Stable Diffusion으로 잠재 공간 걷기
- 원본 링크 : https://keras.io/examples/generative/random_walks_with_stable_diffusion/
- 최종 확인 : 2024-11-22
저자 : Ian Stenbit, fchollet, lukewood
생성일 : 2022/09/28
최종 편집일 : 2022/09/28
설명 : Stable Diffusion의 잠재 매니폴드를 탐색해 보십시오.
개요
생성 이미지 모델은 시각 세계의 “잠재적 매니폴드(latent manifold)“를 학습합니다. 이는 각 지점이 이미지에 매핑되는 저차원 벡터 공간입니다. 매니폴드의 이러한 지점에서 표시 가능한 이미지로 돌아가는 것을 “디코딩(decoding)“이라고 합니다. Stable Diffusion 모델에서는 “디코더(decoder)” 모델이 이를 처리합니다.
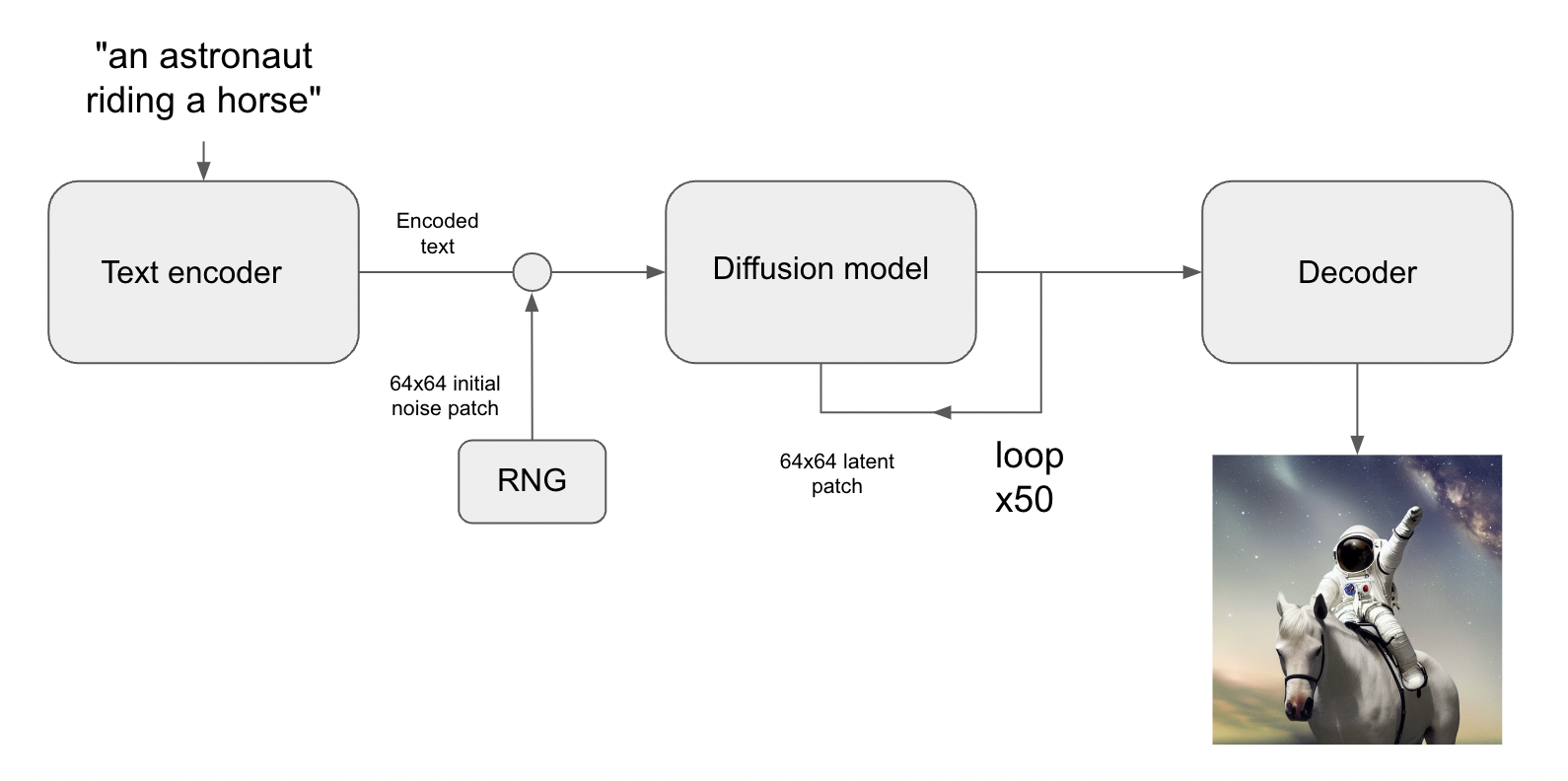
이 이미지의 잠재 매니폴드는 연속적이고 보간적입니다. 즉, 다음을 의미합니다.
- 매니폴드에서 약간만 움직여도, 해당 이미지가 약간만 변경됩니다. (연속성)
- 매니폴드의 두 점 A와 B(즉, 두 이미지)에 대해, 각 중간 지점이 매니폴드에 있는(즉, 유효한 이미지이기도 한) 경로를 통해, A에서 B로 이동할 수 있습니다. 중간 지점은 두 시작 이미지 사이의 “보간"이라고 합니다.
그러나 Stable Diffusion은 이미지 모델일 뿐만 아니라, 자연어 모델이기도 합니다. 여기에는 두 개의 잠재 공간이 있습니다. (1) 즉, 트레이닝 중에 사용된 인코더가 학습한 이미지 표현 공간과, (2) 사전 트레이닝과 트레이닝 시간 미세 조정을 결합하여 학습한 프롬프트 잠재 공간입니다.
잠재 공간 워킹(Latent space walking) 또는 잠재 공간 탐사(latent space exploration) 는 잠재 공간에서 한 지점을 샘플링하고, 잠재 표현을 점진적으로 변경하는 프로세스입니다. 가장 일반적인 응용 프로그램은 각 샘플링된 지점이 디코더에 공급되고, 최종 애니메이션에 프레임으로 저장되는 애니메이션을 생성하는 것입니다. 고품질 잠재 표현의 경우, 이는 일관되게 보이는 애니메이션을 생성합니다. 이러한 애니메이션은 잠재 공간의 특성 맵에 대한 통찰력을 제공할 수 있으며, 궁극적으로 학습 프로세스의 개선으로 이어질 수 있습니다. 그러한 GIF 중 하나가 아래에 표시됩니다.

이 가이드에서는, KerasCV의 Stable Diffusion API를 활용하여, Stable Diffusion의 시각적 잠재 매니폴드와 텍스트 인코더의 잠재 매니폴드를 통한, 신속한 보간 및 원형 워크(circular walks)를 수행하는 방법을 보여드리겠습니다.
이 가이드에서는, 독자가 Stable Diffusion에 대한 높은 수준의 이해가 있다고 가정합니다. 아직 읽지 않았다면, Stable Diffusion 튜토리얼을 읽어보세요.
시작하려면, KerasCV를 가져와서 튜토리얼 Stable Diffusion으로 이미지 생성에서 설명한 최적화를 사용하여, Stable Diffusion 모델을 로드합니다. M1 Mac GPU로 실행하는 경우 혼합 정밀도(mixed precision)를 활성화해서는 안 됩니다.
!pip install keras-cv --upgrade --quietimport keras_cv
import keras
import matplotlib.pyplot as plt
from keras import ops
import numpy as np
import math
from PIL import Image
# 혼합 정밀도 활성화 (최신 NVIDIA GPU가 있는 경우에만 수행)
keras.mixed_precision.set_global_policy("mixed_float16")
# Stable 디퓨전 모델을 인스턴스화
model = keras_cv.models.StableDiffusion(jit_compile=True)결과
By using this model checkpoint, you acknowledge that its usage is subject to the terms of the CreativeML Open RAIL-M license at https://raw.githubusercontent.com/CompVis/stable-diffusion/main/LICENSE텍스트 프롬프트 간 보간
Stable Diffusion에서, 텍스트 프롬프트는 먼저 벡터로 인코딩되고, 이 인코딩은 디퓨전 프로세스를 안내하는 데 사용됩니다. 잠재 인코딩 벡터는 77x768(정말 큽니다!)의 모양을 가지고 있으며, Stable Diffusion에 텍스트 프롬프트를 제공하면, 잠재 매니폴드의 한 지점에서만 이미지를 생성합니다.
이 매니폴드를 더 자세히 살펴보려면, 두 텍스트 인코딩 사이를 보간하고, 보간된 지점에서 이미지를 생성할 수 있습니다.
prompt_1 = "A watercolor painting of a Golden Retriever at the beach"
prompt_2 = "A still life DSLR photo of a bowl of fruit"
interpolation_steps = 5
encoding_1 = ops.squeeze(model.encode_text(prompt_1))
encoding_2 = ops.squeeze(model.encode_text(prompt_2))
interpolated_encodings = ops.linspace(encoding_1, encoding_2, interpolation_steps)
# 잠재 매니폴드의 크기를 보여줍니다.
print(f"Encoding shape: {encoding_1.shape}")결과
Downloading data from https://github.com/openai/CLIP/blob/main/clip/bpe_simple_vocab_16e6.txt.gz?raw=true
1356917/1356917 ━━━━━━━━━━━━━━━━━━━━ 0s 0us/step
Downloading data from https://huggingface.co/fchollet/stable-diffusion/resolve/main/kcv_encoder.h5
492466864/492466864 ━━━━━━━━━━━━━━━━━━━━ 7s 0us/step
Encoding shape: (77, 768)인코딩을 보간한 후에는, 각 지점에서 이미지를 생성할 수 있습니다. 결과 이미지 간에 어느 정도 안정성을 유지하기 위해, 이미지 간에 디퓨전 노이즈를 일정하게 유지합니다.
seed = 12345
noise = keras.random.normal((512 // 8, 512 // 8, 4), seed=seed)
images = model.generate_image(
interpolated_encodings,
batch_size=interpolation_steps,
diffusion_noise=noise,
)결과
Downloading data from https://huggingface.co/fchollet/stable-diffusion/resolve/main/kcv_diffusion_model.h5
3439090152/3439090152 ━━━━━━━━━━━━━━━━━━━━ 26s 0us/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 173s 311ms/step
Downloading data from https://huggingface.co/fchollet/stable-diffusion/resolve/main/kcv_decoder.h5
198180272/198180272 ━━━━━━━━━━━━━━━━━━━━ 1s 0us/step이제 보간된 이미지를 생성했으니, 살펴보겠습니다!
이 튜토리얼 전체에서, 이미지 시퀀스를 gif로 내보내 시간적 맥락을 통해 쉽게 볼 수 있도록 합니다. 첫 번째 이미지와 마지막 이미지가 개념적으로 일치하지 않는 이미지 시퀀스의 경우, gif를 고무줄로 묶습니다.
Colab에서 실행 중인 경우, 다음을 실행하여 자신의 GIF를 볼 수 있습니다.
from IPython.display import Image as IImage
IImage("doggo-and-fruit-5.gif")def export_as_gif(filename, images, frames_per_second=10, rubber_band=False):
if rubber_band:
images += images[2:-1][::-1]
images[0].save(
filename,
save_all=True,
append_images=images[1:],
duration=1000 // frames_per_second,
loop=0,
)
export_as_gif(
"doggo-and-fruit-5.gif",
[Image.fromarray(img) for img in images],
frames_per_second=2,
rubber_band=True,
)
결과는 놀랍게 보일 수 있습니다. 일반적으로, 프롬프트 간 보간은 일관성 있는 이미지를 생성하고, 종종 두 프롬프트의 내용 간에 점진적인 개념 변화를 보여줍니다. 이는 시각적 세계의 자연스러운 구조를 면밀히 반영하는, 고품질 표현 공간을 나타냅니다.
이를 가장 잘 시각화하려면, 수백 개의 단계를 사용하여, 훨씬 더 세분화된 보간을 수행해야 합니다. 배치 크기를 작게 유지하려면(GPU에 OOM이 발생하지 않도록), 보간된 인코딩을 수동으로 배치해야 합니다.
interpolation_steps = 150
batch_size = 3
batches = interpolation_steps // batch_size
interpolated_encodings = ops.linspace(encoding_1, encoding_2, interpolation_steps)
batched_encodings = ops.split(interpolated_encodings, batches)
images = []
for batch in range(batches):
images += [
Image.fromarray(img)
for img in model.generate_image(
batched_encodings[batch],
batch_size=batch_size,
num_steps=25,
diffusion_noise=noise,
)
]
export_as_gif("doggo-and-fruit-150.gif", images, rubber_band=True)결과
25/25 ━━━━━━━━━━━━━━━━━━━━ 77s 204ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 214ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 205ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 208ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 211ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 205ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 215ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 203ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 212ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 204ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 211ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 204ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 215ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 204ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 208ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 210ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 203ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 214ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 204ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 205ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 213ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 204ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 211ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 205ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 216ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 205ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 207ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 209ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 204ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 213ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 205ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 205ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 213ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 203ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 212ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 208ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 205ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 213ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 204ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 208ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 212ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 205ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 213ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 205ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 205ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 214ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 204ms/step
결과 gif는 두 프롬프트 사이의 훨씬 더 명확하고 일관된 변화를 보여줍니다. 여러분만의 프롬프트를 시도하고 실험해보세요!
이 개념을 두 개 이상의 이미지로 확장할 수도 있습니다. 예를 들어, 네 개의 프롬프트 사이를 보간할 수 있습니다.
prompt_1 = "A watercolor painting of a Golden Retriever at the beach"
prompt_2 = "A still life DSLR photo of a bowl of fruit"
prompt_3 = "The eiffel tower in the style of starry night"
prompt_4 = "An architectural sketch of a skyscraper"
interpolation_steps = 6
batch_size = 3
batches = (interpolation_steps**2) // batch_size
encoding_1 = ops.squeeze(model.encode_text(prompt_1))
encoding_2 = ops.squeeze(model.encode_text(prompt_2))
encoding_3 = ops.squeeze(model.encode_text(prompt_3))
encoding_4 = ops.squeeze(model.encode_text(prompt_4))
interpolated_encodings = ops.linspace(
ops.linspace(encoding_1, encoding_2, interpolation_steps),
ops.linspace(encoding_3, encoding_4, interpolation_steps),
interpolation_steps,
)
interpolated_encodings = ops.reshape(
interpolated_encodings, (interpolation_steps**2, 77, 768)
)
batched_encodings = ops.split(interpolated_encodings, batches)
images = []
for batch in range(batches):
images.append(
model.generate_image(
batched_encodings[batch],
batch_size=batch_size,
diffusion_noise=noise,
)
)
def plot_grid(images, path, grid_size, scale=2):
fig, axs = plt.subplots(
grid_size, grid_size, figsize=(grid_size * scale, grid_size * scale)
)
fig.tight_layout()
plt.subplots_adjust(wspace=0, hspace=0)
plt.axis("off")
for ax in axs.flat:
ax.axis("off")
images = images.astype(int)
for i in range(min(grid_size * grid_size, len(images))):
ax = axs.flat[i]
ax.imshow(images[i].astype("uint8"))
ax.axis("off")
for i in range(len(images), grid_size * grid_size):
axs.flat[i].axis("off")
axs.flat[i].remove()
plt.savefig(
fname=path,
pad_inches=0,
bbox_inches="tight",
transparent=False,
dpi=60,
)
images = np.concatenate(images)
plot_grid(images, "4-way-interpolation.jpg", interpolation_steps)결과
50/50 ━━━━━━━━━━━━━━━━━━━━ 10s 209ms/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 10s 204ms/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 10s 209ms/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 11s 210ms/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 10s 210ms/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 10s 205ms/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 11s 210ms/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 10s 210ms/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 10s 208ms/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 10s 205ms/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 10s 210ms/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 11s 210ms/step
diffusion_noise 매개변수를 드롭하여,
디퓨전 노이즈가 변하도록 허용하면서 보간할 수도 있습니다.
images = []
for batch in range(batches):
images.append(model.generate_image(batched_encodings[batch], batch_size=batch_size))
images = np.concatenate(images)
plot_grid(images, "4-way-interpolation-varying-noise.jpg", interpolation_steps)결과
50/50 ━━━━━━━━━━━━━━━━━━━━ 11s 215ms/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 13s 254ms/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 12s 235ms/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 12s 230ms/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 11s 214ms/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 10s 210ms/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 10s 208ms/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 11s 210ms/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 10s 209ms/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 10s 208ms/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 10s 205ms/step
50/50 ━━━━━━━━━━━━━━━━━━━━ 11s 213ms/step
이어서 산책을 떠나볼까요!
텍스트 프롬프트를 둘러보기
다음 실험은 특정 프롬프트에 의해 생성된 지점에서 시작하여, 잠재 매니폴드 주위를 돌아다니는 것입니다.
walk_steps = 150
batch_size = 3
batches = walk_steps // batch_size
step_size = 0.005
encoding = ops.squeeze(
model.encode_text("The Eiffel Tower in the style of starry night")
)
# (77, 768)이 텍스트 인코딩의 모양임을 주목하세요.
delta = ops.ones_like(encoding) * step_size
walked_encodings = []
for step_index in range(walk_steps):
walked_encodings.append(encoding)
encoding += delta
walked_encodings = ops.stack(walked_encodings)
batched_encodings = ops.split(walked_encodings, batches)
images = []
for batch in range(batches):
images += [
Image.fromarray(img)
for img in model.generate_image(
batched_encodings[batch],
batch_size=batch_size,
num_steps=25,
diffusion_noise=noise,
)
]
export_as_gif("eiffel-tower-starry-night.gif", images, rubber_band=True)결과
25/25 ━━━━━━━━━━━━━━━━━━━━ 6s 228ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 205ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 210ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 204ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 214ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 208ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 210ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 204ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 214ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 204ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 207ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 214ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 205ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 212ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 209ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 205ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 218ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 210ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 210ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 215ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 207ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 214ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 207ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 213ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 209ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 218ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 205ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 209ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 210ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 214ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 216ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 213ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 205ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 218ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 210ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 210ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 217ms/step
놀랍지 않게도, 인코더의 잠재 매니폴드에서 너무 멀리 걸어가면,
일관성이 없어 보이는 이미지가 생성됩니다.
직접 프롬프트를 설정하고 step_size를 조정하여 워크의 크기를 늘리거나 줄여서 시도해 보세요.
워크의 크기가 커지면, 워크가 종종 매우 노이즈가 많은 이미지를 생성하는 영역으로 이어진다는 점에 유의하세요.
단일 프롬프트에 대한 디퓨전 노이즈 공간을 통한 원형 워크(circular walk)
마지막 실험은 하나의 프롬프트에 집중하고, 디퓨전 모델이 그 프롬프트에서 생성할 수 있는 다양한 이미지를 탐색하는 것입니다. 디퓨전 프로세스를 시딩하는 데 사용되는 노이즈를 제어하여 이를 수행합니다.
x와 y라는 두 개의 노이즈 구성 요소를 만들고,
0에서 2π까지 워크를 수행하여,
x 구성 요소의 코사인과 y 구성 요소의 사인을 합산하여 노이즈를 생성합니다.
이 접근 방식을 사용하면,
워크의 끝은 워크를 시작한 동일한 노이즈 입력에 도착하므로,
“루프 가능한” 결과를 얻습니다!
prompt = "An oil paintings of cows in a field next to a windmill in Holland"
encoding = ops.squeeze(model.encode_text(prompt))
walk_steps = 150
batch_size = 3
batches = walk_steps // batch_size
walk_noise_x = keras.random.normal(noise.shape, dtype="float64")
walk_noise_y = keras.random.normal(noise.shape, dtype="float64")
walk_scale_x = ops.cos(ops.linspace(0, 2, walk_steps) * math.pi)
walk_scale_y = ops.sin(ops.linspace(0, 2, walk_steps) * math.pi)
noise_x = ops.tensordot(walk_scale_x, walk_noise_x, axes=0)
noise_y = ops.tensordot(walk_scale_y, walk_noise_y, axes=0)
noise = ops.add(noise_x, noise_y)
batched_noise = ops.split(noise, batches)
images = []
for batch in range(batches):
images += [
Image.fromarray(img)
for img in model.generate_image(
encoding,
batch_size=batch_size,
num_steps=25,
diffusion_noise=batched_noise[batch],
)
]
export_as_gif("cows.gif", images)결과
25/25 ━━━━━━━━━━━━━━━━━━━━ 35s 216ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 205ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 216ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 204ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 210ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 208ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 205ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 215ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 204ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 207ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 214ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 213ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 207ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 205ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 216ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 209ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 212ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 205ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 216ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 209ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 213ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 212ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 207ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 218ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 207ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 211ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 210ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 217ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 204ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 208ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 214ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 212ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 207ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 215ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 212ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 209ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 205ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 216ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 205ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 206ms/step
25/25 ━━━━━━━━━━━━━━━━━━━━ 5s 214ms/step
자신만의 프롬프트와 unconditional_guidance_scale의 다양한 값을 사용해 실험해 보세요!
결론
Stable Diffusion은 단일 텍스트-이미지 생성보다 훨씬 더 많은 것을 제공합니다. 텍스트 인코더의 잠재 매니폴드와 디퓨전 모델의 노이즈 공간을 탐색하는 것은, 이 모델의 힘을 경험하는 두 가지 재미있는 방법이며, KerasCV는 이를 쉽게 만듭니다!