FNet을 사용한 텍스트 생성
- 원본 링크 : https://keras.io/examples/generative/text_generation_fnet/
- 최종 확인 : 2024-11-23
저자 : Darshan Deshpande
생성일 : 2021/10/05
최종 편집일 : 2021/10/05
설명 : FNet Transformer를 사용한 Keras의 텍스트 생성
소개
원본 트랜스포머 구현(Vaswani et al., 2017)은 자연어 처리에서 주요한 돌파구 중 하나로, BERT와 GPT 같은 중요한 아키텍처의 기반이 되었습니다. 그러나, 이러한 아키텍처가 사용하는 셀프 어텐션 메커니즘은 계산 비용이 많이 듭니다. FNet 아키텍처는 이 셀프 어텐션을 더 간소화된 메커니즘으로 대체하는 것을 제안합니다. 그 메커니즘은 입력 토큰을 위한 푸리에 변환 기반의 선형 믹서입니다.
FNet 모델은 BERT의 정확도의 92-97%를 달성하면서도, GPU에서 80% 더 빠르게, TPU에서 거의 70% 더 빠르게 학습할 수 있었습니다. 이러한 설계는 효율적이고 작은 모델 크기를 제공하여, 더 빠른 추론 시간을 제공합니다.
이 예제에서는 이 아키텍처를 구현하고, Cornell Movie Dialog 코퍼스에서 텍스트 생성을 위해 이 모델을 트레이닝하는 방법을 보여드리겠습니다.
Imports
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import os
# 하이퍼파라미터 정의
VOCAB_SIZE = 8192
MAX_SAMPLES = 50000
BUFFER_SIZE = 20000
MAX_LENGTH = 40
EMBED_DIM = 256
LATENT_DIM = 512
NUM_HEADS = 8
BATCH_SIZE = 64데이터 로드
우리는 Cornell Dialog Corpus를 사용하여, 영화 대화를 질문과 답변 세트로 파싱할 것입니다.
path_to_zip = keras.utils.get_file(
"cornell_movie_dialogs.zip",
origin="http://www.cs.cornell.edu/~cristian/data/cornell_movie_dialogs_corpus.zip",
extract=True,
)
path_to_dataset = os.path.join(
os.path.dirname(path_to_zip), "cornell movie-dialogs corpus"
)
path_to_movie_lines = os.path.join(path_to_dataset, "movie_lines.txt")
path_to_movie_conversations = os.path.join(path_to_dataset, "movie_conversations.txt")
def load_conversations():
# 대화 데이터(conversation splits)를 불러오는 보조 함수
id2line = {}
with open(path_to_movie_lines, errors="ignore") as file:
lines = file.readlines()
for line in lines:
parts = line.replace("\n", "").split(" +++$+++ ")
id2line[parts[0]] = parts[4]
inputs, outputs = [], []
with open(path_to_movie_conversations, "r") as file:
lines = file.readlines()
for line in lines:
parts = line.replace("\n", "").split(" +++$+++ ")
# 대화를 라인 ID 목록으로 변환
conversation = [line[1:-1] for line in parts[3][1:-1].split(", ")]
for i in range(len(conversation) - 1):
inputs.append(id2line[conversation[i]])
outputs.append(id2line[conversation[i + 1]])
if len(inputs) >= MAX_SAMPLES:
return inputs, outputs
return inputs, outputs
questions, answers = load_conversations()
# 트레이닝 및 검증 세트로 분리
train_dataset = tf.data.Dataset.from_tensor_slices((questions[:40000], answers[:40000]))
val_dataset = tf.data.Dataset.from_tensor_slices((questions[40000:], answers[40000:]))결과
Downloading data from http://www.cs.cornell.edu/~cristian/data/cornell_movie_dialogs_corpus.zip
9920512/9916637 [==============================] - 0s 0us/step
9928704/9916637 [==============================] - 0s 0us/step전처리 및 토크나이제이션
def preprocess_text(sentence):
sentence = tf.strings.lower(sentence)
# 구두점과 마지막 단어 사이에 공백을 추가하여 더 나은 토크나이제이션을 허용
sentence = tf.strings.regex_replace(sentence, r"([?.!,])", r" \1 ")
# 연속적인 여러 공백을 하나의 공백으로 대체
sentence = tf.strings.regex_replace(sentence, r"\s\s+", " ")
# 영어가 아닌 단어를 공백으로 대체
sentence = tf.strings.regex_replace(sentence, r"[^a-z?.!,]+", " ")
sentence = tf.strings.strip(sentence)
sentence = tf.strings.join(["[start]", sentence, "[end]"], separator=" ")
return sentence
vectorizer = layers.TextVectorization(
VOCAB_SIZE,
standardize=preprocess_text,
output_mode="int",
output_sequence_length=MAX_LENGTH,
)
# 질문과 답변 모두에 대해 벡터라이저를 적응시킵니다.
# 이 데이터셋은 병렬 처리와 속도 향상을 위해 배치로 됩니다.
vectorizer.adapt(tf.data.Dataset.from_tensor_slices((questions + answers)).batch(128))TextVectorization을 사용하여 문장 토크나이즈 및 패딩
def vectorize_text(inputs, outputs):
inputs, outputs = vectorizer(inputs), vectorizer(outputs)
# 출력 모양과 일치하도록 하나의 추가 패딩 토큰을 오른쪽에 추가
outputs = tf.pad(outputs, [[0, 1]])
return (
{"encoder_inputs": inputs, "decoder_inputs": outputs[:-1]},
{"outputs": outputs[1:]},
)
train_dataset = train_dataset.map(vectorize_text, num_parallel_calls=tf.data.AUTOTUNE)
val_dataset = val_dataset.map(vectorize_text, num_parallel_calls=tf.data.AUTOTUNE)
train_dataset = (
train_dataset.cache()
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.prefetch(tf.data.AUTOTUNE)
)
val_dataset = val_dataset.cache().batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)FNet 인코더 만들기
FNet 논문은 Transformer 아키텍처(Vaswani et al., 2017)에서 사용되는 표준 어텐션 메커니즘을 대체하는 방법을 제안합니다.
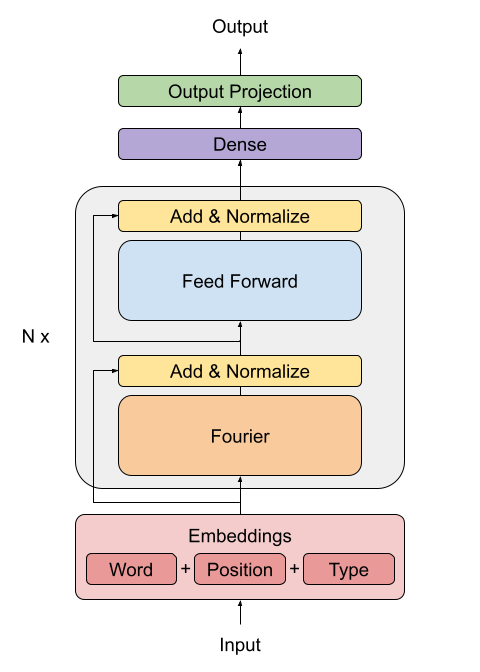
FFT 레이어의 출력은 복소수입니다. 복잡한 레이어를 처리하는 것을 피하기 위해, 오직 실수 부분(크기)만 추출됩니다.
푸리에 변환 후의 dense 레이어는 주파수 도메인에서 적용되는 합성곱(컨볼루션)과 같은 역할을 합니다.
class FNetEncoder(layers.Layer):
def __init__(self, embed_dim, dense_dim, **kwargs):
super().__init__(**kwargs)
self.embed_dim = embed_dim
self.dense_dim = dense_dim
self.dense_proj = keras.Sequential(
[
layers.Dense(dense_dim, activation="relu"),
layers.Dense(embed_dim),
]
)
self.layernorm_1 = layers.LayerNormalization()
self.layernorm_2 = layers.LayerNormalization()
def call(self, inputs):
# 입력을 complex64로 캐스팅
inp_complex = tf.cast(inputs, tf.complex64)
# 입력을 FFT2D를 사용하여 주파수 도메인으로 프로젝션하고, 출력의 실수 부분을 추출
fft = tf.math.real(tf.signal.fft2d(inp_complex))
proj_input = self.layernorm_1(inputs + fft)
proj_output = self.dense_proj(proj_input)
return self.layernorm_2(proj_input + proj_output)디코더 만들기
디코더 아키텍처는 원본 Transformer 아키텍처(Vaswani et al., 2017)에서 제안된 것과 동일하게 유지됩니다. 이 아키텍처는 임베딩, 위치 인코딩, 두 개의 마스킹된 멀티헤드 어텐션 레이어와 마지막으로 dense 출력 레이어로 구성됩니다. 아래의 아키텍처는 Deep Learning with Python, second edition, chapter 11에서 가져왔습니다.
class PositionalEmbedding(layers.Layer):
def __init__(self, sequence_length, vocab_size, embed_dim, **kwargs):
super().__init__(**kwargs)
self.token_embeddings = layers.Embedding(
input_dim=vocab_size, output_dim=embed_dim
)
self.position_embeddings = layers.Embedding(
input_dim=sequence_length, output_dim=embed_dim
)
self.sequence_length = sequence_length
self.vocab_size = vocab_size
self.embed_dim = embed_dim
def call(self, inputs):
length = tf.shape(inputs)[-1]
positions = tf.range(start=0, limit=length, delta=1)
embedded_tokens = self.token_embeddings(inputs)
embedded_positions = self.position_embeddings(positions)
return embedded_tokens + embedded_positions
def compute_mask(self, inputs, mask=None):
return tf.math.not_equal(inputs, 0)
class FNetDecoder(layers.Layer):
def __init__(self, embed_dim, latent_dim, num_heads, **kwargs):
super().__init__(**kwargs)
self.embed_dim = embed_dim
self.latent_dim = latent_dim
self.num_heads = num_heads
self.attention_1 = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim
)
self.attention_2 = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim
)
self.dense_proj = keras.Sequential(
[
layers.Dense(latent_dim, activation="relu"),
layers.Dense(embed_dim),
]
)
self.layernorm_1 = layers.LayerNormalization()
self.layernorm_2 = layers.LayerNormalization()
self.layernorm_3 = layers.LayerNormalization()
self.supports_masking = True
def call(self, inputs, encoder_outputs, mask=None):
causal_mask = self.get_causal_attention_mask(inputs)
if mask is not None:
padding_mask = tf.cast(mask[:, tf.newaxis, :], dtype="int32")
padding_mask = tf.minimum(padding_mask, causal_mask)
attention_output_1 = self.attention_1(
query=inputs, value=inputs, key=inputs, attention_mask=causal_mask
)
out_1 = self.layernorm_1(inputs + attention_output_1)
attention_output_2 = self.attention_2(
query=out_1,
value=encoder_outputs,
key=encoder_outputs,
attention_mask=padding_mask,
)
out_2 = self.layernorm_2(out_1 + attention_output_2)
proj_output = self.dense_proj(out_2)
return self.layernorm_3(out_2 + proj_output)
def get_causal_attention_mask(self, inputs):
input_shape = tf.shape(inputs)
batch_size, sequence_length = input_shape[0], input_shape[1]
i = tf.range(sequence_length)[:, tf.newaxis]
j = tf.range(sequence_length)
mask = tf.cast(i >= j, dtype="int32")
mask = tf.reshape(mask, (1, input_shape[1], input_shape[1]))
mult = tf.concat(
[tf.expand_dims(batch_size, -1), tf.constant([1, 1], dtype=tf.int32)],
axis=0,
)
return tf.tile(mask, mult)
def create_model():
encoder_inputs = keras.Input(shape=(None,), dtype="int32", name="encoder_inputs")
x = PositionalEmbedding(MAX_LENGTH, VOCAB_SIZE, EMBED_DIM)(encoder_inputs)
encoder_outputs = FNetEncoder(EMBED_DIM, LATENT_DIM)(x)
encoder = keras.Model(encoder_inputs, encoder_outputs)
decoder_inputs = keras.Input(shape=(None,), dtype="int32", name="decoder_inputs")
encoded_seq_inputs = keras.Input(
shape=(None, EMBED_DIM), name="decoder_state_inputs"
)
x = PositionalEmbedding(MAX_LENGTH, VOCAB_SIZE, EMBED_DIM)(decoder_inputs)
x = FNetDecoder(EMBED_DIM, LATENT_DIM, NUM_HEADS)(x, encoded_seq_inputs)
x = layers.Dropout(0.5)(x)
decoder_outputs = layers.Dense(VOCAB_SIZE, activation="softmax")(x)
decoder = keras.Model(
[decoder_inputs, encoded_seq_inputs], decoder_outputs, name="outputs"
)
decoder_outputs = decoder([decoder_inputs, encoder_outputs])
fnet = keras.Model([encoder_inputs, decoder_inputs], decoder_outputs, name="fnet")
return fnet모델 생성 및 트레이닝
fnet = create_model()
fnet.compile("adam", loss="sparse_categorical_crossentropy", metrics=["accuracy"])여기에서 epochs 매개변수는 한 번의 에포크로 설정되어 있지만,
실제로는 모델이 이해할 수 있는 문장을 출력하기까지 20-30 에포크 정도의 트레이닝이 필요합니다.
정확성은 이 작업에 적합한 척도는 아니지만, 네트워크의 개선 정도를 확인하기 위해 사용합니다.
fnet.fit(train_dataset, epochs=1, validation_data=val_dataset)결과
625/625 [==============================] - 96s 133ms/step - loss: 1.3036 - accuracy: 0.4354 - val_loss: 0.7964 - val_accuracy: 0.6374
<keras.callbacks.History at 0x7f0d8d214c90>추론 수행
VOCAB = vectorizer.get_vocabulary()
def decode_sentence(input_sentence):
# 입력 문장을 토큰으로 매핑하고 시작과 끝 토큰을 추가
tokenized_input_sentence = vectorizer(
tf.constant("[start] " + preprocess_text(input_sentence) + " [end]")
)
# 시작 토큰만 포함하는 초기 문장 초기화
tokenized_target_sentence = tf.expand_dims(VOCAB.index("[start]"), 0)
decoded_sentence = ""
for i in range(MAX_LENGTH):
# 예측값 가져오기
predictions = fnet.predict(
{
"encoder_inputs": tf.expand_dims(tokenized_input_sentence, 0),
"decoder_inputs": tf.expand_dims(
tf.pad(
tokenized_target_sentence,
[[0, MAX_LENGTH - tf.shape(tokenized_target_sentence)[0]]],
),
0,
),
}
)
# 최대 확률을 가진 토큰 계산 후, 해당 단어 가져오기
sampled_token_index = tf.argmax(predictions[0, i, :])
sampled_token = VOCAB[sampled_token_index.numpy()]
# 샘플링된 토큰이 끝 토큰이면, 문장 생성을 멈추고 반환
if tf.equal(sampled_token_index, VOCAB.index("[end]")):
break
decoded_sentence += sampled_token + " "
tokenized_target_sentence = tf.concat(
[tokenized_target_sentence, [sampled_token_index]], 0
)
return decoded_sentence
decode_sentence("Where have you been all this time?")결과
'i m sorry .'결론
이 예시는 FNet 모델을 사용하여 트레이닝 및 추론을 수행하는 방법을 보여줍니다. 아키텍처에 대한 통찰을 얻거나 더 깊이 읽어보고 싶다면, 다음 자료들을 참고하세요:
- FNet: Mixing Tokens with Fourier Transforms (Lee-Thorp et al., 2021)
- Attention Is All You Need (Vaswani et al., 2017)
Keras의 영어에서 스페인어로의 시퀀스-투-시퀀스 번역 Transformer 예제를 제공한 François Chollet에게 감사드립니다. 디코더 구현은 해당 예제에서 추출되었습니다.