ConvMixer로 이미지 분류
- 원본 링크 : https://keras.io/examples/vision/convmixer/
- 최종 확인 : 2024-11-20
저자 : Sayak Paul
생성일 : 2021/10/12
최종 편집일 : 2021/10/12
설명 : 이미지 패치에 적용되는 모든 컨볼루션 네트워크입니다.
소개
비전 트랜스포머(ViT; Dosovitskiy et al.)는 입력 이미지에서 작은 패치를 추출하여, 선형적으로 프로젝션 한 다음, 트랜스포머(Vaswani et al.) 블록을 적용합니다. ViT는 지역성을 모델링하기 위해 강력한 귀납적 편향(컨볼루션과 같이)을 가질 필요가 없기 때문에, 이미지 인식 작업에 ViT를 적용하는 것은 유망한 연구 분야로 빠르게 자리 잡고 있습니다. 따라서 가능한 한 최소한의 귀납적 전제 조건으로 트레이닝 데이터만으로 학습할 수 있는 일반적인 계산 프리미티브입니다. 적절한 정규화, 데이터 보강, 비교적 큰 데이터 세트로 트레이닝하면 ViT는 뛰어난 다운스트림 성능을 발휘합니다.
패치만 있으면 충분하다(Patches Are All You Need) 논문(참고: 작성 시점에서는, ICLR 2022 컨퍼런스에 제출된 논문)에서 저자들은 패치를 사용하여 모든 컨볼루션 네트워크를 트레이닝하고 경쟁력 있는 결과를 입증하는 아이디어를 확장합니다. 이들의 아키텍처, 즉 ConvMixer는 네트워크의 여러 레이어에서 동일한 깊이와 해상도, residual 연결 등을 사용하는 등, ViT, MLP-Mixer(Tolstikhin et al.)와 같은 최신 등방성(isotrophic) 아키텍처의 레시피를 사용합니다.
이 예제에서는, ConvMixer 모델을 구현하고 CIFAR-10 데이터 세트에 대해 그 성능을 시연해 보겠습니다.
Imports
import keras
from keras import layers
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np하이퍼파라미터
실행 시간을 짧게 유지하기 위해, 우리는 모델을 10 에포크만 트레이닝합니다. ConvMixer의 핵심 아이디어에 집중하기 위해, RandAugment(Cubuk et al.)와 같은 다른 트레이닝 관련 요소는 사용하지 않습니다. 자세한 내용은 원본 논문을 참조하시기 바랍니다.
learning_rate = 0.001
weight_decay = 0.0001
batch_size = 128
num_epochs = 10CIFAR-10 데이터 세트 로드
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
val_split = 0.1
val_indices = int(len(x_train) * val_split)
new_x_train, new_y_train = x_train[val_indices:], y_train[val_indices:]
x_val, y_val = x_train[:val_indices], y_train[:val_indices]
print(f"Training data samples: {len(new_x_train)}")
print(f"Validation data samples: {len(x_val)}")
print(f"Test data samples: {len(x_test)}")결과
Training data samples: 45000
Validation data samples: 5000
Test data samples: 10000tf.data.Dataset 객체 준비
저희의 데이터 보강 파이프라인은 저자가 CIFAR-10 데이터 세트에 사용한 것과는 다르지만, 이 예제의 목적에는 문제가 없습니다. 데이터 전처리와 관련해서는 모든 기능을 갖춘 프레임워크이므로 다른 백엔드(jax, torch)와 함께 데이터 I/O 및 전처리를 위한 TF API를 사용해도 괜찮습니다.
image_size = 32
auto = tf.data.AUTOTUNE
augmentation_layers = [
keras.layers.RandomCrop(image_size, image_size),
keras.layers.RandomFlip("horizontal"),
]
def augment_images(images):
for layer in augmentation_layers:
images = layer(images, training=True)
return images
def make_datasets(images, labels, is_train=False):
dataset = tf.data.Dataset.from_tensor_slices((images, labels))
if is_train:
dataset = dataset.shuffle(batch_size * 10)
dataset = dataset.batch(batch_size)
if is_train:
dataset = dataset.map(
lambda x, y: (augment_images(x), y), num_parallel_calls=auto
)
return dataset.prefetch(auto)
train_dataset = make_datasets(new_x_train, new_y_train, is_train=True)
val_dataset = make_datasets(x_val, y_val)
test_dataset = make_datasets(x_test, y_test)ConvMixer 유틸리티
다음 그림(원본 문서에서 발췌)은 ConvMixer 모델을 설명합니다:
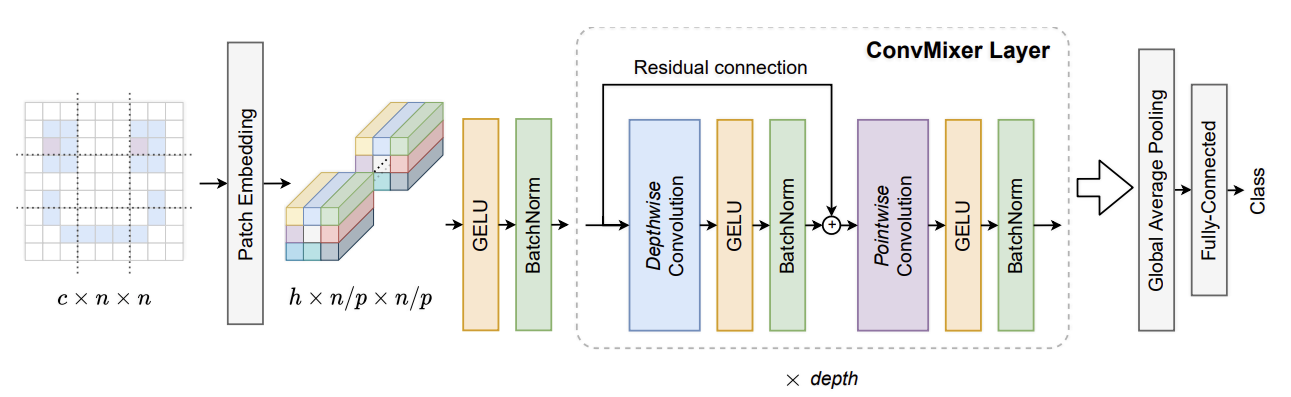
ConvMixer는 다음과 같은 주요 차이점이 있는 MLP-Mixer 모델과 매우 유사합니다:
- 완전 연결된(fully-connected) 레이어를 사용하는 대신, 표준 컨볼루션 레이어를 사용합니다.
- (ViT 및 MLP-Mixer에 일반적으로 사용되는) LayerNorm 대신, BatchNorm을 사용합니다.
ConvMixer에는 두 가지 유형의 컨볼루션 레이어가 사용됩니다. (1): 이미지의 공간적 위치를 혼합하기 위한 깊이별(Depthwise) 컨볼루션, (2): 포인트별(Pointwise) 컨볼루션(깊이별 컨볼루션을 따르는): 패치 전체에 걸쳐 채널별 정보를 혼합하기 위한 컨볼루션입니다. 또 다른 키포인트는 더 큰 수용 필드를 허용하기 위해 더 큰 커널 크기 를 사용하는 것입니다.
def activation_block(x):
x = layers.Activation("gelu")(x)
return layers.BatchNormalization()(x)
def conv_stem(x, filters: int, patch_size: int):
x = layers.Conv2D(filters, kernel_size=patch_size, strides=patch_size)(x)
return activation_block(x)
def conv_mixer_block(x, filters: int, kernel_size: int):
# 깊이별 컨볼루션.
x0 = x
x = layers.DepthwiseConv2D(kernel_size=kernel_size, padding="same")(x)
x = layers.Add()([activation_block(x), x0]) # Residual.
# 포인트별 컨볼루션.
x = layers.Conv2D(filters, kernel_size=1)(x)
x = activation_block(x)
return x
def get_conv_mixer_256_8(
image_size=32, filters=256, depth=8, kernel_size=5, patch_size=2, num_classes=10
):
"""ConvMixer-256/8: https://openreview.net/pdf?id=TVHS5Y4dNvM.
하이퍼파라미터 값은 논문에서 가져온 것입니다.
"""
inputs = keras.Input((image_size, image_size, 3))
x = layers.Rescaling(scale=1.0 / 255)(inputs)
# 패치 임베딩 추출.
x = conv_stem(x, filters, patch_size)
# ConvMixer 블록.
for _ in range(depth):
x = conv_mixer_block(x, filters, kernel_size)
# 분류 블록.
x = layers.GlobalAvgPool2D()(x)
outputs = layers.Dense(num_classes, activation="softmax")(x)
return keras.Model(inputs, outputs)이 실험에 사용된 모델은 ConvMixer-256/8로, 여기서 256은 채널 수를 나타내고 8은 깊이를 나타냅니다. 결과 모델의 파라미터 수는 80만 개에 불과합니다.
모델 트레이닝 및 평가 유틸리티
# Code reference:
# https://keras.io/examples/vision/image_classification_with_vision_transformer/.
def run_experiment(model):
optimizer = keras.optimizers.AdamW(
learning_rate=learning_rate, weight_decay=weight_decay
)
model.compile(
optimizer=optimizer,
loss="sparse_categorical_crossentropy",
metrics=["accuracy"],
)
checkpoint_filepath = "/tmp/checkpoint.keras"
checkpoint_callback = keras.callbacks.ModelCheckpoint(
checkpoint_filepath,
monitor="val_accuracy",
save_best_only=True,
save_weights_only=False,
)
history = model.fit(
train_dataset,
validation_data=val_dataset,
epochs=num_epochs,
callbacks=[checkpoint_callback],
)
model.load_weights(checkpoint_filepath)
_, accuracy = model.evaluate(test_dataset)
print(f"Test accuracy: {round(accuracy * 100, 2)}%")
return history, model모델 트레이닝 및 평가
conv_mixer_model = get_conv_mixer_256_8()
history, conv_mixer_model = run_experiment(conv_mixer_model)결과
Epoch 1/10
352/352 ━━━━━━━━━━━━━━━━━━━━ 46s 103ms/step - accuracy: 0.4594 - loss: 1.4780 - val_accuracy: 0.1536 - val_loss: 4.0766
Epoch 2/10
352/352 ━━━━━━━━━━━━━━━━━━━━ 14s 39ms/step - accuracy: 0.6996 - loss: 0.8479 - val_accuracy: 0.7240 - val_loss: 0.7926
Epoch 3/10
352/352 ━━━━━━━━━━━━━━━━━━━━ 14s 39ms/step - accuracy: 0.7823 - loss: 0.6287 - val_accuracy: 0.7800 - val_loss: 0.6532
Epoch 4/10
352/352 ━━━━━━━━━━━━━━━━━━━━ 14s 39ms/step - accuracy: 0.8264 - loss: 0.5003 - val_accuracy: 0.8074 - val_loss: 0.5895
Epoch 5/10
352/352 ━━━━━━━━━━━━━━━━━━━━ 21s 60ms/step - accuracy: 0.8605 - loss: 0.4092 - val_accuracy: 0.7996 - val_loss: 0.6037
Epoch 6/10
352/352 ━━━━━━━━━━━━━━━━━━━━ 13s 38ms/step - accuracy: 0.8788 - loss: 0.3527 - val_accuracy: 0.8072 - val_loss: 0.6162
Epoch 7/10
352/352 ━━━━━━━━━━━━━━━━━━━━ 21s 61ms/step - accuracy: 0.8972 - loss: 0.2984 - val_accuracy: 0.8226 - val_loss: 0.5604
Epoch 8/10
352/352 ━━━━━━━━━━━━━━━━━━━━ 21s 61ms/step - accuracy: 0.9087 - loss: 0.2608 - val_accuracy: 0.8310 - val_loss: 0.5303
Epoch 9/10
352/352 ━━━━━━━━━━━━━━━━━━━━ 14s 39ms/step - accuracy: 0.9176 - loss: 0.2302 - val_accuracy: 0.8458 - val_loss: 0.5051
Epoch 10/10
352/352 ━━━━━━━━━━━━━━━━━━━━ 14s 38ms/step - accuracy: 0.9336 - loss: 0.1918 - val_accuracy: 0.8316 - val_loss: 0.5848
79/79 ━━━━━━━━━━━━━━━━━━━━ 3s 32ms/step - accuracy: 0.8371 - loss: 0.5501
Test accuracy: 83.69%트레이닝과 검증 성능의 격차는 추가적인 정규화 기법을 사용하여 완화할 수 있습니다. 그럼에도 불구하고, 80만 개의 파라미터로 10 에포크 내에 최대 83%의 정확도를 달성할 수 있다는 것은 매우 강력한 결과입니다.
ConvMixer 내부 시각화하기
패치 임베딩과 학습된 컨볼루션 필터를 시각화할 수 있습니다. 각 패치 임베딩과 중간 특성 맵의 채널 수는 동일합니다. (이 경우 256개) 이렇게 하면 시각화 유틸리티를 더 쉽게 구현할 수 있습니다.
# Code reference: https://bit.ly/3awIRbP.
def visualization_plot(weights, idx=1):
# 먼저, 등방성(isotrophic) 스케일링을 피하기 위해 주어진 가중치에 min-max 정규화를 적용합니다.
p_min, p_max = weights.min(), weights.max()
weights = (weights - p_min) / (p_max - p_min)
# 모든 필터를 시각화합니다.
num_filters = 256
plt.figure(figsize=(8, 8))
for i in range(num_filters):
current_weight = weights[:, :, :, i]
if current_weight.shape[-1] == 1:
current_weight = current_weight.squeeze()
ax = plt.subplot(16, 16, idx)
ax.set_xticks([])
ax.set_yticks([])
plt.imshow(current_weight)
idx += 1
# 먼저 학습된 패치 임베딩을 시각화합니다.
patch_embeddings = conv_mixer_model.layers[2].get_weights()[0]
visualization_plot(patch_embeddings)
네트워크가 수렴하도록 트레이닝하지 않았음에도 불구하고, 패치마다 다른 패턴을 보이는 것을 알 수 있습니다. 일부는 다른 패치와 유사성을 공유하는 반면, 일부는 매우 다릅니다. 이러한 시각화는 이미지 크기가 클수록 더욱 두드러집니다.
마찬가지로, raw 컨볼루션 커널을 시각화할 수도 있습니다. 이를 통해 특정 커널이 수용하는 패턴을 이해하는 데 도움이 될 수 있습니다.
# 먼저, 포인트별 컨볼루션이 아닌 컨볼루션 레이어의 인덱스를 출력합니다.
for i, layer in enumerate(conv_mixer_model.layers):
if isinstance(layer, layers.DepthwiseConv2D):
if layer.get_config()["kernel_size"] == (5, 5):
print(i, layer)
idx = 26 # 네트워크 중간에서 커널을 가져옵니다.
kernel = conv_mixer_model.layers[idx].get_weights()[0]
kernel = np.expand_dims(kernel.squeeze(), axis=2)
visualization_plot(kernel)결과
5 <DepthwiseConv2D name=depthwise_conv2d, built=True>
12 <DepthwiseConv2D name=depthwise_conv2d_1, built=True>
19 <DepthwiseConv2D name=depthwise_conv2d_2, built=True>
26 <DepthwiseConv2D name=depthwise_conv2d_3, built=True>
33 <DepthwiseConv2D name=depthwise_conv2d_4, built=True>
40 <DepthwiseConv2D name=depthwise_conv2d_5, built=True>
47 <DepthwiseConv2D name=depthwise_conv2d_6, built=True>
54 <DepthwiseConv2D name=depthwise_conv2d_7, built=True>
커널의 필터마다 로컬리티 범위가 다르다는 것을 알 수 있으며, 이러한 패턴은 더 많은 트레이닝을 통해 진화할 가능성이 높습니다.
최종 메모
최근 컨볼루션을 셀프 어텐션과 같은 데이터에 구애받지 않는 다른 연산과 융합하는 경향이 있습니다. 다음 연구도 이러한 흐름의 연장선상에 있습니다:
- ConViT (d’Ascoli et al.)
- CCT (Hassani et al.)
- CoAtNet (Dai et al.)