SimCLR을 사용한 대조 사전 트레이닝을 사용한 반지도 이미지 분류
- 원본 링크 : https://keras.io/examples/vision/semisupervised_simclr/
- 최종 확인 : 2024-11-20
저자 : András Béres
생성일 : 2021/04/24
최종 편집일 : 2024/03/04
설명 : STL-10 데이터세트에 대한 반지도(semi-supervised) 이미지 분류를 위한 SimCLR을 사용한 대조(Contrastive) 사전 트레이닝.
소개
반지도 학습 (Semi-supervised learning)
반지도 학습은 부분적으로 레이블이 지정된 데이터 세트를 다루는 기계 학습 패러다임입니다. 딥러닝을 현실 세계에 적용할 때, 일반적으로 제대로 작동하려면 대규모 데이터 세트를 수집해야 합니다. 그러나, 라벨링 비용은 데이터세트 크기에 따라 선형적으로 확장되지만(각 예시에 라벨링하는 데 일정한 시간이 소요됨), 모델 성능은 이에 따라 하선형적(sublinearly)으로 확장됩니다. 이는 점점 더 많은 샘플에 라벨을 붙이는 것이 비용 효율성이 떨어지는 반면, 라벨이 없는 데이터를 수집하는 것은 일반적으로 대량으로 쉽게 사용할 수 있으므로 일반적으로 저렴하다는 것을 의미합니다.
반지도 학습은 부분적으로 레이블이 지정된 데이터세트만 필요로 하고, 레이블이 지정되지 않은 예제도 학습에 활용하여 레이블 효율성을 높임으로써 이 문제를 해결합니다.
이 예에서는, 레이블을 전혀 사용하지 않고 STL-10 반지도 데이터 세트에 대한 대조(contrastive) 학습을 통해 인코더를 사전 트레이닝한 다음, 레이블이 지정된 하위 집합만 사용하여 미세 조정합니다.
대조 학습(Contrastive learning)
가장 높은 레벨에서, 대조 학습의 기본 아이디어는 자기 지도(self-supervised) 방식으로 이미지 보강에 불변(invariant)하는 표현을 학습하는 것입니다. 이 목표의 한 가지 문제점은 사소한 퇴화(degenerate) 솔루션이 있다는 것입니다. 즉, 표현이 일정(constant)하고, 입력 이미지에 전혀 의존하지 않는 경우입니다.
대조 학습은 다음과 같은 방식으로 목표를 수정하여 이 함정을 피합니다. 동일한 이미지의 보강된 버전/뷰의 표현을 서로 더 가깝게 가져오는 동시에(대조적 양성 - contracting positives), 서로 다른 이미지들은 표현 공간에서 서로 멀리 밀어냅니다. (대조적 음성 - contrasting negatives).
이러한 대조 접근 방식 중 하나는 SimCLR입니다. 이는 이 목표를 최적화하는 데 필요한 핵심 구성 요소를 본질적으로 식별하고, 이 간단한 접근 방식을 확장하여 높은 성능을 달성할 수 있습니다.
또다른 접근 방식은 SimSiam(Keras 예제)입니다. SimCLR과의 주요 차이점은 전자는 손실에 부정적인 요소를 사용하지 않는다(not use any negatives)는 것입니다. 따라서, 사소한 솔루션을 명시적으로 방지하지 않고, 대신, 아키텍처 설계를 통해 암시적으로 방지합니다. (예측 네트워크 및 배치 정규화(BatchNorm)를 사용하는 비대칭 인코딩 경로가 최종 레이어에 적용됨)
SimCLR에 대한 자세한 내용은 공식 Google AI 블로그 게시물을 확인하고, 비전과 언어 전반에 걸친 자기 지도 학습에 대한 개요는 이 블로그 게시물을 확인하세요.
셋업
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
# 대규모 데이터세트를 처리할 수 있는지 확인하세요.
import resource
low, high = resource.getrlimit(resource.RLIMIT_NOFILE)
resource.setrlimit(resource.RLIMIT_NOFILE, (high, high))
import math
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_datasets as tfds
import keras
from keras import ops
from keras import layers하이퍼파라미터 셋업
# 데이터세트 하이퍼파라미터
unlabeled_dataset_size = 100000
labeled_dataset_size = 5000
image_channels = 3
# 알고리즘 하이퍼파라미터
num_epochs = 20
batch_size = 525 # 에포크당 200 스텝에 해당
width = 128
temperature = 0.1
# 대조(contrastive)를 위한 더 강력한 보강(augmentations),
# 지도 트레이닝을 위한 약한 보강(augmentations)
contrastive_augmentation = {"min_area": 0.25, "brightness": 0.6, "jitter": 0.2}
classification_augmentation = {
"min_area": 0.75,
"brightness": 0.3,
"jitter": 0.1,
}데이터세트
트레이닝하는 동안 우리는 라벨이 붙은 이미지의 작은 배치와 함께 라벨이 지정되지 않은 대량의 이미지를 동시에 로드합니다.
def prepare_dataset():
# 라벨이 붙은 샘플과 라벨이 붙지 않은 샘플은 그에 따라 선택된 배치 크기에 따라 동시에 로드됩니다.
steps_per_epoch = (unlabeled_dataset_size + labeled_dataset_size) // batch_size
unlabeled_batch_size = unlabeled_dataset_size // steps_per_epoch
labeled_batch_size = labeled_dataset_size // steps_per_epoch
print(
f"batch size is {unlabeled_batch_size} (unlabeled) + {labeled_batch_size} (labeled)"
)
# 리소스 사용량을 낮추기 위해 셔플을 끕니다.
unlabeled_train_dataset = (
tfds.load("stl10", split="unlabelled", as_supervised=True, shuffle_files=False)
.shuffle(buffer_size=10 * unlabeled_batch_size)
.batch(unlabeled_batch_size)
)
labeled_train_dataset = (
tfds.load("stl10", split="train", as_supervised=True, shuffle_files=False)
.shuffle(buffer_size=10 * labeled_batch_size)
.batch(labeled_batch_size)
)
test_dataset = (
tfds.load("stl10", split="test", as_supervised=True)
.batch(batch_size)
.prefetch(buffer_size=tf.data.AUTOTUNE)
)
# 라벨이 지정된 데이터세트와 라벨이 지정되지 않은 데이터세트를 함께 zip합니다.
train_dataset = tf.data.Dataset.zip(
(unlabeled_train_dataset, labeled_train_dataset)
).prefetch(buffer_size=tf.data.AUTOTUNE)
return train_dataset, labeled_train_dataset, test_dataset
# STL10 데이터세트를 로드합니다.
train_dataset, labeled_train_dataset, test_dataset = prepare_dataset()결과
batch size is 500 (unlabeled) + 25 (labeled)이미지 보강
대조 학습을 위한 가장 중요한 두 가지 이미지 보강은 다음과 같습니다.
- 자르기(Cropping): 모델이 동일한 이미지의 여러 부분을 유사하게 인코딩하도록 강제하며, RandomTranslation 및 RandomZoom 레이어를 사용하여 구현합니다.
- 색상 지터(Color jitter): 색상 히스토그램을 왜곡하여 작업에 대한 trivial 색상 히스토그램 기반 솔루션을 방지합니다. 이를 구현하는 원칙적인 방법은 색 공간의 아핀(affine) 변환을 사용하는 것입니다.
이 예에서는 무작위 수평 뒤집기도 사용합니다. 대조 학습에는 더 강한 보강이 적용되고, 몇 가지 레이블이 지정된 예에 대한 과적합을 피하기 위해 지도 분류에는 약한 강화가 적용됩니다.
우리는 임의의 색상 지터를 커스텀 전처리 레이어로 구현합니다. 데이터 보강을 위해 전처리 레이어를 사용하면, 다음과 같은 두 가지 이점이 있습니다.
- 데이터 보강은 배치에서 GPU에서 실행되므로, CPU 리소스가 제한된 환경(예: Colab Notebook 또는 개인용 컴퓨터)에서 데이터 파이프라인으로 인해 트레이닝에 병목 현상이 발생하지 않습니다.
- 데이터 전처리 파이프라인이 모델에 캡슐화되어 있으므로, 배포가 더 쉽고 배포 시 다시 구현할 필요가 없습니다.
# 이미지의 색상 분포를 왜곡합니다.
class RandomColorAffine(layers.Layer):
def __init__(self, brightness=0, jitter=0, **kwargs):
super().__init__(**kwargs)
self.seed_generator = keras.random.SeedGenerator(1337)
self.brightness = brightness
self.jitter = jitter
def get_config(self):
config = super().get_config()
config.update({"brightness": self.brightness, "jitter": self.jitter})
return config
def call(self, images, training=True):
if training:
batch_size = ops.shape(images)[0]
# 모든 색상에 대해 동일합니다.
brightness_scales = 1 + keras.random.uniform(
(batch_size, 1, 1, 1),
minval=-self.brightness,
maxval=self.brightness,
seed=self.seed_generator,
)
# 모든 색상에 대해 서로 다릅니다.
jitter_matrices = keras.random.uniform(
(batch_size, 1, 3, 3),
minval=-self.jitter,
maxval=self.jitter,
seed=self.seed_generator,
)
color_transforms = (
ops.tile(ops.expand_dims(ops.eye(3), axis=0), (batch_size, 1, 1, 1))
* brightness_scales
+ jitter_matrices
)
images = ops.clip(ops.matmul(images, color_transforms), 0, 1)
return images
# 이미지 보강 모듈
def get_augmenter(min_area, brightness, jitter):
zoom_factor = 1.0 - math.sqrt(min_area)
return keras.Sequential(
[
layers.Rescaling(1 / 255),
layers.RandomFlip("horizontal"),
layers.RandomTranslation(zoom_factor / 2, zoom_factor / 2),
layers.RandomZoom((-zoom_factor, 0.0), (-zoom_factor, 0.0)),
RandomColorAffine(brightness, jitter),
]
)
def visualize_augmentations(num_images):
# 데이터 세트로부터 배치 샘플링
images = next(iter(train_dataset))[0][0][:num_images]
# 보강 적용
augmented_images = zip(
images,
get_augmenter(**classification_augmentation)(images),
get_augmenter(**contrastive_augmentation)(images),
get_augmenter(**contrastive_augmentation)(images),
)
row_titles = [
"Original:",
"Weakly augmented:",
"Strongly augmented:",
"Strongly augmented:",
]
plt.figure(figsize=(num_images * 2.2, 4 * 2.2), dpi=100)
for column, image_row in enumerate(augmented_images):
for row, image in enumerate(image_row):
plt.subplot(4, num_images, row * num_images + column + 1)
plt.imshow(image)
if column == 0:
plt.title(row_titles[row], loc="left")
plt.axis("off")
plt.tight_layout()
visualize_augmentations(num_images=8)
인코더 아키텍쳐
# 인코더 아키텍쳐 정의
def get_encoder():
return keras.Sequential(
[
layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),
layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),
layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),
layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),
layers.Flatten(),
layers.Dense(width, activation="relu"),
],
name="encoder",
)지도 베이스라인 모델
베이스라인 지도 모델은 무작위 초기화를 사용하여 트레이닝됩니다.
# 무작위 초기화를 사용한 베이스라인 지도 트레이닝
baseline_model = keras.Sequential(
[
get_augmenter(**classification_augmentation),
get_encoder(),
layers.Dense(10),
],
name="baseline_model",
)
baseline_model.compile(
optimizer=keras.optimizers.Adam(),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[keras.metrics.SparseCategoricalAccuracy(name="acc")],
)
baseline_history = baseline_model.fit(
labeled_train_dataset, epochs=num_epochs, validation_data=test_dataset
)
print(
"Maximal validation accuracy: {:.2f}%".format(
max(baseline_history.history["val_acc"]) * 100
)
)결과
Epoch 1/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 9s 25ms/step - acc: 0.2031 - loss: 2.1576 - val_acc: 0.3234 - val_loss: 1.7719
Epoch 2/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.3476 - loss: 1.7792 - val_acc: 0.4042 - val_loss: 1.5626
Epoch 3/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.4060 - loss: 1.6054 - val_acc: 0.4319 - val_loss: 1.4832
Epoch 4/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 18ms/step - acc: 0.4347 - loss: 1.5052 - val_acc: 0.4570 - val_loss: 1.4428
Epoch 5/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 18ms/step - acc: 0.4600 - loss: 1.4546 - val_acc: 0.4765 - val_loss: 1.3977
Epoch 6/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.4754 - loss: 1.4015 - val_acc: 0.4740 - val_loss: 1.4082
Epoch 7/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.4901 - loss: 1.3589 - val_acc: 0.4761 - val_loss: 1.4061
Epoch 8/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.5110 - loss: 1.2793 - val_acc: 0.5247 - val_loss: 1.3026
Epoch 9/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.5298 - loss: 1.2765 - val_acc: 0.5138 - val_loss: 1.3286
Epoch 10/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.5514 - loss: 1.2078 - val_acc: 0.5543 - val_loss: 1.2227
Epoch 11/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.5520 - loss: 1.1851 - val_acc: 0.5446 - val_loss: 1.2709
Epoch 12/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.5851 - loss: 1.1368 - val_acc: 0.5725 - val_loss: 1.1944
Epoch 13/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 18ms/step - acc: 0.5738 - loss: 1.1411 - val_acc: 0.5685 - val_loss: 1.1974
Epoch 14/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 21ms/step - acc: 0.6078 - loss: 1.0308 - val_acc: 0.5899 - val_loss: 1.1769
Epoch 15/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 18ms/step - acc: 0.6284 - loss: 1.0386 - val_acc: 0.5863 - val_loss: 1.1742
Epoch 16/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 18ms/step - acc: 0.6450 - loss: 0.9773 - val_acc: 0.5849 - val_loss: 1.1993
Epoch 17/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6547 - loss: 0.9555 - val_acc: 0.5683 - val_loss: 1.2424
Epoch 18/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6593 - loss: 0.9084 - val_acc: 0.5990 - val_loss: 1.1458
Epoch 19/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6672 - loss: 0.9267 - val_acc: 0.5685 - val_loss: 1.2758
Epoch 20/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6824 - loss: 0.8863 - val_acc: 0.5969 - val_loss: 1.2035
Maximal validation accuracy: 59.90%대조 사전 트레이닝을 위한 셀프 지도 모델
대비 손실이 있는 레이블이 지정되지 않은 이미지에 대해 인코더를 사전 트레이닝합니다. 비선형 프로젝션 헤드는 인코더 표현의 품질을 향상시키기 위해 인코더 top에 부착됩니다.
우리는 InfoNCE/NT-Xent/N-pairs 손실을 사용하는데, 이는 다음과 같이 해석될 수 있습니다:
- 배치의 각 이미지를 자체 클래스가 있는 것처럼 처리합니다.
- 그런 다음, 각 “클래스"에 대한 두 가지 예(한 쌍의 보강된 뷰)가 있습니다.
- (두 가지 보강된 버전 모두에 대해) 각 뷰의 표현은 가능한 모든 쌍의 표현과 비교됩니다.
- 비교 표현의 온도 스케일 코사인 유사성을 로짓으로 사용합니다.
- 마지막으로, 범주형 교차 엔트로피를 “분류” 손실로 사용합니다.
사전 트레이닝 성능을 모니터링하는 데 다음 두 가지 측정항목이 사용됩니다.
- 대조 정확도(SimCLR Table 5) - Contrastive accuracy: 자기 지도 지표는 이미지 표현이 현재 배치의 다른 이미지 표현보다 다르게 보강된 버전의 표현과 더 유사한 경우의 비율입니다. 레이블이 지정된 예시가 없는 경우에도 자체 지도 지표를 하이퍼파라미터 튜닝에 사용할 수 있습니다.
- 선형 프로빙 정확도 - Linear probing accuracy: 선형 프로빙은 자기 지도 분류기를 평가하는 데 널리 사용되는 측정항목입니다. 이는 인코더의 특성의 탑에 대해 트레이닝된 로지스틱 회귀 분류기의 정확도로 계산됩니다. 우리의 경우, 이는 동결된 인코더의 top에 대해 단일 dense 레이어를 트레이닝하여 수행됩니다. 분류기가 사전 트레이닝 단계 후에 트레이닝되는 전통적인 접근 방식과 달리, 이 예에서는 사전 트레이닝 중에 분류기를 트레이닝합니다. 이로 인해 정확도가 약간 떨어질 수 있지만, 트레이닝 중에 값을 모니터링할 수 있으므로 실험과 디버깅에 도움이 됩니다.
널리 사용되는 또 다른 지도 측정항목은 KNN 정확도입니다. 이는 인코더 특성의 top에 대한 트레이닝된 KNN 분류기의 정확도이지만, 이 예에서는 구현되지 않았습니다.
# 모델 서브클래싱을 사용하여 대조 모델 정의
class ContrastiveModel(keras.Model):
def __init__(self):
super().__init__()
self.temperature = temperature
self.contrastive_augmenter = get_augmenter(**contrastive_augmentation)
self.classification_augmenter = get_augmenter(**classification_augmentation)
self.encoder = get_encoder()
# 프로젝션 헤드로서의 비선형 MLP
self.projection_head = keras.Sequential(
[
keras.Input(shape=(width,)),
layers.Dense(width, activation="relu"),
layers.Dense(width),
],
name="projection_head",
)
# 선형 프로빙을 위한 단일 Dense 레이어
self.linear_probe = keras.Sequential(
[layers.Input(shape=(width,)), layers.Dense(10)],
name="linear_probe",
)
self.encoder.summary()
self.projection_head.summary()
self.linear_probe.summary()
def compile(self, contrastive_optimizer, probe_optimizer, **kwargs):
super().compile(**kwargs)
self.contrastive_optimizer = contrastive_optimizer
self.probe_optimizer = probe_optimizer
# self.contrastive_loss는 메소드로 정의됩니다.
self.probe_loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
self.contrastive_loss_tracker = keras.metrics.Mean(name="c_loss")
self.contrastive_accuracy = keras.metrics.SparseCategoricalAccuracy(
name="c_acc"
)
self.probe_loss_tracker = keras.metrics.Mean(name="p_loss")
self.probe_accuracy = keras.metrics.SparseCategoricalAccuracy(name="p_acc")
@property
def metrics(self):
return [
self.contrastive_loss_tracker,
self.contrastive_accuracy,
self.probe_loss_tracker,
self.probe_accuracy,
]
def contrastive_loss(self, projections_1, projections_2):
# InfoNCE 손실 (정보 잡음 대비 추정 - information noise-contrastive estimation)
# NT-Xent 손실 (정규화된 온도 스케일 교차 엔트로피 - normalized temperature-scaled cross entropy)
# 코사인 유사성: l2 정규화된 특성 벡터의 내적
projections_1 = ops.normalize(projections_1, axis=1)
projections_2 = ops.normalize(projections_2, axis=1)
similarities = (
ops.matmul(projections_1, ops.transpose(projections_2)) / self.temperature
)
# 동일한 이미지의 두 보강 뷰 표현 간의 유사성은 다른 뷰 간의 유사성보다 높아야 합니다.
batch_size = ops.shape(projections_1)[0]
contrastive_labels = ops.arange(batch_size)
self.contrastive_accuracy.update_state(contrastive_labels, similarities)
self.contrastive_accuracy.update_state(
contrastive_labels, ops.transpose(similarities)
)
# 온도 스케일된 유사성이 교차 엔트로피에 대한 로짓으로 사용되며, 여기서는 손실의 대칭 버전이 사용됩니다.
loss_1_2 = keras.losses.sparse_categorical_crossentropy(
contrastive_labels, similarities, from_logits=True
)
loss_2_1 = keras.losses.sparse_categorical_crossentropy(
contrastive_labels, ops.transpose(similarities), from_logits=True
)
return (loss_1_2 + loss_2_1) / 2
def train_step(self, data):
(unlabeled_images, _), (labeled_images, labels) = data
# 라벨이 지정된 이미지와 라벨이 지정되지 않은 이미지가 모두 라벨 없이 사용됩니다.
images = ops.concatenate((unlabeled_images, labeled_images), axis=0)
# 각 이미지는 서로 다르게 두 번씩 보강됩니다.
augmented_images_1 = self.contrastive_augmenter(images, training=True)
augmented_images_2 = self.contrastive_augmenter(images, training=True)
with tf.GradientTape() as tape:
features_1 = self.encoder(augmented_images_1, training=True)
features_2 = self.encoder(augmented_images_2, training=True)
# 표현은 프로젝션 mlp를 통해 전달됩니다.
projections_1 = self.projection_head(features_1, training=True)
projections_2 = self.projection_head(features_2, training=True)
contrastive_loss = self.contrastive_loss(projections_1, projections_2)
gradients = tape.gradient(
contrastive_loss,
self.encoder.trainable_weights + self.projection_head.trainable_weights,
)
self.contrastive_optimizer.apply_gradients(
zip(
gradients,
self.encoder.trainable_weights + self.projection_head.trainable_weights,
)
)
self.contrastive_loss_tracker.update_state(contrastive_loss)
# 라벨은 즉석(on-the-fly) 로지스틱 회귀 평가에만 사용됩니다.
preprocessed_images = self.classification_augmenter(
labeled_images, training=True
)
with tf.GradientTape() as tape:
# 여기서 인코더는 추론 모드에서 사용되는데,
# 정규화를 방지하고 배치 정규화 매개변수가 사용되는 경우 이를 업데이트하기 위해서 입니다.
features = self.encoder(preprocessed_images, training=False)
class_logits = self.linear_probe(features, training=True)
probe_loss = self.probe_loss(labels, class_logits)
gradients = tape.gradient(probe_loss, self.linear_probe.trainable_weights)
self.probe_optimizer.apply_gradients(
zip(gradients, self.linear_probe.trainable_weights)
)
self.probe_loss_tracker.update_state(probe_loss)
self.probe_accuracy.update_state(labels, class_logits)
return {m.name: m.result() for m in self.metrics}
def test_step(self, data):
labeled_images, labels = data
# 테스트를 위해, 구성요소는 training=False 플래그와 함께 사용됩니다.
preprocessed_images = self.classification_augmenter(
labeled_images, training=False
)
features = self.encoder(preprocessed_images, training=False)
class_logits = self.linear_probe(features, training=False)
probe_loss = self.probe_loss(labels, class_logits)
self.probe_loss_tracker.update_state(probe_loss)
self.probe_accuracy.update_state(labels, class_logits)
# 테스트 시에는 프로브(probe) 측정항목만 기록됩니다.
return {m.name: m.result() for m in self.metrics[2:]}
# 대조 사전 트레이닝
pretraining_model = ContrastiveModel()
pretraining_model.compile(
contrastive_optimizer=keras.optimizers.Adam(),
probe_optimizer=keras.optimizers.Adam(),
)
pretraining_history = pretraining_model.fit(
train_dataset, epochs=num_epochs, validation_data=test_dataset
)
print(
"Maximal validation accuracy: {:.2f}%".format(
max(pretraining_history.history["val_p_acc"]) * 100
)
)결과
Model: "encoder"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━┩
│ conv2d_4 (Conv2D) │ ? │ 0 │
│ │ │ (unbuilt) │
├─────────────────────────────────┼───────────────────────────┼────────────┤
│ conv2d_5 (Conv2D) │ ? │ 0 │
│ │ │ (unbuilt) │
├─────────────────────────────────┼───────────────────────────┼────────────┤
│ conv2d_6 (Conv2D) │ ? │ 0 │
│ │ │ (unbuilt) │
├─────────────────────────────────┼───────────────────────────┼────────────┤
│ conv2d_7 (Conv2D) │ ? │ 0 │
│ │ │ (unbuilt) │
├─────────────────────────────────┼───────────────────────────┼────────────┤
│ flatten_1 (Flatten) │ ? │ 0 │
│ │ │ (unbuilt) │
├─────────────────────────────────┼───────────────────────────┼────────────┤
│ dense_2 (Dense) │ ? │ 0 │
│ │ │ (unbuilt) │
└─────────────────────────────────┴───────────────────────────┴────────────┘
Total params: 0 (0.00 B)
Trainable params: 0 (0.00 B)
Non-trainable params: 0 (0.00 B)
Model: "projection_head"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━┩
│ dense_3 (Dense) │ (None, 128) │ 16,512 │
├─────────────────────────────────┼───────────────────────────┼────────────┤
│ dense_4 (Dense) │ (None, 128) │ 16,512 │
└─────────────────────────────────┴───────────────────────────┴────────────┘
Total params: 33,024 (129.00 KB)
Trainable params: 33,024 (129.00 KB)
Non-trainable params: 0 (0.00 B)
Model: "linear_probe"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━┩
│ dense_5 (Dense) │ (None, 10) │ 1,290 │
└─────────────────────────────────┴───────────────────────────┴────────────┘
Total params: 1,290 (5.04 KB)
Trainable params: 1,290 (5.04 KB)
Non-trainable params: 0 (0.00 B)Epoch 1/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 34s 134ms/step - c_acc: 0.0880 - c_loss: 5.2606 - p_acc: 0.1326 - p_loss: 2.2726 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.2579 - val_p_loss: 2.0671
Epoch 2/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 139ms/step - c_acc: 0.2808 - c_loss: 3.6233 - p_acc: 0.2956 - p_loss: 2.0228 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.3440 - val_p_loss: 1.9242
Epoch 3/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 28s 136ms/step - c_acc: 0.4097 - c_loss: 2.9369 - p_acc: 0.3671 - p_loss: 1.8674 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.3876 - val_p_loss: 1.7757
Epoch 4/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 30s 142ms/step - c_acc: 0.4893 - c_loss: 2.5707 - p_acc: 0.3957 - p_loss: 1.7490 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.3960 - val_p_loss: 1.7002
Epoch 5/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 28s 136ms/step - c_acc: 0.5458 - c_loss: 2.3342 - p_acc: 0.4274 - p_loss: 1.6608 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.4374 - val_p_loss: 1.6145
Epoch 6/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 140ms/step - c_acc: 0.5949 - c_loss: 2.1179 - p_acc: 0.4410 - p_loss: 1.5812 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.4444 - val_p_loss: 1.5439
Epoch 7/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 28s 135ms/step - c_acc: 0.6273 - c_loss: 1.9861 - p_acc: 0.4633 - p_loss: 1.5076 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.4695 - val_p_loss: 1.5056
Epoch 8/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 139ms/step - c_acc: 0.6566 - c_loss: 1.8668 - p_acc: 0.4817 - p_loss: 1.4601 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.4790 - val_p_loss: 1.4566
Epoch 9/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 28s 135ms/step - c_acc: 0.6726 - c_loss: 1.7938 - p_acc: 0.4885 - p_loss: 1.4136 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.4933 - val_p_loss: 1.4163
Epoch 10/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 139ms/step - c_acc: 0.6931 - c_loss: 1.7210 - p_acc: 0.4954 - p_loss: 1.3663 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5140 - val_p_loss: 1.3677
Epoch 11/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 137ms/step - c_acc: 0.7055 - c_loss: 1.6619 - p_acc: 0.5210 - p_loss: 1.3376 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5155 - val_p_loss: 1.3573
Epoch 12/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 30s 145ms/step - c_acc: 0.7215 - c_loss: 1.6112 - p_acc: 0.5264 - p_loss: 1.2920 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5232 - val_p_loss: 1.3337
Epoch 13/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 31s 146ms/step - c_acc: 0.7279 - c_loss: 1.5749 - p_acc: 0.5388 - p_loss: 1.2570 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5217 - val_p_loss: 1.3155
Epoch 14/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 140ms/step - c_acc: 0.7435 - c_loss: 1.5196 - p_acc: 0.5505 - p_loss: 1.2507 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5460 - val_p_loss: 1.2640
Epoch 15/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 40s 135ms/step - c_acc: 0.7477 - c_loss: 1.4979 - p_acc: 0.5653 - p_loss: 1.2188 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5594 - val_p_loss: 1.2351
Epoch 16/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 139ms/step - c_acc: 0.7598 - c_loss: 1.4463 - p_acc: 0.5590 - p_loss: 1.1917 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5551 - val_p_loss: 1.2411
Epoch 17/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 28s 135ms/step - c_acc: 0.7633 - c_loss: 1.4271 - p_acc: 0.5775 - p_loss: 1.1731 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5502 - val_p_loss: 1.2428
Epoch 18/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 140ms/step - c_acc: 0.7666 - c_loss: 1.4246 - p_acc: 0.5752 - p_loss: 1.1805 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5633 - val_p_loss: 1.2167
Epoch 19/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 28s 135ms/step - c_acc: 0.7708 - c_loss: 1.3928 - p_acc: 0.5814 - p_loss: 1.1677 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5665 - val_p_loss: 1.2191
Epoch 20/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 140ms/step - c_acc: 0.7806 - c_loss: 1.3733 - p_acc: 0.5836 - p_loss: 1.1442 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5640 - val_p_loss: 1.2172
Maximal validation accuracy: 56.65%사전 트레이닝된 인코더의 지도 미세 조정
그런 다음, 무작위로 초기화된 단일 완전 연결 분류 레이어를 top에 연결하여, 레이블이 지정된 예제에 대해 인코더를 미세 조정합니다.
# 사전 트레이닝된 인코더의 지도 미세 조정
finetuning_model = keras.Sequential(
[
get_augmenter(**classification_augmentation),
pretraining_model.encoder,
layers.Dense(10),
],
name="finetuning_model",
)
finetuning_model.compile(
optimizer=keras.optimizers.Adam(),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[keras.metrics.SparseCategoricalAccuracy(name="acc")],
)
finetuning_history = finetuning_model.fit(
labeled_train_dataset, epochs=num_epochs, validation_data=test_dataset
)
print(
"Maximal validation accuracy: {:.2f}%".format(
max(finetuning_history.history["val_acc"]) * 100
)
)결과
Epoch 1/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 5s 18ms/step - acc: 0.2104 - loss: 2.0930 - val_acc: 0.4017 - val_loss: 1.5433
Epoch 2/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.4037 - loss: 1.5791 - val_acc: 0.4544 - val_loss: 1.4250
Epoch 3/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.4639 - loss: 1.4161 - val_acc: 0.5266 - val_loss: 1.2958
Epoch 4/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.5438 - loss: 1.2686 - val_acc: 0.5655 - val_loss: 1.1711
Epoch 5/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.5678 - loss: 1.1746 - val_acc: 0.5775 - val_loss: 1.1670
Epoch 6/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6096 - loss: 1.1071 - val_acc: 0.6034 - val_loss: 1.1400
Epoch 7/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6242 - loss: 1.0413 - val_acc: 0.6235 - val_loss: 1.0756
Epoch 8/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6284 - loss: 1.0264 - val_acc: 0.6030 - val_loss: 1.1048
Epoch 9/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6491 - loss: 0.9706 - val_acc: 0.5770 - val_loss: 1.2818
Epoch 10/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6754 - loss: 0.9104 - val_acc: 0.6119 - val_loss: 1.1087
Epoch 11/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 20ms/step - acc: 0.6620 - loss: 0.8855 - val_acc: 0.6323 - val_loss: 1.0526
Epoch 12/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 19ms/step - acc: 0.7060 - loss: 0.8179 - val_acc: 0.6406 - val_loss: 1.0565
Epoch 13/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 3s 17ms/step - acc: 0.7252 - loss: 0.7796 - val_acc: 0.6135 - val_loss: 1.1273
Epoch 14/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.7176 - loss: 0.7935 - val_acc: 0.6292 - val_loss: 1.1028
Epoch 15/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.7322 - loss: 0.7471 - val_acc: 0.6266 - val_loss: 1.1313
Epoch 16/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.7400 - loss: 0.7218 - val_acc: 0.6332 - val_loss: 1.1064
Epoch 17/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.7490 - loss: 0.6968 - val_acc: 0.6532 - val_loss: 1.0112
Epoch 18/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.7491 - loss: 0.6879 - val_acc: 0.6403 - val_loss: 1.1083
Epoch 19/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.7802 - loss: 0.6504 - val_acc: 0.6479 - val_loss: 1.0548
Epoch 20/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 3s 17ms/step - acc: 0.7800 - loss: 0.6234 - val_acc: 0.6409 - val_loss: 1.0998
Maximal validation accuracy: 65.32%베이스라인과의 비교
# 베이스라인 및 사전 트레이닝 + 미세 조정 프로세스의 분류 정확도:
def plot_training_curves(pretraining_history, finetuning_history, baseline_history):
for metric_key, metric_name in zip(["acc", "loss"], ["accuracy", "loss"]):
plt.figure(figsize=(8, 5), dpi=100)
plt.plot(
baseline_history.history[f"val_{metric_key}"],
label="supervised baseline",
)
plt.plot(
pretraining_history.history[f"val_p_{metric_key}"],
label="self-supervised pretraining",
)
plt.plot(
finetuning_history.history[f"val_{metric_key}"],
label="supervised finetuning",
)
plt.legend()
plt.title(f"Classification {metric_name} during training")
plt.xlabel("epochs")
plt.ylabel(f"validation {metric_name}")
plot_training_curves(pretraining_history, finetuning_history, baseline_history)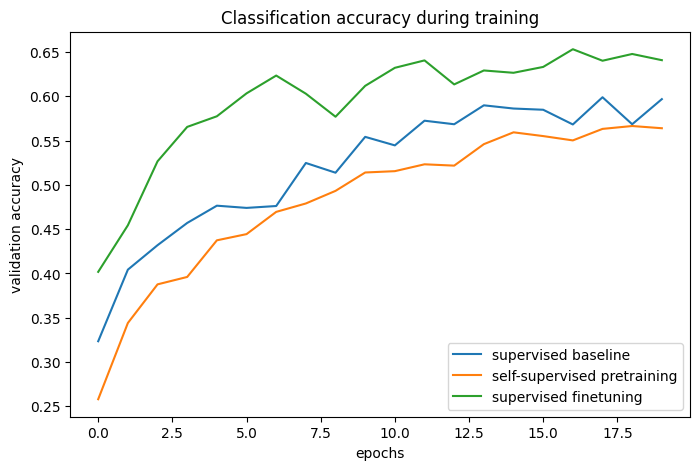
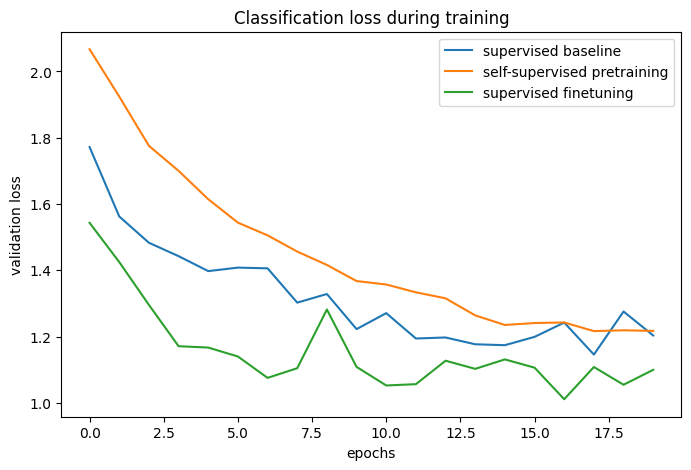
트레이닝 곡선을 비교함으로써, 대조 사전 트레이닝을 사용할 때, 더 높은 검증 정확도에 도달할 수 있고, 검증 손실이 더 낮다는 것을 알 수 있습니다. 이는 사전 트레이닝된 네트워크가 적은 양의 레이블이 지정된 예제만 볼 때 더 잘 일반화할 수 있다는 것을 의미합니다.
더욱 개선하기
아키텍쳐
원본 논문의 실험에서는 모델의 너비와 깊이를 늘리면, 지도 학습보다 더 높은 속도로 성능이 향상된다는 사실이 입증되었습니다. 또한, ResNet-50 인코더를 사용하는 것은 문헌에서 매우 표준적인 것입니다. 그러나 더 강력한 모델은 트레이닝 시간을 늘릴 뿐만 아니라 더 많은 메모리가 필요하고 사용할 수 있는 최대 배치 크기가 제한된다는 점을 명심하세요.
BatchNorm 레이어를 사용하면 때때로 성능이 저하될 수 있다는 것이 보고되고 있습니다. - 샘플 간 배치(intra-batch) 종속성으로 인해, 이 예제에서는 샘플을 사용하지 않았습니다. 그러나 저의 실험에서는, 특히 프로젝션 헤드에서, BatchNorm을 사용하면 성능이 향상되었습니다.
하이퍼파라미터
이 예에 사용된 하이퍼파라미터는 이 작업 및 아키텍처에 대해 수동으로 조정되었습니다. 따라서, 이를 변경하지 않으면, 추가적인 하이퍼파라미터 튜닝을 통해 미미한 이득만 기대할 수 있습니다.
그러나 다른 작업이나 모델 아키텍처의 경우 조정이 필요하므로, 가장 중요한 사항에 대한 메모는 다음과 같습니다.
- 배치 크기: 목표는 (느슨하게 말하면) 이미지 배치에 대한 분류로 해석될 수 있으므로, 배치 크기는 실제로 평소보다 더 중요한 하이퍼파라미터입니다. 높을수록 좋습니다.
- 온도: 온도는 교차 엔트로피 손실에 사용되는 소프트맥스 분포의 “부드러움(softness)“을 정의하며 중요한 하이퍼파라미터입니다. 일반적으로 값이 낮을수록 대비 정확도가 높아집니다. 최근의 트릭(ALIGN)은 온도 값도 학습하는 것입니다. (이는 온도 값을 tf.Variable로 정의하고, 이에 그래디언트를 적용하여 수행할 수 있음) 이것이 좋은 베이스라인 값을 제공하더라도, 저의 실험에서 학습된 온도는 최적보다 다소 낮았는데, 이는 표현 품질에 대한 완벽한 프록시가 아닌, 대비 손실과 관련하여 최적화되었기 때문입니다.
- 이미지 보강 강도: 사전 트레이닝 중에 더 강한 보강은 작업의 난이도를 증가시키지만, 어느 시점 이후에는 너무 강한 보강으로 인해 성능이 저하됩니다. 미세 조정하는 동안 더 강한 보강은 과적합을 줄이는 반면, 저의 경험에 따르면 너무 강한 보강은 사전 트레이닝으로 인한 성능 향상을 감소시킵니다. 전체 데이터 보강 파이프라인은 알고리즘의 중요한 하이퍼파라미터로 볼 수 있으며, Keras의 다른 커스텀 이미지 보강 레이어 구현은 이 저장소에서 찾을 수 있습니다.
- 학습률 스케쥴: 여기서는 일정한 스케쥴이 사용되지만, 문헌에서는 코사인 감쇠 스케쥴을 사용하는 것이 매우 일반적입니다. 이는 성능을 더욱 향상시킬 수 있습니다.
- 옵티마이저: 이 예에서는 기본 매개변수로 좋은 성능을 제공하는 Adam을 사용했습니다. 모멘텀이 있는 SGD는 더 많은 조정이 필요하지만, 성능이 약간 향상될 수 있습니다.
연관된 작업들
기타 인스턴스 레벨(이미지 레벨) 대비 학습 방법:
- MoCo (v2, v3): 가중치가 타겟 인코더의 지수 이동 평균인, 모멘텀 인코더도 사용합니다.
- SwAV: 쌍별 비교(pairwise comparison) 대신 클러스터링을 사용합니다.
- BarlowTwins: 쌍별 비교 대신 교차 상관 기반 목표를 사용합니다.
MoCo 및 BarlowTwins의 Keras 구현은 Colab 노트북이 포함된 이 저장소에서 찾을 수 있습니다.
유사한 목표를 최적화하지만, 부정적인 요소를 사용하지 않는, 새로운 작업 라인도 있습니다.
저의 경험에 따르면, 이러한 방법은 더 취약합니다. (이들은 상수 표현으로 축소될 수 있으며, 이 인코더 아키텍처를 사용하여 작동하도록 할 수 없습니다) 일반적으로 이들은 모델 아키텍처에 더 의존하지만, 더 작은 배치 크기에서 성능을 향상시킬 수 있습니다.
Hugging Face Hub에서 호스팅되는 트레이닝된 모델을 사용하고, Hugging Face Spaces에서 데모를 시도해 볼 수 있습니다.