Reptile을 사용한 Few-Shot 학습
- 원본 링크 : https://keras.io/examples/vision/reptile/
- 최종 확인 : 2024-11-20
저자 : ADMoreau
생성일 : 2020/05/21
최종 편집일 : 2023/07/20
설명 : Reptile를 사용한 Omniglot 데이터 세트의 Few-shot 분류.
소개
Reptile 알고리즘은 모델에 구애받지 않는 메타 학습(model-agnostic meta-learning)을 수행하기 위해 OpenAI에서 개발했습니다. 특히, 이 알고리즘은 최소한의 트레이닝(few-shot 학습)으로 새로운 작업을 수행하는 방법을 빠르게 학습하도록 설계되었습니다. 이 알고리즘은, 이전에 본 적 없는 데이터의 미니 배치에 대해 트레이닝된 가중치와 고정된 수의 메타 반복에 대한 트레이닝 전 모델 가중치 간의 차이를 사용하여, 확률적 경사 하강(Stochastic Gradient Descent)을 수행하는 방식으로 작동합니다.
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
import keras
from keras import layers
import matplotlib.pyplot as plt
import numpy as np
import random
import tensorflow as tf
import tensorflow_datasets as tfds하이퍼파라미터 정의
learning_rate = 0.003
meta_step_size = 0.25
inner_batch_size = 25
eval_batch_size = 25
meta_iters = 2000
eval_iters = 5
inner_iters = 4
eval_interval = 1
train_shots = 20
shots = 5
classes = 5데이터 준비
Omniglot 데이터 세트는
50개의 다른 알파벳에서 가져온 1,623개의 문자로 구성된 데이터 세트로,
각 문자에 대해 20개의 예시가 있습니다.
각 문자에 대한 20개의 샘플은 Amazon의 Mechanical Turk를 통해 온라인으로 추출했습니다.
few-shot 학습 과제의 경우, 무작위로 선택된 n개의 클래스에서 k개의 샘플(또는 “shots”)이
무작위로 추출됩니다. 이 n개의 숫자 값은 몇 개의 예제가 주어졌을 때
새로운 작업을 학습하는 모델의 능력을 테스트하는 데 사용할 새로운 임시 레이블 세트를 만드는 데 사용됩니다.
즉, 5개의 클래스를 트레이닝하는 경우, 새 클래스 레이블은 0, 1, 2, 3 또는 4가 됩니다.
Omniglot은 각 클래스에 대해 적절한 수의 샘플과 함께 다양한 클래스를 추출할 수 있기 때문에,
이 작업에 훌륭한 데이터 세트입니다.
class Dataset:
# 이 클래스는 Omniglot 데이터세트에서 신속하게 샘플링할 수 있는 few-shot 데이터세트를 생성하는
# 동시에 새로운 라벨을 생성할 수 있게 해줍니다.
def __init__(self, training):
# omniglot 데이터가 포함된 tfrecord 파일을 다운로드하고 데이터세트로 변환합니다.
split = "train" if training else "test"
ds = tfds.load("omniglot", split=split, as_supervised=True, shuffle_files=False)
# 데이터 세트에 걸쳐 반복하여, 각 개별 이미지와 해당 클래스를 가져오고, 해당 데이터를 딕셔너리에 넣습니다.
self.data = {}
def extraction(image, label):
# 이 함수는 Omniglot 이미지를 원하는 크기로 축소하고,
# 픽셀 값의 크기를 조정하며, RGB 이미지를 회색조로 변환합니다.
image = tf.image.convert_image_dtype(image, tf.float32)
image = tf.image.rgb_to_grayscale(image)
image = tf.image.resize(image, [28, 28])
return image, label
for image, label in ds.map(extraction):
image = image.numpy()
label = str(label.numpy())
if label not in self.data:
self.data[label] = []
self.data[label].append(image)
self.labels = list(self.data.keys())
def get_mini_dataset(
self, batch_size, repetitions, shots, num_classes, split=False
):
temp_labels = np.zeros(shape=(num_classes * shots))
temp_images = np.zeros(shape=(num_classes * shots, 28, 28, 1))
if split:
test_labels = np.zeros(shape=(num_classes))
test_images = np.zeros(shape=(num_classes, 28, 28, 1))
# 전체 라벨 세트에서 라벨의 무작위 하위 세트(subset)를 가져옵니다.
label_subset = random.choices(self.labels, k=num_classes)
for class_idx, class_obj in enumerate(label_subset):
# few shot 학습에서 열거된 인덱스 값을 미니 배치의 임시 레이블로 사용합니다.
temp_labels[class_idx * shots : (class_idx + 1) * shots] = class_idx
# 테스트용 분할 데이터 세트를 생성하는 경우, 각 라벨에서 추가 샘플을 선택하여 테스트 데이터 세트를 생성합니다.
if split:
test_labels[class_idx] = class_idx
images_to_split = random.choices(
self.data[label_subset[class_idx]], k=shots + 1
)
test_images[class_idx] = images_to_split[-1]
temp_images[
class_idx * shots : (class_idx + 1) * shots
] = images_to_split[:-1]
else:
# 무작위로 선택된 label_subset의 각 인덱스에 대해, 필요한 수의 이미지를 샘플링합니다.
temp_images[
class_idx * shots : (class_idx + 1) * shots
] = random.choices(self.data[label_subset[class_idx]], k=shots)
dataset = tf.data.Dataset.from_tensor_slices(
(temp_images.astype(np.float32), temp_labels.astype(np.int32))
)
dataset = dataset.shuffle(100).batch(batch_size).repeat(repetitions)
if split:
return dataset, test_images, test_labels
return dataset
import urllib3
urllib3.disable_warnings() # 다운로드 중에 발생할 수 있는 SSL 경고를 비활성화합니다.
train_dataset = Dataset(training=True)
test_dataset = Dataset(training=False)결과
Downloading and preparing dataset 17.95 MiB (download: 17.95 MiB, generated: Unknown size, total: 17.95 MiB) to /home/fchollet/tensorflow_datasets/omniglot/3.0.0...
Dl Completed...: 0 url [00:00, ? url/s]
Dl Size...: 0 MiB [00:00, ? MiB/s]
Extraction completed...: 0 file [00:00, ? file/s]
Generating splits...: 0%| | 0/4 [00:00<?, ? splits/s]
Generating train examples...: 0%| | 0/19280 [00:00<?, ? examples/s]
Shuffling /home/fchollet/tensorflow_datasets/omniglot/3.0.0.incomplete1MPXME/omniglot-train.tfrecord*...: 0%…
Generating test examples...: 0%| | 0/13180 [00:00<?, ? examples/s]
Shuffling /home/fchollet/tensorflow_datasets/omniglot/3.0.0.incomplete1MPXME/omniglot-test.tfrecord*...: 0%|…
Generating small1 examples...: 0%| | 0/2720 [00:00<?, ? examples/s]
Shuffling /home/fchollet/tensorflow_datasets/omniglot/3.0.0.incomplete1MPXME/omniglot-small1.tfrecord*...: 0…
Generating small2 examples...: 0%| | 0/3120 [00:00<?, ? examples/s]
Shuffling /home/fchollet/tensorflow_datasets/omniglot/3.0.0.incomplete1MPXME/omniglot-small2.tfrecord*...: 0…
Dataset omniglot downloaded and prepared to /home/fchollet/tensorflow_datasets/omniglot/3.0.0. Subsequent calls will reuse this data.데이터 세트의 몇 가지 예를 시각화
_, axarr = plt.subplots(nrows=5, ncols=5, figsize=(20, 20))
sample_keys = list(train_dataset.data.keys())
for a in range(5):
for b in range(5):
temp_image = train_dataset.data[sample_keys[a]][b]
temp_image = np.stack((temp_image[:, :, 0],) * 3, axis=2)
temp_image *= 255
temp_image = np.clip(temp_image, 0, 255).astype("uint8")
if b == 2:
axarr[a, b].set_title("Class : " + sample_keys[a])
axarr[a, b].imshow(temp_image, cmap="gray")
axarr[a, b].xaxis.set_visible(False)
axarr[a, b].yaxis.set_visible(False)
plt.show()
모델 빌드
def conv_bn(x):
x = layers.Conv2D(filters=64, kernel_size=3, strides=2, padding="same")(x)
x = layers.BatchNormalization()(x)
return layers.ReLU()(x)
inputs = layers.Input(shape=(28, 28, 1))
x = conv_bn(inputs)
x = conv_bn(x)
x = conv_bn(x)
x = conv_bn(x)
x = layers.Flatten()(x)
outputs = layers.Dense(classes, activation="softmax")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile()
optimizer = keras.optimizers.SGD(learning_rate=learning_rate)모델 트레이닝
training = []
testing = []
for meta_iter in range(meta_iters):
frac_done = meta_iter / meta_iters
cur_meta_step_size = (1 - frac_done) * meta_step_size
# 모델의 가중치를 임시로 저장합니다.
old_vars = model.get_weights()
# 전체 데이터 세트에서 샘플을 가져옵니다.
mini_dataset = train_dataset.get_mini_dataset(
inner_batch_size, inner_iters, train_shots, classes
)
for images, labels in mini_dataset:
with tf.GradientTape() as tape:
preds = model(images)
loss = keras.losses.sparse_categorical_crossentropy(labels, preds)
grads = tape.gradient(loss, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
new_vars = model.get_weights()
# 메타 단계에 대해 SGD를 수행합니다.
for var in range(len(new_vars)):
new_vars[var] = old_vars[var] + (
(new_vars[var] - old_vars[var]) * cur_meta_step_size
)
# 메타 학습 단계 후에, 새로 트레이닝된 가중치를 모델에 다시 로드합니다.
model.set_weights(new_vars)
# 평가 루프
if meta_iter % eval_interval == 0:
accuracies = []
for dataset in (train_dataset, test_dataset):
# 전체 데이터세트에서 미니 데이터세트를 샘플링합니다.
train_set, test_images, test_labels = dataset.get_mini_dataset(
eval_batch_size, eval_iters, shots, classes, split=True
)
old_vars = model.get_weights()
# 샘플을 트레이닝하고 결과 정확도를 얻습니다.
for images, labels in train_set:
with tf.GradientTape() as tape:
preds = model(images)
loss = keras.losses.sparse_categorical_crossentropy(labels, preds)
grads = tape.gradient(loss, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
test_preds = model.predict(test_images)
test_preds = tf.argmax(test_preds).numpy()
num_correct = (test_preds == test_labels).sum()
# 평가 정확도를 얻은 후 가중치를 재설정합니다.
model.set_weights(old_vars)
accuracies.append(num_correct / classes)
training.append(accuracies[0])
testing.append(accuracies[1])
if meta_iter % 100 == 0:
print(
"batch %d: train=%f test=%f" % (meta_iter, accuracies[0], accuracies[1])
)결과
batch 0: train=0.600000 test=0.200000
batch 100: train=0.800000 test=0.200000
batch 200: train=1.000000 test=1.000000
batch 300: train=1.000000 test=0.800000
batch 400: train=1.000000 test=0.600000
batch 500: train=1.000000 test=1.000000
batch 600: train=1.000000 test=0.600000
batch 700: train=1.000000 test=1.000000
batch 800: train=1.000000 test=0.800000
batch 900: train=0.800000 test=0.600000
batch 1000: train=1.000000 test=0.600000
batch 1100: train=1.000000 test=1.000000
batch 1200: train=1.000000 test=1.000000
batch 1300: train=0.600000 test=1.000000
batch 1400: train=1.000000 test=0.600000
batch 1500: train=1.000000 test=1.000000
batch 1600: train=0.800000 test=1.000000
batch 1700: train=0.800000 test=1.000000
batch 1800: train=0.800000 test=1.000000
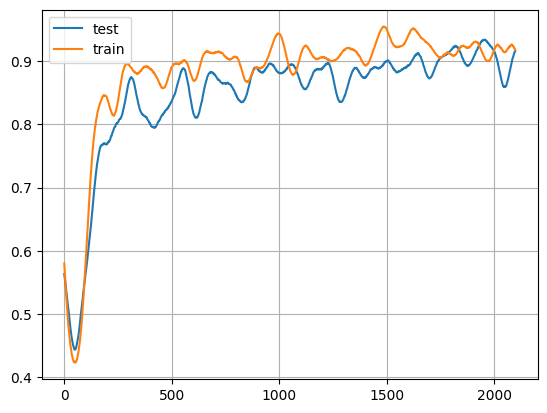
batch 1900: train=1.000000 test=1.000000결과 시각화
# 첫째, 표시할 트레이닝 및 테스트 배열을 원활(smooth)하게 하기 위한 일부 전처리입니다.
window_length = 100
train_s = np.r_[
training[window_length - 1 : 0 : -1],
training,
training[-1:-window_length:-1],
]
test_s = np.r_[
testing[window_length - 1 : 0 : -1], testing, testing[-1:-window_length:-1]
]
w = np.hamming(window_length)
train_y = np.convolve(w / w.sum(), train_s, mode="valid")
test_y = np.convolve(w / w.sum(), test_s, mode="valid")
# 트레이닝 정확도를 표시합니다.
x = np.arange(0, len(test_y), 1)
plt.plot(x, test_y, x, train_y)
plt.legend(["test", "train"])
plt.grid()
train_set, test_images, test_labels = dataset.get_mini_dataset(
eval_batch_size, eval_iters, shots, classes, split=True
)
for images, labels in train_set:
with tf.GradientTape() as tape:
preds = model(images)
loss = keras.losses.sparse_categorical_crossentropy(labels, preds)
grads = tape.gradient(loss, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
test_preds = model.predict(test_images)
test_preds = tf.argmax(test_preds).numpy()
_, axarr = plt.subplots(nrows=1, ncols=5, figsize=(20, 20))
sample_keys = list(train_dataset.data.keys())
for i, ax in zip(range(5), axarr):
temp_image = np.stack((test_images[i, :, :, 0],) * 3, axis=2)
temp_image *= 255
temp_image = np.clip(temp_image, 0, 255).astype("uint8")
ax.set_title(
"Label : {}, Prediction : {}".format(int(test_labels[i]), test_preds[i])
)
ax.imshow(temp_image, cmap="gray")
ax.xaxis.set_visible(False)
ax.yaxis.set_visible(False)
plt.show()