는 aspect_ratio_factor를 허용합니다.
이렇게 하면, 모델 성능이 향상될 수 있지만 주의해서 사용해야 합니다.
종횡비 왜곡으로 인해 샘플이 원래 트레이닝 세트의 데이터 분포에서 너무 멀리 이동하기 쉽습니다. 기억하세요.
데이터 보강의 목표는 트레이닝 세트의 데이터 분포와 일치하는 더 많은 트레이닝 샘플을 생성하는 것입니다!
RandomCropAndResize는 또한
tf.RaggedTensor
입력을 처리할 수 있습니다.
CalTech101 이미지 데이터 세트에서 이미지는 다양한 크기로 제공됩니다.
따라서, 밀집된 트레이닝 배치로 쉽게 배치할 수 없습니다.
다행히도 RandomCropAndResize가 Ragged -> Dense 변환 프로세스를 처리합니다!
보강 세트에 RandomCropAndResize를 추가해 보겠습니다.
crop_and_resize = keras_cv.layers.RandomCropAndResize(
target_size=IMAGE_SIZE,
crop_area_factor=(0.8, 1.0),
aspect_ratio_factor=(0.9, 1.1),
)
augmenters += [crop_and_resize]
image_batch = crop_and_resize(image_batch)
keras_cv.visualization.plot_image_gallery(
image_batch,
rows=3,
cols=3,
value_range=(0, 255),
show=True,
)
좋습니다! 이제 dense 이미지 배치로 작업합니다. 다음으로, 트레이닝 세트에 공간(spatial) 및 색상 기반 지터(color-based jitter)를 포함하겠습니다. 그러면, 조명 깜빡임, 그림자 등에 견고한 분류기를 생성할 수 있습니다.
색상과 공간적 특징을 변경하여 이미지를 보강하는 방법은 무한하지만,
아마도 가장 실전에서 검증된 기술은 RandAugment일 것입니다.
RandAugment는 실제로 10가지 다른 보강 세트입니다.
AutoContrast, Equalize, Solarize, RandomColorJitter, RandomContrast, RandomBrightness, ShearX, ShearY, TranslateX 및 TranslateY.
추론 시에 각 이미지에 대해 num_augmentations 보강기를 샘플링하고,
각 이미지에 대해 무작위 크기 요소를 샘플링합니다.
그런 다음, 이러한 보강을 순차적으로 적용합니다.
KerasCV는 augmentations_per_image 및 magnitude 매개변수를 사용하여,
이러한 매개변수를 쉽게 조정할 수 있도록 합니다!
한 번 돌려봅시다:
rand_augment = keras_cv.layers.RandAugment(
augmentations_per_image=3,
value_range=(0, 255),
magnitude=0.3,
magnitude_stddev=0.2,
rate=1.0,
)
augmenters += [rand_augment]
image_batch = rand_augment(image_batch)
keras_cv.visualization.plot_image_gallery(
image_batch,
rows=3,
cols=3,
value_range=(0, 255),
show=True,
)
훌륭해 보이지만 아직 끝나지 않았습니다! 이미지에 클래스의 중요한 특징 하나가 없다면 어떨까요? 예를 들어, 잎이 고양이 귀를 가리고 있지만, 분류기가 고양이의 귀를 관찰하여 고양이를 분류하는 법을 배웠다면 어떨까요?
이 문제를 해결하는 쉬운 방법 중 하나는 RandomCutout을 사용하는 것입니다.
이 방법은 이미지의 하위 섹션을 무작위로 제거합니다.
random_cutout = keras_cv.layers.RandomCutout(width_factor=0.4, height_factor=0.4)
keras_cv.visualization.plot_image_gallery(
random_cutout(image_batch),
rows=3,
cols=3,
value_range=(0, 255),
show=True,
)
이 방법은 문제를 비교적 잘 해결하지만, 분류기가 잘린 부분에 의해 발생한 특징과 검은색 픽셀 영역 사이의 경계에 대한 반응을 개발하게 할 수 있습니다.
CutMix는
더 복잡하고 효과적인 기술을 사용하여 같은 문제를 해결합니다.
잘린 부분을 검은색 픽셀로 대체하는 대신,
CutMix는 이러한 영역을 트레이닝 세트 내에서 샘플링한 다른 이미지의 영역으로 대체합니다!
이 대체에 따라, 이미지의 분류 레이블이 원본과 혼합된 이미지의 클래스 레이블을 혼합하여 업데이트됩니다.
실제로는 어떻게 보일까요? 확인해 보겠습니다.
cut_mix = keras_cv.layers.CutMix()
# CutMix는 이미지와 레이블을 모두 수정해야 합니다.
inputs = {"images": image_batch, "labels": label_batch}
keras_cv.visualization.plot_image_gallery(
cut_mix(inputs)["images"],
rows=3,
cols=3,
value_range=(0, 255),
show=True,
)
보강기에 추가하는 것을 잠시 미룹시다. 곧 자세히 설명하겠습니다!
다음으로, MixUp()을 살펴보겠습니다.
안타깝게도, MixUp()은 경험적으로 트레이닝된 모델의 견고성과 일반화를 상당히 개선하는 것으로 나타났지만,
왜 이런 개선이 일어나는지는 잘 이해되지 않았습니다…
하지만 약간의 연금술은 누구에게도 해가 되지 않았습니다!
MixUp()은 배치에서 두 개의 이미지를 샘플링한 다음,
문자 그대로 픽셀 강도와 분류 레이블을 함께 혼합하여 작동합니다.
실제로 작동하는 모습을 살펴보겠습니다.
mix_up = keras_cv.layers.MixUp()
# MixUp은 이미지와 레이블을 모두 수정해야 합니다.
inputs = {"images": image_batch, "labels": label_batch}
keras_cv.visualization.plot_image_gallery(
mix_up(inputs)["images"],
rows=3,
cols=3,
value_range=(0, 255),
show=True,
)
자세히 보면, 이미지가 혼합된 것을 볼 수 있습니다.
모든 이미지에 CutMix()와 MixUp()을 적용하는 대신,
각 배치에 적용할 하나를 선택합니다.
이는 keras_cv.layers.RandomChoice()를 사용하여 표현할 수 있습니다.
cut_mix_or_mix_up = keras_cv.layers.RandomChoice([cut_mix, mix_up], batchwise=True)
augmenters += [cut_mix_or_mix_up]이제 최종 보강기를 트레이닝 데이터에 적용해 보겠습니다.
def create_augmenter_fn(augmenters):
def augmenter_fn(inputs):
for augmenter in augmenters:
inputs = augmenter(inputs)
return inputs
return augmenter_fn
augmenter_fn = create_augmenter_fn(augmenters)
train_ds = train_ds.map(augmenter_fn, num_parallel_calls=tf.data.AUTOTUNE)
image_batch = next(iter(train_ds.take(1)))["images"]
keras_cv.visualization.plot_image_gallery(
image_batch,
rows=3,
cols=3,
value_range=(0, 255),
show=True,
)
또한 모델에서 기대하는 이미지 크기의 dense 배치를 얻기 위해, 평가 세트의 크기를 조정해야 합니다.
이 경우 결정론적(deterministic) keras_cv.layers.Resizing을 사용하여,
평가 메트릭에 노이즈를 추가하는 것을 방지합니다.
inference_resizing = keras_cv.layers.Resizing(
IMAGE_SIZE[0], IMAGE_SIZE[1], crop_to_aspect_ratio=True
)
eval_ds = eval_ds.map(inference_resizing, num_parallel_calls=tf.data.AUTOTUNE)
image_batch = next(iter(eval_ds.take(1)))["images"]
keras_cv.visualization.plot_image_gallery(
image_batch,
rows=3,
cols=3,
value_range=(0, 255),
show=True,
)
마지막으로, 데이터세트를 언팩하고,
이를 (images, labels) 튜플을 받는 model.fit()에 전달할 준비를 합시다.
def unpackage_dict(inputs):
return inputs["images"], inputs["labels"]
train_ds = train_ds.map(unpackage_dict, num_parallel_calls=tf.data.AUTOTUNE)
eval_ds = eval_ds.map(unpackage_dict, num_parallel_calls=tf.data.AUTOTUNE)데이터 보강은 현대 분류기를 트레이닝하는 데 가장 어려운 부분입니다. 여기까지 온 것을 축하합니다!
옵티마이저 튜닝
최적의 성능을 달성하려면, 단일 학습률 대신 학습률 스케쥴을 사용해야 합니다. 여기서 사용된 워밍업 스케쥴을 사용한 코사인 감쇠에 대해서는 자세히 설명하지 않겠지만, 여기에서 자세히 읽을 수 있습니다.
def lr_warmup_cosine_decay(
global_step,
warmup_steps,
hold=0,
total_steps=0,
start_lr=0.0,
target_lr=1e-2,
):
# 코사인 감쇠
learning_rate = (
0.5
* target_lr
* (
1
+ ops.cos(
math.pi
* ops.convert_to_tensor(
global_step - warmup_steps - hold, dtype="float32"
)
/ ops.convert_to_tensor(
total_steps - warmup_steps - hold, dtype="float32"
)
)
)
)
warmup_lr = target_lr * (global_step / warmup_steps)
if hold > 0:
learning_rate = ops.where(
global_step > warmup_steps + hold, learning_rate, target_lr
)
learning_rate = ops.where(global_step < warmup_steps, warmup_lr, learning_rate)
return learning_rate
class WarmUpCosineDecay(schedules.LearningRateSchedule):
def __init__(self, warmup_steps, total_steps, hold, start_lr=0.0, target_lr=1e-2):
super().__init__()
self.start_lr = start_lr
self.target_lr = target_lr
self.warmup_steps = warmup_steps
self.total_steps = total_steps
self.hold = hold
def __call__(self, step):
lr = lr_warmup_cosine_decay(
global_step=step,
total_steps=self.total_steps,
warmup_steps=self.warmup_steps,
start_lr=self.start_lr,
target_lr=self.target_lr,
hold=self.hold,
)
return ops.where(step > self.total_steps, 0.0, lr)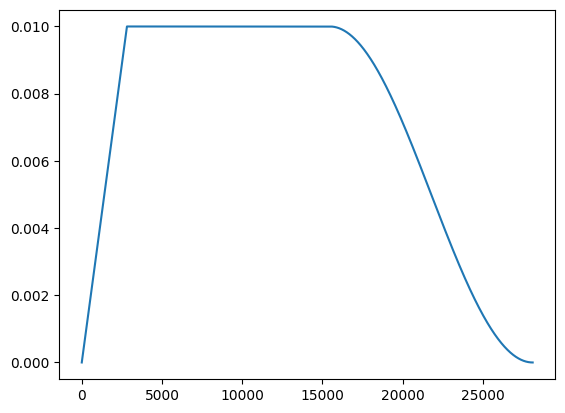
스케쥴은 예상대로 보입니다.
다음으로 이 옵티마이저를 구성해 보겠습니다.
total_images = 9000
total_steps = (total_images // BATCH_SIZE) * EPOCHS
warmup_steps = int(0.1 * total_steps)
hold_steps = int(0.45 * total_steps)
schedule = WarmUpCosineDecay(
start_lr=0.05,
target_lr=1e-2,
warmup_steps=warmup_steps,
total_steps=total_steps,
hold=hold_steps,
)
optimizer = optimizers.SGD(
weight_decay=5e-4,
learning_rate=schedule,
momentum=0.9,
)마침내, 우리는 이제 모델을 빌드하고 fit()를 호출할 수 있습니다!
keras_cv.models.EfficientNetV2B0Backbone()은
keras_cv.models.EfficientNetV2Backbone.from_preset('efficientnetv2_b0')의 편의 별칭(convenience alias)입니다.
이 사전 설정에는 사전 트레이닝된 가중치가 제공되지 않습니다.
backbone = keras_cv.models.EfficientNetV2B0Backbone()
model = keras.Sequential(
[
backbone,
keras.layers.GlobalMaxPooling2D(),
keras.layers.Dropout(rate=0.5),
keras.layers.Dense(101, activation="softmax"),
]
)MixUp()과 CutMix()로 생성된 레이블은 어느 정도 인위적이기 때문에, 이 보강 과정의 아티팩트로 인해 모델이 과적합되는 것을 방지하기 위해, 레이블 평활화(label smoothing)를 사용합니다.
loss = losses.CategoricalCrossentropy(label_smoothing=0.1)모델을 컴파일해 보겠습니다.
model.compile(
loss=loss,
optimizer=optimizer,
metrics=[
metrics.CategoricalAccuracy(),
metrics.TopKCategoricalAccuracy(k=5),
],
)마지막으로 fit()을 호출합니다.
model.fit(
train_ds,
epochs=EPOCHS,
validation_data=eval_ds,
)결과
96/96 ━━━━━━━━━━━━━━━━━━━━ 65s 462ms/step - categorical_accuracy: 0.0068 - loss: 6.6096 - top_k_categorical_accuracy: 0.0497 - val_categorical_accuracy: 0.0122 - val_loss: 4.7151 - val_top_k_categorical_accuracy: 0.1596
<keras.src.callbacks.history.History at 0x7fc7142c2e80>축하합니다! 이제 KerasCV에서 강력한 이미지 분류기를 처음부터 트레이닝하는 방법을 알게 되었습니다. 애플리케이션에 레이블이 지정된 데이터의 가용성에 따라, 처음부터 트레이닝하는 것이 위에서 설명한 데이터 보강 외에도 전이 학습을 사용하는 것보다 더 강력할 수도 있고 그렇지 않을 수도 있습니다. 더 작은 데이터 세트의 경우, 사전 트레이닝된 모델은 일반적으로 높은 정확도와 더 빠른 수렴을 생성합니다.
결론
이미지 분류는 아마도 컴퓨터 비전에서 가장 간단한 문제일지 몰라도,
현대적 환경에는 복잡한 구성 요소가 많이 있습니다.
다행히도, KerasCV는 이러한 구성 요소의 대부분을,
한 줄의 코드로 조립할 수 있는 강력한 프로덕션 등급 API를 제공합니다.
KerasCV의 ImageClassifier API, 사전 트레이닝된 가중치,
KerasCV 데이터 보강을 사용하면,
몇 백 줄의 코드로 강력한 분류기를 트레이닝하는 데 필요한 모든 것을 조립할 수 있습니다!
후속 연습으로 다음을 시도해 보세요.
- 자신의 데이터 세트에 대해 KerasCV 분류기를 미세 조정합니다.
- KerasCV의 데이터 보강에 대해 자세히 알아보세요.
- ImageNet에서 모델을 트레이닝하는 방법을 확인하세요.