NNCLR을 사용한 자기 지도 대조 학습
- 원본 링크 : https://keras.io/examples/vision/nnclr/
- 최종 확인 : 2024-11-21
저자 : Rishit Dagli
생성일 : 2021/09/13
최종 편집일 : 2024/01/22
설명 : Implementation of NNCLR, a self-supervised learning method for computer vision.
Introduction
Self-supervised learning
Self-supervised representation learning aims to obtain robust representations of samples from raw data without expensive labels or annotations. Early methods in this field focused on defining pretraining tasks which involved a surrogate task on a domain with ample weak supervision labels. Encoders trained to solve such tasks are expected to learn general features that might be useful for other downstream tasks requiring expensive annotations like image classification.
Contrastive Learning
A broad category of self-supervised learning techniques are those that use contrastive losses, which have been used in a wide range of computer vision applications like image similarity, dimensionality reduction (DrLIM) and face verification/identification. These methods learn a latent space that clusters positive samples together while pushing apart negative samples.
NNCLR
In this example, we implement NNCLR as proposed in the paper With a Little Help from My Friends: Nearest-Neighbor Contrastive Learning of Visual Representations, by Google Research and DeepMind.
NNCLR learns self-supervised representations that go beyond single-instance positives, which allows for learning better features that are invariant to different viewpoints, deformations, and even intra-class variations. Clustering based methods offer a great approach to go beyond single instance positives, but assuming the entire cluster to be positives could hurt performance due to early over-generalization. Instead, NNCLR uses nearest neighbors in the learned representation space as positives. In addition, NNCLR increases the performance of existing contrastive learning methods like SimCLR(Keras Example) and reduces the reliance of self-supervised methods on data augmentation strategies.
Here is a great visualization by the paper authors showing how NNCLR builds on ideas from SimCLR:
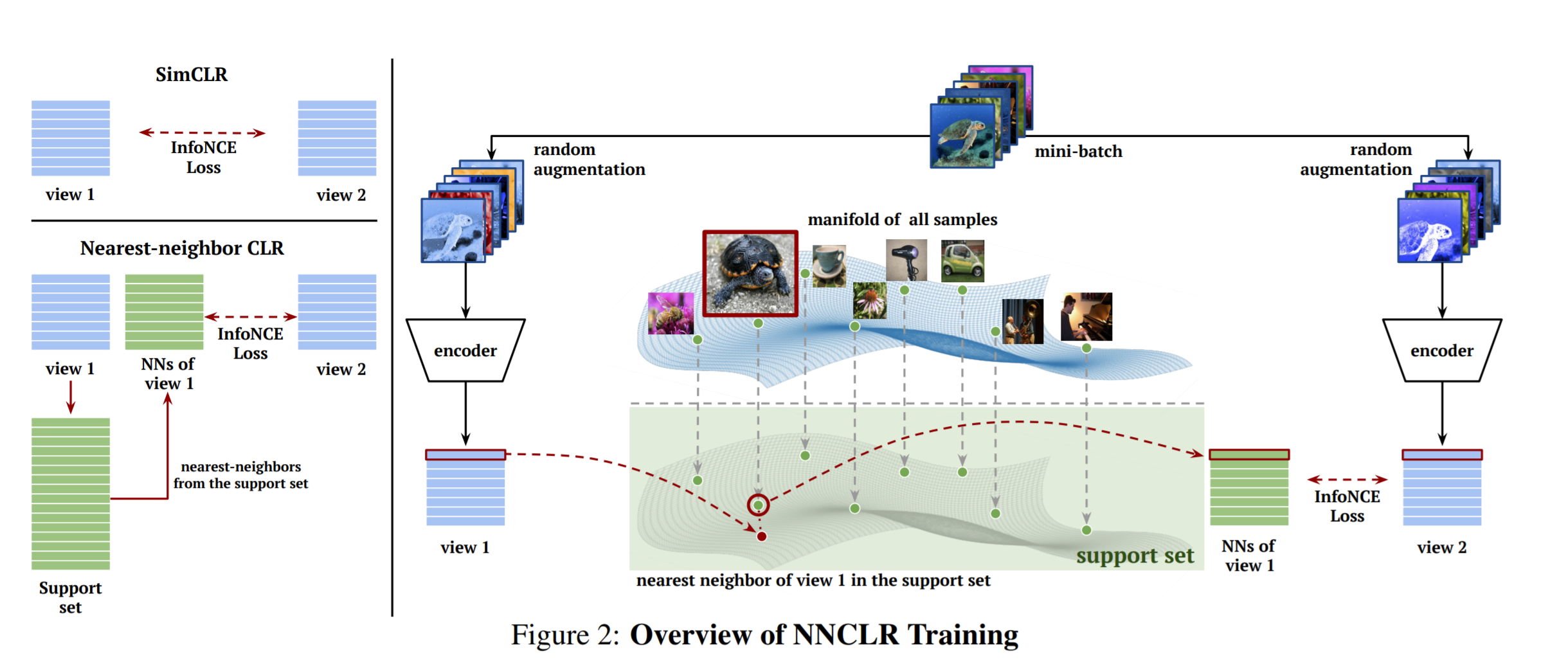
We can see that SimCLR uses two views of the same image as the positive pair. These two views, which are produced using random data augmentations, are fed through an encoder to obtain the positive embedding pair, we end up using two augmentations. NNCLR instead keeps a support set of embeddings representing the full data distribution, and forms the positive pairs using nearest-neighbours. A support set is used as memory during training, similar to a queue (i.e. first-in-first-out) as in MoCo.
This example requires tensorflow_datasets, which can be installed with this command:
!pip install tensorflow-datasetsSetup
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_datasets as tfds
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
import keras
import keras_cv
from keras import ops
from keras import layersHyperparameters
A greater queue_size most likely means better performance as shown in the original paper, but introduces significant computational overhead. The authors show that the best results of NNCLR are achieved with a queue size of 98,304 (the largest queue_size they experimented on). We here use 10,000 to show a working example.
AUTOTUNE = tf.data.AUTOTUNE
shuffle_buffer = 5000
# The below two values are taken from https://www.tensorflow.org/datasets/catalog/stl10
labelled_train_images = 5000
unlabelled_images = 100000
temperature = 0.1
queue_size = 10000
contrastive_augmenter = {
"brightness": 0.5,
"name": "contrastive_augmenter",
"scale": (0.2, 1.0),
}
classification_augmenter = {
"brightness": 0.2,
"name": "classification_augmenter",
"scale": (0.5, 1.0),
}
input_shape = (96, 96, 3)
width = 128
num_epochs = 5 # Use 25 for better results
steps_per_epoch = 50 # Use 200 for better resultsLoad the Dataset
We load the STL-10 dataset from TensorFlow Datasets, an image recognition dataset for developing unsupervised feature learning, deep learning, self-taught learning algorithms. It is inspired by the CIFAR-10 dataset, with some modifications.
dataset_name = "stl10"
def prepare_dataset():
unlabeled_batch_size = unlabelled_images // steps_per_epoch
labeled_batch_size = labelled_train_images // steps_per_epoch
batch_size = unlabeled_batch_size + labeled_batch_size
unlabeled_train_dataset = (
tfds.load(
dataset_name, split="unlabelled", as_supervised=True, shuffle_files=True
)
.shuffle(buffer_size=shuffle_buffer)
.batch(unlabeled_batch_size, drop_remainder=True)
)
labeled_train_dataset = (
tfds.load(dataset_name, split="train", as_supervised=True, shuffle_files=True)
.shuffle(buffer_size=shuffle_buffer)
.batch(labeled_batch_size, drop_remainder=True)
)
test_dataset = (
tfds.load(dataset_name, split="test", as_supervised=True)
.batch(batch_size)
.prefetch(buffer_size=AUTOTUNE)
)
train_dataset = tf.data.Dataset.zip(
(unlabeled_train_dataset, labeled_train_dataset)
).prefetch(buffer_size=AUTOTUNE)
return batch_size, train_dataset, labeled_train_dataset, test_dataset
batch_size, train_dataset, labeled_train_dataset, test_dataset = prepare_dataset()Augmentations
Other self-supervised techniques like SimCLR, BYOL, SwAV etc. rely heavily on a well-designed data augmentation pipeline to get the best performance. However, NNCLR is less dependent on complex augmentations as nearest-neighbors already provide richness in sample variations. A few common techniques often included augmentation pipelines are:
- Random resized crops
- Multiple color distortions
- Gaussian blur
Since NNCLR is less dependent on complex augmentations, we will only use random crops and random brightness for augmenting the input images.
Prepare augmentation module
def augmenter(brightness, name, scale):
return keras.Sequential(
[
layers.Input(shape=input_shape),
layers.Rescaling(1 / 255),
layers.RandomFlip("horizontal"),
keras_cv.layers.RandomCropAndResize(
target_size=(input_shape[0], input_shape[1]),
crop_area_factor=scale,
aspect_ratio_factor=(3 / 4, 4 / 3),
),
keras_cv.layers.RandomBrightness(factor=brightness, value_range=(0.0, 1.0)),
],
name=name,
)Encoder architecture
Using a ResNet-50 as the encoder architecture is standard in the literature. In the original paper, the authors use ResNet-50 as the encoder architecture and spatially average the outputs of ResNet-50. However, keep in mind that more powerful models will not only increase training time but will also require more memory and will limit the maximal batch size you can use. For the purpose of this example, we just use four convolutional layers.
def encoder():
return keras.Sequential(
[
layers.Input(shape=input_shape),
layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),
layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),
layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),
layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),
layers.Flatten(),
layers.Dense(width, activation="relu"),
],
name="encoder",
)The NNCLR model for contrastive pre-training
We train an encoder on unlabeled images with a contrastive loss. A nonlinear projection head is attached to the top of the encoder, as it improves the quality of representations of the encoder.
class NNCLR(keras.Model):
def __init__(
self, temperature, queue_size,
):
super().__init__()
self.probe_accuracy = keras.metrics.SparseCategoricalAccuracy()
self.correlation_accuracy = keras.metrics.SparseCategoricalAccuracy()
self.contrastive_accuracy = keras.metrics.SparseCategoricalAccuracy()
self.probe_loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
self.contrastive_augmenter = augmenter(**contrastive_augmenter)
self.classification_augmenter = augmenter(**classification_augmenter)
self.encoder = encoder()
self.projection_head = keras.Sequential(
[
layers.Input(shape=(width,)),
layers.Dense(width, activation="relu"),
layers.Dense(width),
],
name="projection_head",
)
self.linear_probe = keras.Sequential(
[layers.Input(shape=(width,)), layers.Dense(10)], name="linear_probe"
)
self.temperature = temperature
feature_dimensions = self.encoder.output_shape[1]
self.feature_queue = keras.Variable(
keras.utils.normalize(
keras.random.normal(shape=(queue_size, feature_dimensions)),
axis=1,
order=2,
),
trainable=False,
)
def compile(self, contrastive_optimizer, probe_optimizer, **kwargs):
super().compile(**kwargs)
self.contrastive_optimizer = contrastive_optimizer
self.probe_optimizer = probe_optimizer
def nearest_neighbour(self, projections):
support_similarities = ops.matmul(projections, ops.transpose(self.feature_queue))
nn_projections = ops.take(
self.feature_queue, ops.argmax(support_similarities, axis=1), axis=0
)
return projections + ops.stop_gradient(nn_projections - projections)
def update_contrastive_accuracy(self, features_1, features_2):
features_1 = keras.utils.normalize(features_1, axis=1, order=2)
features_2 = keras.utils.normalize(features_2, axis=1, order=2)
similarities = ops.matmul(features_1, ops.transpose(features_2))
batch_size = ops.shape(features_1)[0]
contrastive_labels = ops.arange(batch_size)
self.contrastive_accuracy.update_state(
ops.concatenate([contrastive_labels, contrastive_labels], axis=0),
ops.concatenate([similarities, ops.transpose(similarities)], axis=0),
)
def update_correlation_accuracy(self, features_1, features_2):
features_1 = (features_1 - ops.mean(features_1, axis=0)) / ops.std(
features_1, axis=0
)
features_2 = (features_2 - ops.mean(features_2, axis=0)) / ops.std(
features_2, axis=0
)
batch_size = ops.shape(features_1)[0]
cross_correlation = (
ops.matmul(ops.transpose(features_1), features_2) / batch_size
)
feature_dim = ops.shape(features_1)[1]
correlation_labels = ops.arange(feature_dim)
self.correlation_accuracy.update_state(
ops.concatenate([correlation_labels, correlation_labels], axis=0),
ops.concatenate(
[cross_correlation, ops.transpose(cross_correlation)], axis=0
),
)
def contrastive_loss(self, projections_1, projections_2):
projections_1 = keras.utils.normalize(projections_1, axis=1, order=2)
projections_2 = keras.utils.normalize(projections_2, axis=1, order=2)
similarities_1_2_1 = (
ops.matmul(
self.nearest_neighbour(projections_1), ops.transpose(projections_2)
)
/ self.temperature
)
similarities_1_2_2 = (
ops.matmul(
projections_2, ops.transpose(self.nearest_neighbour(projections_1))
)
/ self.temperature
)
similarities_2_1_1 = (
ops.matmul(
self.nearest_neighbour(projections_2), ops.transpose(projections_1)
)
/ self.temperature
)
similarities_2_1_2 = (
ops.matmul(
projections_1, ops.transpose(self.nearest_neighbour(projections_2))
)
/ self.temperature
)
batch_size = ops.shape(projections_1)[0]
contrastive_labels = ops.arange(batch_size)
loss = keras.losses.sparse_categorical_crossentropy(
ops.concatenate(
[
contrastive_labels,
contrastive_labels,
contrastive_labels,
contrastive_labels,
],
axis=0,
),
ops.concatenate(
[
similarities_1_2_1,
similarities_1_2_2,
similarities_2_1_1,
similarities_2_1_2,
],
axis=0,
),
from_logits=True,
)
self.feature_queue.assign(
ops.concatenate([projections_1, self.feature_queue[:-batch_size]], axis=0)
)
return loss
def train_step(self, data):
(unlabeled_images, _), (labeled_images, labels) = data
images = ops.concatenate((unlabeled_images, labeled_images), axis=0)
augmented_images_1 = self.contrastive_augmenter(images)
augmented_images_2 = self.contrastive_augmenter(images)
with tf.GradientTape() as tape:
features_1 = self.encoder(augmented_images_1)
features_2 = self.encoder(augmented_images_2)
projections_1 = self.projection_head(features_1)
projections_2 = self.projection_head(features_2)
contrastive_loss = self.contrastive_loss(projections_1, projections_2)
gradients = tape.gradient(
contrastive_loss,
self.encoder.trainable_weights + self.projection_head.trainable_weights,
)
self.contrastive_optimizer.apply_gradients(
zip(
gradients,
self.encoder.trainable_weights + self.projection_head.trainable_weights,
)
)
self.update_contrastive_accuracy(features_1, features_2)
self.update_correlation_accuracy(features_1, features_2)
preprocessed_images = self.classification_augmenter(labeled_images)
with tf.GradientTape() as tape:
features = self.encoder(preprocessed_images)
class_logits = self.linear_probe(features)
probe_loss = self.probe_loss(labels, class_logits)
gradients = tape.gradient(probe_loss, self.linear_probe.trainable_weights)
self.probe_optimizer.apply_gradients(
zip(gradients, self.linear_probe.trainable_weights)
)
self.probe_accuracy.update_state(labels, class_logits)
return {
"c_loss": contrastive_loss,
"c_acc": self.contrastive_accuracy.result(),
"r_acc": self.correlation_accuracy.result(),
"p_loss": probe_loss,
"p_acc": self.probe_accuracy.result(),
}
def test_step(self, data):
labeled_images, labels = data
preprocessed_images = self.classification_augmenter(
labeled_images, training=False
)
features = self.encoder(preprocessed_images, training=False)
class_logits = self.linear_probe(features, training=False)
probe_loss = self.probe_loss(labels, class_logits)
self.probe_accuracy.update_state(labels, class_logits)
return {"p_loss": probe_loss, "p_acc": self.probe_accuracy.result()}Pre-train NNCLR
We train the network using a temperature of 0.1 as suggested in the paper and a queue_size of 10,000 as explained earlier. We use Adam as our contrastive and probe optimizer. For this example we train the model for only 30 epochs but it should be trained for more epochs for better performance.
The following two metrics can be used for monitoring the pretraining performance which we also log (taken from this Keras example):
- Contrastive accuracy: self-supervised metric, the ratio of cases in which the representation of an image is more similar to its differently augmented version’s one, than to the representation of any other image in the current batch. Self-supervised metrics can be used for hyperparameter tuning even in the case when there are no labeled examples.
- Linear probing accuracy: linear probing is a popular metric to evaluate self-supervised classifiers. It is computed as the accuracy of a logistic regression classifier trained on top of the encoder’s features. In our case, this is done by training a single dense layer on top of the frozen encoder. Note that contrary to traditional approach where the classifier is trained after the pretraining phase, in this example we train it during pretraining. This might slightly decrease its accuracy, but that way we can monitor its value during training, which helps with experimentation and debugging.
model = NNCLR(temperature=temperature, queue_size=queue_size)
model.compile(
contrastive_optimizer=keras.optimizers.Adam(),
probe_optimizer=keras.optimizers.Adam(),
jit_compile=False,
)
pretrain_history = model.fit(
train_dataset, epochs=num_epochs, validation_data=test_dataset
)Self supervised learning is particularly helpful when you do only have access to very limited labeled training data but you can manage to build a large corpus of unlabeled data as shown by previous methods like SEER, SimCLR, SwAV and more.
You should also take a look at the blog posts for these papers which neatly show that it is possible to achieve good results with few class labels by first pretraining on a large unlabeled dataset and then fine-tuning on a smaller labeled dataset:
- Advancing Self-Supervised and Semi-Supervised Learning with SimCLR
- High-performance self-supervised image classification with contrastive clustering
- Self-supervised learning: The dark matter of intelligence
You are also advised to check out the original paper.
Many thanks to Debidatta Dwibedi (Google Research), primary author of the NNCLR paper for his super-insightful reviews for this example. This example also takes inspiration from the SimCLR Keras Example.