조건부 이미지 생성을 위한 GauGAN
- 원본 링크 : https://keras.io/examples/generative/gaugan/
- 최종 확인 : 2024-11-23
저자 : Soumik Rakshit, Sayak Paul
생성일 : 2021/12/26
최종 편집일 : 2022/01/03
설명 : 조건부 이미지 생성을 위한 GauGAN 구현.
소개
이 예시에서는, Spatially-Adaptive Normalization을 사용한 Semantic Image Synthesis에서 제안된 GauGAN 아키텍처의 구현을 소개합니다. 간략하게 말하자면, GauGAN은 생성적 적대 신경망(GAN)을 사용하여, 큐 이미지와 세그멘테이션 맵에 조건을 두고 현실적인 이미지를 생성합니다. 아래는 해당 아키텍처를 시각적으로 설명한 예시입니다. (이미지 출처):

GauGAN의 주요 구성 요소는 다음과 같습니다:
- SPADE (Spatially-Adaptive Normalization) : GauGAN의 저자들은 배치 정규화(Batch Normalization)와 같은 기존의 정규화 층이, 입력으로 제공된 세그멘테이션 맵에서 얻은 시맨틱 정보를 손실시킨다고 주장합니다. 이 문제를 해결하기 위해, 저자들은 SPADE라는, 공간 적응적인 affine 파라미터(스케일과 바이어스)를 학습하는데 적합한 정규화 레이어를 도입했습니다. 이는 각 시맨틱 레이블에 대해, 다른 스케일과 바이어스 파라미터 세트를 학습함으로써 이루어집니다.
- 변분 인코더(Variational encoder): 변분 오토인코더(Variational Autoencoders)에 영감을 받아, GauGAN은 변분 공식화를 사용하여 인코더가 큐(cue) 이미지에서 정규(가우시안) 분포의 평균과 분산을 학습합니다. 이 부분에서 GauGAN의 이름이 유래되었습니다. GauGAN의 생성자는 가우시안 분포에서 샘플링된 잠재변수(latent)와 원-핫 인코딩된 시맨틱 세그멘테이션 레이블 맵을 입력으로 받습니다. 큐 이미지는 스타일 이미지로 작용하여 생성자에 스타일리시한 생성을 유도합니다. 이 변분 공식화는 GauGAN이 이미지의 다양성과 충실도를 동시에 달성하는 데 도움이 됩니다.
- 멀티 스케일 패치 판별자(Multi-scale patch discriminator): PatchGAN 모델에 영감을 받아, GauGAN은 주어진 이미지를 패치 단위로 평가하고 평균 점수를 출력하는 판별자를 사용합니다.
이 예시를 진행하면서, 각 구성 요소에 대해 자세히 논의하겠습니다.
GauGAN에 대한 심층 리뷰는, 이 글을 참고하세요. 또한 공식 GauGAN 웹사이트에서, GauGAN의 창의적인 다양한 응용 프로그램을 확인해보는 것을 권장합니다. 이 예시는 독자가 GAN의 기본 개념에 이미 익숙하다고 가정합니다. 복습이 필요하다면, 다음 자료들이 유용할 수 있습니다:
- François Chollet의 “Deep Learning with Python” 책의 GAN에 관한 챕터.
- keras.io의 GAN 구현 예시들:
데이터 수집
GauGAN 모델을 학습하기 위해 Facades 데이터셋을 사용할 것입니다. 먼저 이를 다운로드해 보겠습니다.
!wget https://drive.google.com/uc?id=1q4FEjQg1YSb4mPx2VdxL7LXKYu3voTMj -O facades_data.zip
!unzip -q facades_data.zip결과
--2024-01-11 22:46:32-- https://drive.google.com/uc?id=1q4FEjQg1YSb4mPx2VdxL7LXKYu3voTMj
Resolving drive.google.com (drive.google.com)... 64.233.181.138, 64.233.181.102, 64.233.181.100, ...
Connecting to drive.google.com (drive.google.com)|64.233.181.138|:443... connected.
HTTP request sent, awaiting response... 303 See Other
Location: https://drive.usercontent.google.com/download?id=1q4FEjQg1YSb4mPx2VdxL7LXKYu3voTMj [following]
--2024-01-11 22:46:32-- https://drive.usercontent.google.com/download?id=1q4FEjQg1YSb4mPx2VdxL7LXKYu3voTMj
Resolving drive.usercontent.google.com (drive.usercontent.google.com)... 108.177.112.132, 2607:f8b0:4001:c12::84
Connecting to drive.usercontent.google.com (drive.usercontent.google.com)|108.177.112.132|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 26036052 (25M) [application/octet-stream]
Saving to: ‘facades_data.zip’
facades_data.zip 100%[===================>] 24.83M 94.3MB/s in 0.3s
2024-01-11 22:46:42 (94.3 MB/s) - ‘facades_data.zip’ saved [26036052/26036052]Imports
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import keras
from keras import ops
from keras import layers
from glob import glob데이터 분할
PATH = "./facades_data/"
SPLIT = 0.2
files = glob(PATH + "*.jpg")
np.random.shuffle(files)
split_index = int(len(files) * (1 - SPLIT))
train_files = files[:split_index]
val_files = files[split_index:]
print(f"Total samples: {len(files)}.")
print(f"Total training samples: {len(train_files)}.")
print(f"Total validation samples: {len(val_files)}.")결과
Total samples: 378.
Total training samples: 302.
Total validation samples: 76.데이터 로더
BATCH_SIZE = 4
IMG_HEIGHT = IMG_WIDTH = 256
NUM_CLASSES = 12
AUTOTUNE = tf.data.AUTOTUNE
def load(image_files, batch_size, is_train=True):
def _random_crop(
segmentation_map,
image,
labels,
crop_size=(IMG_HEIGHT, IMG_WIDTH),
):
crop_size = tf.convert_to_tensor(crop_size)
image_shape = tf.shape(image)[:2]
margins = image_shape - crop_size
y1 = tf.random.uniform(shape=(), maxval=margins[0], dtype=tf.int32)
x1 = tf.random.uniform(shape=(), maxval=margins[1], dtype=tf.int32)
y2 = y1 + crop_size[0]
x2 = x1 + crop_size[1]
cropped_images = []
images = [segmentation_map, image, labels]
for img in images:
cropped_images.append(img[y1:y2, x1:x2])
return cropped_images
def _load_data_tf(image_file, segmentation_map_file, label_file):
image = tf.image.decode_png(tf.io.read_file(image_file), channels=3)
segmentation_map = tf.image.decode_png(
tf.io.read_file(segmentation_map_file), channels=3
)
labels = tf.image.decode_bmp(tf.io.read_file(label_file), channels=0)
labels = tf.squeeze(labels)
image = tf.cast(image, tf.float32) / 127.5 - 1
segmentation_map = tf.cast(segmentation_map, tf.float32) / 127.5 - 1
return segmentation_map, image, labels
def _one_hot(segmentation_maps, real_images, labels):
labels = tf.one_hot(labels, NUM_CLASSES)
labels.set_shape((None, None, NUM_CLASSES))
return segmentation_maps, real_images, labels
segmentation_map_files = [
image_file.replace("images", "segmentation_map").replace("jpg", "png")
for image_file in image_files
]
label_files = [
image_file.replace("images", "segmentation_labels").replace("jpg", "bmp")
for image_file in image_files
]
dataset = tf.data.Dataset.from_tensor_slices(
(image_files, segmentation_map_files, label_files)
)
dataset = dataset.shuffle(batch_size * 10) if is_train else dataset
dataset = dataset.map(_load_data_tf, num_parallel_calls=AUTOTUNE)
dataset = dataset.map(_random_crop, num_parallel_calls=AUTOTUNE)
dataset = dataset.map(_one_hot, num_parallel_calls=AUTOTUNE)
dataset = dataset.batch(batch_size, drop_remainder=True)
return dataset
train_dataset = load(train_files, batch_size=BATCH_SIZE, is_train=True)
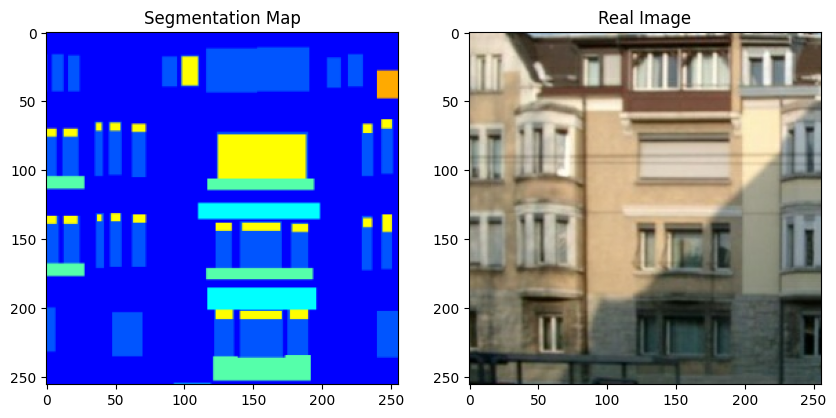
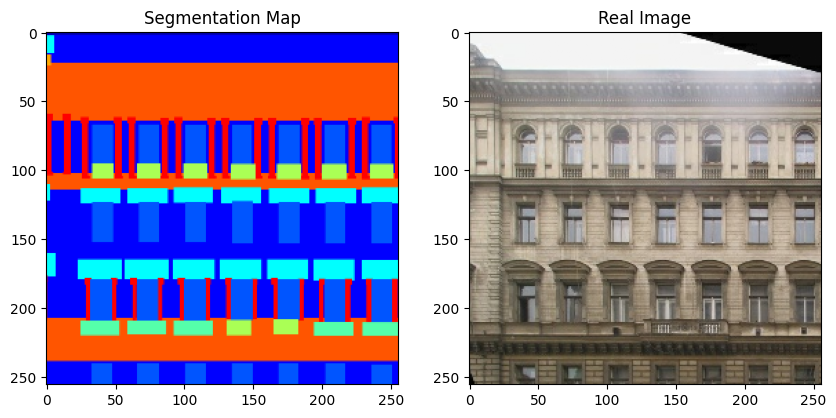
val_dataset = load(val_files, batch_size=BATCH_SIZE, is_train=False)이제 트레이닝 세트에서 몇 가지 샘플을 시각화해 보겠습니다.
sample_train_batch = next(iter(train_dataset))
print(f"Segmentation map batch shape: {sample_train_batch[0].shape}.")
print(f"Image batch shape: {sample_train_batch[1].shape}.")
print(f"One-hot encoded label map shape: {sample_train_batch[2].shape}.")
# 트레이닝 세트에서 몇 가지 샘플을 플롯합니다.
for segmentation_map, real_image in zip(sample_train_batch[0], sample_train_batch[1]):
fig = plt.figure(figsize=(10, 10))
fig.add_subplot(1, 2, 1).set_title("Segmentation Map")
plt.imshow((segmentation_map + 1) / 2)
fig.add_subplot(1, 2, 2).set_title("Real Image")
plt.imshow((real_image + 1) / 2)
plt.show()결과
Segmentation map batch shape: (4, 256, 256, 3).
Image batch shape: (4, 256, 256, 3).
One-hot encoded label map shape: (4, 256, 256, 12).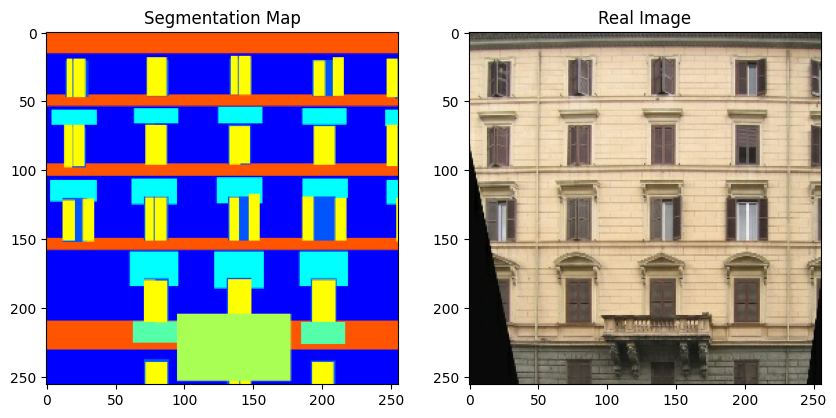
참고로, 이 예제의 나머지 부분에서는, 편의상 원본 GauGAN 논문의 몇 가지 그림을 사용합니다.
커스텀 레이어
다음 섹션에서는, 다음 레이어들을 구현합니다:
- SPADE
- SPADE를 포함한 Residual 블록
- Gaussian 샘플러
SPADE에 대한 추가 설명
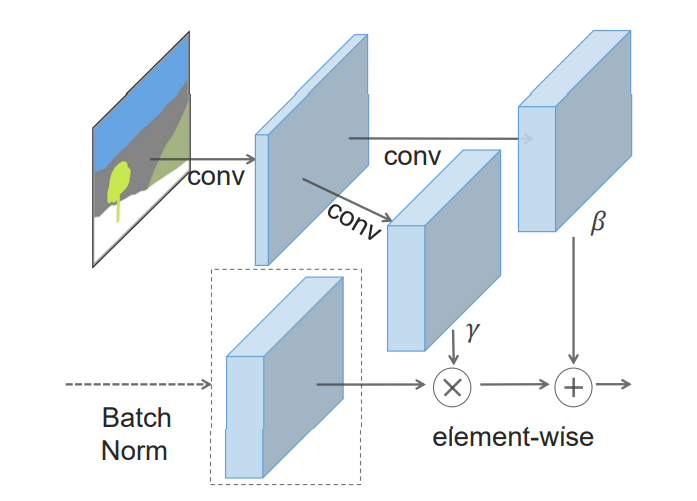
SPatially-Adaptive (DE) normalization 또는 SPADE는 입력된 시맨틱 레이아웃을 기반으로, 사진과 같은 이미지를 합성하는 데 효과적인 레이어입니다. 이전의 시맨틱 입력을 이용한 조건부 이미지 생성 방법 (예: Pix2Pix(Isola et al.) 또는 Pix2PixHD(Wang et al.))은 시맨틱 레이아웃을 딥 네트워크에 직접 입력으로 제공하고, 이를 여러 컨볼루션, 정규화, 비선형 레이어를 통해 처리합니다. 그러나, 이러한 방식은 정규화 레이어가 시맨틱 정보를 제거하는 경향이 있어 비효율적일 수 있습니다.
SPADE에서는 세그멘테이션 마스크가 먼저 임베딩 공간으로 프로젝션된 후,
컨볼루션을 통해 모듈레이션 매개변수 γ와 β를 생성합니다.
기존의 조건부 정규화 방법과 달리, γ와 β는 벡터가 아닌 공간 차원이 있는 텐서입니다.
생성된 γ와 β는 정규화된 활성화 값에 요소별로 곱해지고 더해집니다.
모듈레이션 매개변수가 입력 세그멘테이션 마스크에 적응하기 때문에, SPADE는 시맨틱 이미지 합성에 더 적합합니다.
class SPADE(layers.Layer):
def __init__(self, filters, epsilon=1e-5, **kwargs):
super().__init__(**kwargs)
self.epsilon = epsilon
self.conv = layers.Conv2D(128, 3, padding="same", activation="relu")
self.conv_gamma = layers.Conv2D(filters, 3, padding="same")
self.conv_beta = layers.Conv2D(filters, 3, padding="same")
def build(self, input_shape):
self.resize_shape = input_shape[1:3]
def call(self, input_tensor, raw_mask):
mask = ops.image.resize(raw_mask, self.resize_shape, interpolation="nearest")
x = self.conv(mask)
gamma = self.conv_gamma(x)
beta = self.conv_beta(x)
mean, var = ops.moments(input_tensor, axes=(0, 1, 2), keepdims=True)
std = ops.sqrt(var + self.epsilon)
normalized = (input_tensor - mean) / std
output = gamma * normalized + beta
return output
class ResBlock(layers.Layer):
def __init__(self, filters, **kwargs):
super().__init__(**kwargs)
self.filters = filters
def build(self, input_shape):
input_filter = input_shape[-1]
self.spade_1 = SPADE(input_filter)
self.spade_2 = SPADE(self.filters)
self.conv_1 = layers.Conv2D(self.filters, 3, padding="same")
self.conv_2 = layers.Conv2D(self.filters, 3, padding="same")
self.learned_skip = False
if self.filters != input_filter:
self.learned_skip = True
self.spade_3 = SPADE(input_filter)
self.conv_3 = layers.Conv2D(self.filters, 3, padding="same")
def call(self, input_tensor, mask):
x = self.spade_1(input_tensor, mask)
x = self.conv_1(keras.activations.leaky_relu(x, 0.2))
x = self.spade_2(x, mask)
x = self.conv_2(keras.activations.leaky_relu(x, 0.2))
skip = (
self.conv_3(
keras.activations.leaky_relu(self.spade_3(input_tensor, mask), 0.2)
)
if self.learned_skip
else input_tensor
)
output = skip + x
return output
class GaussianSampler(layers.Layer):
def __init__(self, batch_size, latent_dim, **kwargs):
super().__init__(**kwargs)
self.batch_size = batch_size
self.latent_dim = latent_dim
self.seed_generator = keras.random.SeedGenerator(1337)
def call(self, inputs):
means, variance = inputs
epsilon = keras.random.normal(
shape=(self.batch_size, self.latent_dim),
mean=0.0,
stddev=1.0,
seed=self.seed_generator,
)
samples = means + ops.exp(0.5 * variance) * epsilon
return samples다음으로, 인코더의 다운샘플링 블록을 구현합니다.
def downsample(
channels,
kernels,
strides=2,
apply_norm=True,
apply_activation=True,
apply_dropout=False,
):
block = keras.Sequential()
block.add(
layers.Conv2D(
channels,
kernels,
strides=strides,
padding="same",
use_bias=False,
kernel_initializer=keras.initializers.GlorotNormal(),
)
)
if apply_norm:
block.add(layers.GroupNormalization(groups=-1))
if apply_activation:
block.add(layers.LeakyReLU(0.2))
if apply_dropout:
block.add(layers.Dropout(0.5))
return blockGauGAN 인코더는 몇 가지 다운샘플링 블록으로 구성되며, 분포의 평균과 분산을 출력합니다.

def build_encoder(image_shape, encoder_downsample_factor=64, latent_dim=256):
input_image = keras.Input(shape=image_shape)
x = downsample(encoder_downsample_factor, 3, apply_norm=False)(input_image)
x = downsample(2 * encoder_downsample_factor, 3)(x)
x = downsample(4 * encoder_downsample_factor, 3)(x)
x = downsample(8 * encoder_downsample_factor, 3)(x)
x = downsample(8 * encoder_downsample_factor, 3)(x)
x = layers.Flatten()(x)
mean = layers.Dense(latent_dim, name="mean")(x)
variance = layers.Dense(latent_dim, name="variance")(x)
return keras.Model(input_image, [mean, variance], name="encoder")다음으로, 수정된 residual 블록과 업샘플링 블록으로 구성된 생성자를 구현합니다. 이 생성자는 잠재 벡터와 원-핫 인코딩된 세그멘테이션 레이블을 받아 새로운 이미지를 생성합니다.
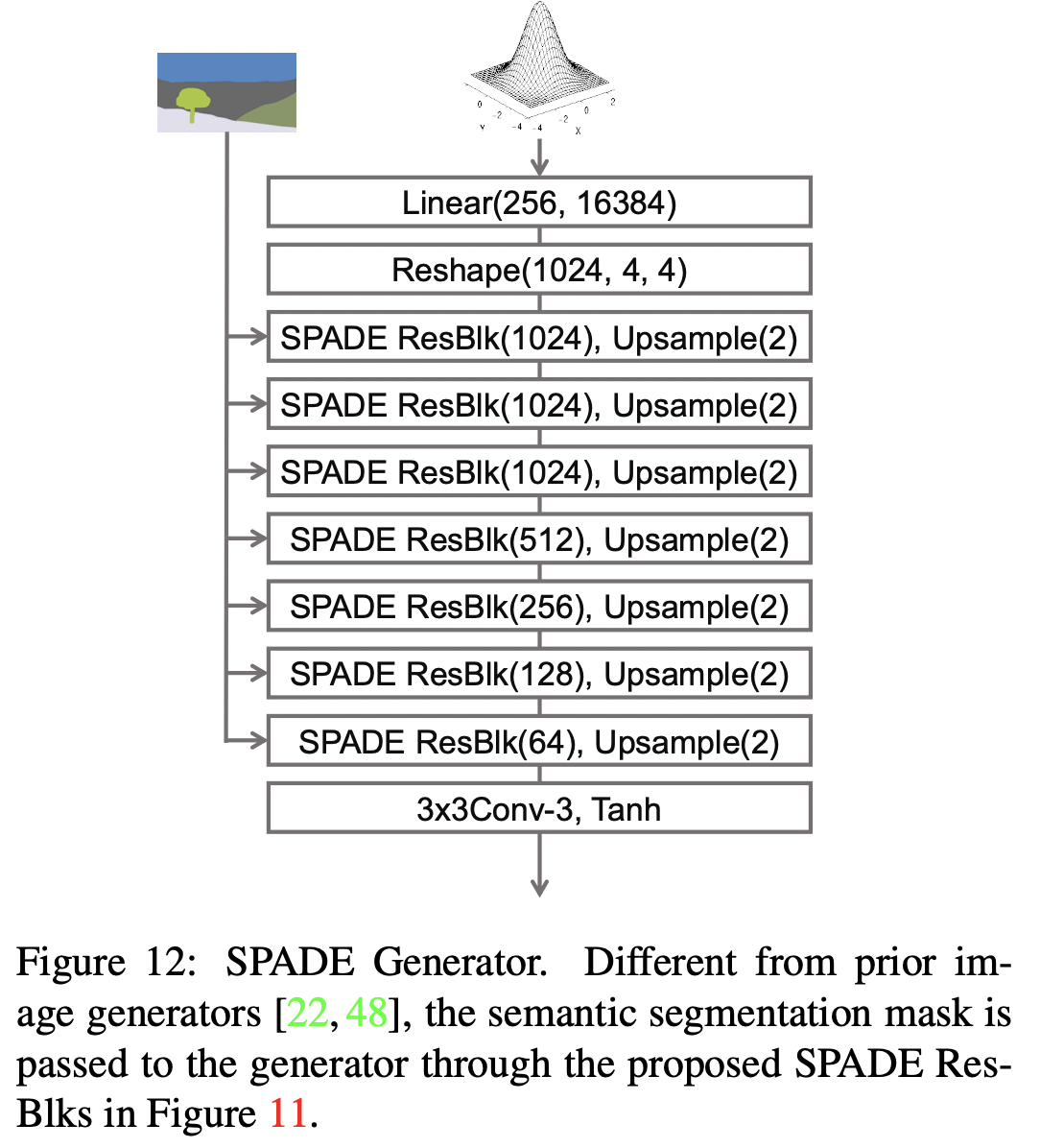
SPADE를 사용하면, 세그멘테이션 맵을 생성자의 첫 번째 레이어에 전달할 필요가 없습니다. 이는 잠재 입력이 생성자가 모방하고자 하는 스타일에 대한 충분한 구조적 정보를 가지고 있기 때문입니다. 또한 이전 아키텍처에서 흔히 사용되던 생성자의 인코더 부분을 제거합니다. 이로 인해 더 가벼운 생성자 네트워크가 완성되며, 랜덤 벡터를 입력으로 받아 여러 스타일의 이미지를 간단하게 생성할 수 있는 경로를 제공합니다.
def build_generator(mask_shape, latent_dim=256):
latent = keras.Input(shape=(latent_dim,))
mask = keras.Input(shape=mask_shape)
x = layers.Dense(16384)(latent)
x = layers.Reshape((4, 4, 1024))(x)
x = ResBlock(filters=1024)(x, mask)
x = layers.UpSampling2D((2, 2))(x)
x = ResBlock(filters=1024)(x, mask)
x = layers.UpSampling2D((2, 2))(x)
x = ResBlock(filters=1024)(x, mask)
x = layers.UpSampling2D((2, 2))(x)
x = ResBlock(filters=512)(x, mask)
x = layers.UpSampling2D((2, 2))(x)
x = ResBlock(filters=256)(x, mask)
x = layers.UpSampling2D((2, 2))(x)
x = ResBlock(filters=128)(x, mask)
x = layers.UpSampling2D((2, 2))(x)
x = keras.activations.leaky_relu(x, 0.2)
output_image = keras.activations.tanh(layers.Conv2D(3, 4, padding="same")(x))
return keras.Model([latent, mask], output_image, name="generator")판별자는 세그멘테이션 맵과 이미지를 결합한 후, 이 결합된 이미지가 진짜인지 가짜인지를 패치 단위로 예측합니다.

def build_discriminator(image_shape, downsample_factor=64):
input_image_A = keras.Input(shape=image_shape, name="discriminator_image_A")
input_image_B = keras.Input(shape=image_shape, name="discriminator_image_B")
x = layers.Concatenate()([input_image_A, input_image_B])
x1 = downsample(downsample_factor, 4, apply_norm=False)(x)
x2 = downsample(2 * downsample_factor, 4)(x1)
x3 = downsample(4 * downsample_factor, 4)(x2)
x4 = downsample(8 * downsample_factor, 4, strides=1)(x3)
x5 = layers.Conv2D(1, 4)(x4)
outputs = [x1, x2, x3, x4, x5]
return keras.Model([input_image_A, input_image_B], outputs)손실 함수
GauGAN은 다음과 같은 손실 함수를 사용합니다:
생성자:
- 판별자의 예측값에 대한 기대값.
- KL divergence
- 인코더가 예측한 평균과 분산을 학습하기 위한 것.
- 판별자의 예측값을 생성된 이미지와 원본 이미지에서 최소화하여, 생성자의 피처 공간을 정렬하는 것.
- Perceptual 손실
- 생성된 이미지가 시각적으로 질 높은 이미지를 생성하도록 유도하는 것.
판별자:
def generator_loss(y): return -ops.mean(y) def kl_divergence_loss(mean, variance): return -0.5 * ops.sum(1 + variance - ops.square(mean) - ops.exp(variance)) class FeatureMatchingLoss(keras.losses.Loss): def __init__(self, **kwargs): super().__init__(**kwargs) self.mae = keras.losses.MeanAbsoluteError() def call(self, y_true, y_pred): loss = 0 for i in range(len(y_true) - 1): loss += self.mae(y_true[i], y_pred[i]) return loss class VGGFeatureMatchingLoss(keras.losses.Loss): def __init__(self, **kwargs): super().__init__(**kwargs) self.encoder_layers = [ "block1_conv1", "block2_conv1", "block3_conv1", "block4_conv1", "block5_conv1", ] self.weights = [1.0 / 32, 1.0 / 16, 1.0 / 8, 1.0 / 4, 1.0] vgg = keras.applications.VGG19(include_top=False, weights="imagenet") layer_outputs = [vgg.get_layer(x).output for x in self.encoder_layers] self.vgg_model = keras.Model(vgg.input, layer_outputs, name="VGG") self.mae = keras.losses.MeanAbsoluteError() def call(self, y_true, y_pred): y_true = keras.applications.vgg19.preprocess_input(127.5 * (y_true + 1)) y_pred = keras.applications.vgg19.preprocess_input(127.5 * (y_pred + 1)) real_features = self.vgg_model(y_true) fake_features = self.vgg_model(y_pred) loss = 0 for i in range(len(real_features)): loss += self.weights[i] * self.mae(real_features[i], fake_features[i]) return loss class DiscriminatorLoss(keras.losses.Loss): def __init__(self, **kwargs): super().__init__(**kwargs) self.hinge_loss = keras.losses.Hinge() def call(self, y, is_real): return self.hinge_loss(is_real, y)
GAN 모니터 콜백
다음으로, GauGAN이 트레이닝 중일 때 결과를 모니터링할 콜백을 구현합니다.
class GanMonitor(keras.callbacks.Callback):
def __init__(self, val_dataset, n_samples, epoch_interval=5):
self.val_images = next(iter(val_dataset))
self.n_samples = n_samples
self.epoch_interval = epoch_interval
self.seed_generator = keras.random.SeedGenerator(42)
def infer(self):
latent_vector = keras.random.normal(
shape=(self.model.batch_size, self.model.latent_dim),
mean=0.0,
stddev=2.0,
seed=self.seed_generator,
)
return self.model.predict([latent_vector, self.val_images[2]])
def on_epoch_end(self, epoch, logs=None):
if epoch % self.epoch_interval == 0:
generated_images = self.infer()
for _ in range(self.n_samples):
grid_row = min(generated_images.shape[0], 3)
f, axarr = plt.subplots(grid_row, 3, figsize=(18, grid_row * 6))
for row in range(grid_row):
ax = axarr if grid_row == 1 else axarr[row]
ax[0].imshow((self.val_images[0][row] + 1) / 2)
ax[0].axis("off")
ax[0].set_title("Mask", fontsize=20)
ax[1].imshow((self.val_images[1][row] + 1) / 2)
ax[1].axis("off")
ax[1].set_title("Ground Truth", fontsize=20)
ax[2].imshow((generated_images[row] + 1) / 2)
ax[2].axis("off")
ax[2].set_title("Generated", fontsize=20)
plt.show()서브클래싱된 GauGAN 모델
마지막으로, 모든 것을 서브클래싱된 모델(tf.keras.Model로부터) 안에 넣고,
train_step() 메서드를 재정의합니다.
class GauGAN(keras.Model):
def __init__(
self,
image_size,
num_classes,
batch_size,
latent_dim,
feature_loss_coeff=10,
vgg_feature_loss_coeff=0.1,
kl_divergence_loss_coeff=0.1,
**kwargs,
):
super().__init__(**kwargs)
self.image_size = image_size
self.latent_dim = latent_dim
self.batch_size = batch_size
self.num_classes = num_classes
self.image_shape = (image_size, image_size, 3)
self.mask_shape = (image_size, image_size, num_classes)
self.feature_loss_coeff = feature_loss_coeff
self.vgg_feature_loss_coeff = vgg_feature_loss_coeff
self.kl_divergence_loss_coeff = kl_divergence_loss_coeff
self.discriminator = build_discriminator(self.image_shape)
self.generator = build_generator(self.mask_shape)
self.encoder = build_encoder(self.image_shape)
self.sampler = GaussianSampler(batch_size, latent_dim)
self.patch_size, self.combined_model = self.build_combined_generator()
self.disc_loss_tracker = keras.metrics.Mean(name="disc_loss")
self.gen_loss_tracker = keras.metrics.Mean(name="gen_loss")
self.feat_loss_tracker = keras.metrics.Mean(name="feat_loss")
self.vgg_loss_tracker = keras.metrics.Mean(name="vgg_loss")
self.kl_loss_tracker = keras.metrics.Mean(name="kl_loss")
@property
def metrics(self):
return [
self.disc_loss_tracker,
self.gen_loss_tracker,
self.feat_loss_tracker,
self.vgg_loss_tracker,
self.kl_loss_tracker,
]
def build_combined_generator(self):
# 이 메서드는 다음을 입력으로 받는 모델을 빌드합니다:
# latent 벡터, 원-핫 인코딩된 세그멘테이션 레이블 맵, 그리고 세그멘테이션 맵.
# 이 모델은 (i) 생성자를 사용해 이미지를 생성하고,
# (ii) 생성된 이미지와 세그멘테이션 맵을 판별자에 전달합니다.
# 마지막으로, 모델은 (a) 판별자 출력과 (b) 생성된 이미지를 출력합니다.
# 우리는 이 모델을 사용하여 구현을 단순화할 것입니다.
self.discriminator.trainable = False
mask_input = keras.Input(shape=self.mask_shape, name="mask")
image_input = keras.Input(shape=self.image_shape, name="image")
latent_input = keras.Input(shape=(self.latent_dim,), name="latent")
generated_image = self.generator([latent_input, mask_input])
discriminator_output = self.discriminator([image_input, generated_image])
combined_outputs = discriminator_output + [generated_image]
patch_size = discriminator_output[-1].shape[1]
combined_model = keras.Model(
[latent_input, mask_input, image_input], combined_outputs
)
return patch_size, combined_model
def compile(self, gen_lr=1e-4, disc_lr=4e-4, **kwargs):
super().compile(**kwargs)
self.generator_optimizer = keras.optimizers.Adam(
gen_lr, beta_1=0.0, beta_2=0.999
)
self.discriminator_optimizer = keras.optimizers.Adam(
disc_lr, beta_1=0.0, beta_2=0.999
)
self.discriminator_loss = DiscriminatorLoss()
self.feature_matching_loss = FeatureMatchingLoss()
self.vgg_loss = VGGFeatureMatchingLoss()
def train_discriminator(self, latent_vector, segmentation_map, real_image, labels):
fake_images = self.generator([latent_vector, labels])
with tf.GradientTape() as gradient_tape:
pred_fake = self.discriminator([segmentation_map, fake_images])[-1]
pred_real = self.discriminator([segmentation_map, real_image])[-1]
loss_fake = self.discriminator_loss(pred_fake, -1.0)
loss_real = self.discriminator_loss(pred_real, 1.0)
total_loss = 0.5 * (loss_fake + loss_real)
self.discriminator.trainable = True
gradients = gradient_tape.gradient(
total_loss, self.discriminator.trainable_variables
)
self.discriminator_optimizer.apply_gradients(
zip(gradients, self.discriminator.trainable_variables)
)
return total_loss
def train_generator(
self, latent_vector, segmentation_map, labels, image, mean, variance
):
# 생성자는 판별자가 제공하는 신호를 통해 학습합니다.
# 역전파 중에는, 생성자의 매개변수만 업데이트합니다.
self.discriminator.trainable = False
with tf.GradientTape() as tape:
real_d_output = self.discriminator([segmentation_map, image])
combined_outputs = self.combined_model(
[latent_vector, labels, segmentation_map]
)
fake_d_output, fake_image = combined_outputs[:-1], combined_outputs[-1]
pred = fake_d_output[-1]
# 생성자 손실 계산
g_loss = generator_loss(pred)
kl_loss = self.kl_divergence_loss_coeff * kl_divergence_loss(mean, variance)
vgg_loss = self.vgg_feature_loss_coeff * self.vgg_loss(image, fake_image)
feature_loss = self.feature_loss_coeff * self.feature_matching_loss(
real_d_output, fake_d_output
)
total_loss = g_loss + kl_loss + vgg_loss + feature_loss
all_trainable_variables = (
self.combined_model.trainable_variables + self.encoder.trainable_variables
)
gradients = tape.gradient(total_loss, all_trainable_variables)
self.generator_optimizer.apply_gradients(
zip(gradients, all_trainable_variables)
)
return total_loss, feature_loss, vgg_loss, kl_loss
def train_step(self, data):
segmentation_map, image, labels = data
mean, variance = self.encoder(image)
latent_vector = self.sampler([mean, variance])
discriminator_loss = self.train_discriminator(
latent_vector, segmentation_map, image, labels
)
(generator_loss, feature_loss, vgg_loss, kl_loss) = self.train_generator(
latent_vector, segmentation_map, labels, image, mean, variance
)
# 진행 상황 보고
self.disc_loss_tracker.update_state(discriminator_loss)
self.gen_loss_tracker.update_state(generator_loss)
self.feat_loss_tracker.update_state(feature_loss)
self.vgg_loss_tracker.update_state(vgg_loss)
self.kl_loss_tracker.update_state(kl_loss)
results = {m.name: m.result() for m in self.metrics}
return results
def test_step(self, data):
segmentation_map, image, labels = data
# 실제 이미지 분포에서 학습된 모멘트를 얻습니다.
mean, variance = self.encoder(image)
# 학습된 모멘트에서 latent 벡터를 샘플링합니다.
latent_vector = self.sampler([mean, variance])
# 가짜 이미지를 생성합니다.
fake_images = self.generator([latent_vector, labels])
# 손실을 계산합니다.
pred_fake = self.discriminator([segmentation_map, fake_images])[-1]
pred_real = self.discriminator([segmentation_map, image])[-1]
loss_fake = self.discriminator_loss(pred_fake, -1.0)
loss_real = self.discriminator_loss(pred_real, 1.0)
total_discriminator_loss = 0.5 * (loss_fake + loss_real)
real_d_output = self.discriminator([segmentation_map, image])
combined_outputs = self.combined_model(
[latent_vector, labels, segmentation_map]
)
fake_d_output, fake_image = combined_outputs[:-1], combined_outputs[-1]
pred = fake_d_output[-1]
g_loss = generator_loss(pred)
kl_loss = self.kl_divergence_loss_coeff * kl_divergence_loss(mean, variance)
vgg_loss = self.vgg_feature_loss_coeff * self.vgg_loss(image, fake_image)
feature_loss = self.feature_loss_coeff * self.feature_matching_loss(
real_d_output, fake_d_output
)
total_generator_loss = g_loss + kl_loss + vgg_loss + feature_loss
# 진행 상황을 보고합니다.
self.disc_loss_tracker.update_state(total_discriminator_loss)
self.gen_loss_tracker.update_state(total_generator_loss)
self.feat_loss_tracker.update_state(feature_loss)
self.vgg_loss_tracker.update_state(vgg_loss)
self.kl_loss_tracker.update_state(kl_loss)
results = {m.name: m.result() for m in self.metrics}
return results
def call(self, inputs):
latent_vectors, labels = inputs
return self.generator([latent_vectors, labels])GauGAN 트레이닝
gaugan = GauGAN(IMG_HEIGHT, NUM_CLASSES, BATCH_SIZE, latent_dim=256)
gaugan.compile()
history = gaugan.fit(
train_dataset,
validation_data=val_dataset,
epochs=15,
callbacks=[GanMonitor(val_dataset, BATCH_SIZE)],
)
def plot_history(item):
plt.plot(history.history[item], label=item)
plt.plot(history.history["val_" + item], label="val_" + item)
plt.xlabel("Epochs")
plt.ylabel(item)
plt.title("Train and Validation {} Over Epochs".format(item), fontsize=14)
plt.legend()
plt.grid()
plt.show()
plot_history("disc_loss")
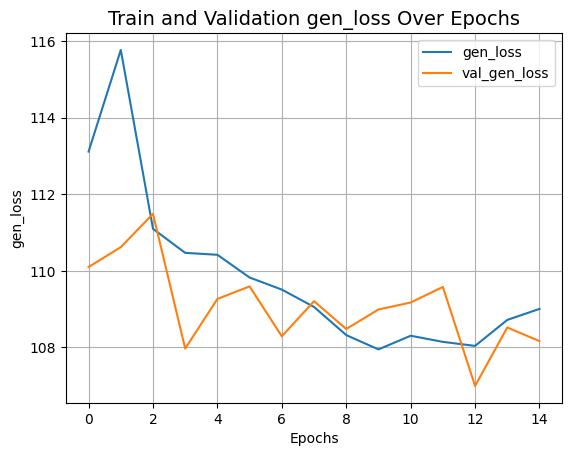
plot_history("gen_loss")
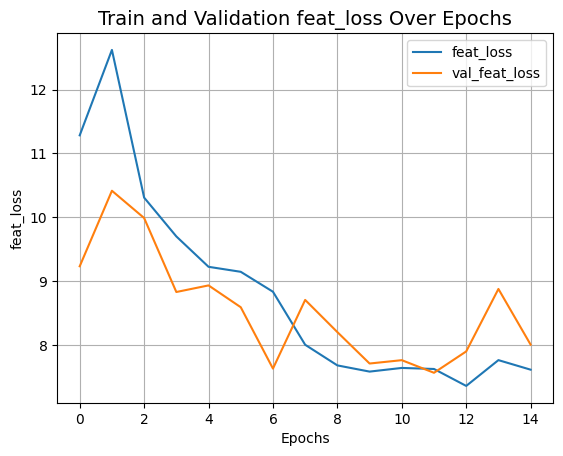
plot_history("feat_loss")
plot_history("vgg_loss")
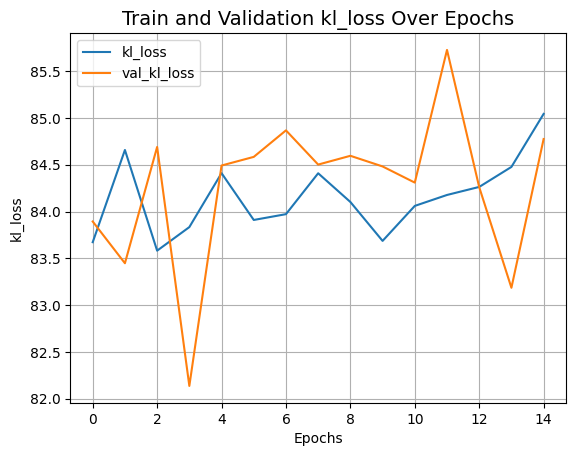
plot_history("kl_loss")결과
Epoch 1/15
/home/sineeli/anaconda3/envs/kerasv3/lib/python3.10/site-packages/keras/src/optimizers/base_optimizer.py:472: UserWarning: Gradients do not exist for variables ['kernel', 'kernel', 'gamma', 'beta', 'kernel', 'gamma', 'beta', 'kernel', 'gamma', 'beta', 'kernel', 'gamma', 'beta', 'kernel', 'bias', 'kernel', 'bias'] when minimizing the loss. If using `model.compile()`, did you forget to provide a `loss` argument?
warnings.warn(
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1705013303.976306 30381 device_compiler.h:186] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
W0000 00:00:1705013304.021899 30381 graph_launch.cc:671] Fallback to op-by-op mode because memset node breaks graph update
75/75 ━━━━━━━━━━━━━━━━━━━━ 0s 176ms/step - disc_loss: 1.3079 - feat_loss: 11.2902 - gen_loss: 113.0583 - kl_loss: 83.1424 - vgg_loss: 18.4966
W0000 00:00:1705013326.657730 30384 graph_launch.cc:671] Fallback to op-by-op mode because memset node breaks graph update
1/1 ━━━━━━━━━━━━━━━━━━━━ 3s 3s/step



75/75 ━━━━━━━━━━━━━━━━━━━━ 114s 426ms/step - disc_loss: 1.3051 - feat_loss: 11.2902 - gen_loss: 113.0590 - kl_loss: 83.1493 - vgg_loss: 18.4890 - val_disc_loss: 1.0374 - val_feat_loss: 9.2344 - val_gen_loss: 110.1001 - val_kl_loss: 83.8935 - val_vgg_loss: 16.6412
Epoch 2/15
75/75 ━━━━━━━━━━━━━━━━━━━━ 14s 193ms/step - disc_loss: 0.8257 - feat_loss: 12.6603 - gen_loss: 115.9798 - kl_loss: 84.4545 - vgg_loss: 18.2973 - val_disc_loss: 0.9296 - val_feat_loss: 10.4162 - val_gen_loss: 110.6182 - val_kl_loss: 83.4473 - val_vgg_loss: 16.5499
Epoch 3/15
75/75 ━━━━━━━━━━━━━━━━━━━━ 15s 194ms/step - disc_loss: 0.9126 - feat_loss: 10.4992 - gen_loss: 111.6962 - kl_loss: 83.8692 - vgg_loss: 17.0433 - val_disc_loss: 0.8875 - val_feat_loss: 9.9899 - val_gen_loss: 111.4879 - val_kl_loss: 84.6905 - val_vgg_loss: 16.4510
Epoch 4/15
75/75 ━━━━━━━━━━━━━━━━━━━━ 15s 194ms/step - disc_loss: 0.8975 - feat_loss: 9.9081 - gen_loss: 111.2489 - kl_loss: 84.3098 - vgg_loss: 16.7369 - val_disc_loss: 0.9266 - val_feat_loss: 8.8318 - val_gen_loss: 107.9712 - val_kl_loss: 82.1354 - val_vgg_loss: 16.2676
Epoch 5/15
75/75 ━━━━━━━━━━━━━━━━━━━━ 15s 194ms/step - disc_loss: 0.9378 - feat_loss: 9.1914 - gen_loss: 110.5359 - kl_loss: 84.7988 - vgg_loss: 16.3160 - val_disc_loss: 1.0073 - val_feat_loss: 8.9351 - val_gen_loss: 109.2667 - val_kl_loss: 84.4920 - val_vgg_loss: 16.3844
Epoch 6/15
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 35ms/step



75/75 ━━━━━━━━━━━━━━━━━━━━ 19s 258ms/step - disc_loss: 0.8982 - feat_loss: 9.2486 - gen_loss: 109.9399 - kl_loss: 83.8095 - vgg_loss: 16.5587 - val_disc_loss: 0.8061 - val_feat_loss: 8.5935 - val_gen_loss: 109.5937 - val_kl_loss: 84.5844 - val_vgg_loss: 15.8794
Epoch 7/15
75/75 ━━━━━━━━━━━━━━━━━━━━ 15s 194ms/step - disc_loss: 0.9048 - feat_loss: 9.1064 - gen_loss: 109.3803 - kl_loss: 83.8245 - vgg_loss: 16.0975 - val_disc_loss: 1.0096 - val_feat_loss: 7.6335 - val_gen_loss: 108.2900 - val_kl_loss: 84.8679 - val_vgg_loss: 15.9580
Epoch 8/15
75/75 ━━━━━━━━━━━━━━━━━━━━ 15s 193ms/step - disc_loss: 0.9075 - feat_loss: 8.0537 - gen_loss: 108.1771 - kl_loss: 83.6673 - vgg_loss: 16.1545 - val_disc_loss: 1.0090 - val_feat_loss: 8.7077 - val_gen_loss: 109.2079 - val_kl_loss: 84.5022 - val_vgg_loss: 16.3814
Epoch 9/15
75/75 ━━━━━━━━━━━━━━━━━━━━ 15s 194ms/step - disc_loss: 0.9053 - feat_loss: 7.7949 - gen_loss: 107.9268 - kl_loss: 83.6504 - vgg_loss: 16.1193 - val_disc_loss: 1.0663 - val_feat_loss: 8.2042 - val_gen_loss: 108.4819 - val_kl_loss: 84.5961 - val_vgg_loss: 16.0834
Epoch 10/15
75/75 ━━━━━━━━━━━━━━━━━━━━ 15s 194ms/step - disc_loss: 0.8905 - feat_loss: 7.7652 - gen_loss: 108.3079 - kl_loss: 83.8574 - vgg_loss: 16.2992 - val_disc_loss: 0.8362 - val_feat_loss: 7.7127 - val_gen_loss: 108.9906 - val_kl_loss: 84.4822 - val_vgg_loss: 16.0521
Epoch 11/15
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 30ms/step



75/75 ━━━━━━━━━━━━━━━━━━━━ 20s 263ms/step - disc_loss: 0.9047 - feat_loss: 7.5019 - gen_loss: 107.6317 - kl_loss: 83.6812 - vgg_loss: 16.1292 - val_disc_loss: 0.8788 - val_feat_loss: 7.7651 - val_gen_loss: 109.1731 - val_kl_loss: 84.3094 - val_vgg_loss: 16.0356
Epoch 12/15
75/75 ━━━━━━━━━━━━━━━━━━━━ 15s 194ms/step - disc_loss: 0.8899 - feat_loss: 7.5799 - gen_loss: 108.2313 - kl_loss: 84.4031 - vgg_loss: 15.9665 - val_disc_loss: 0.8358 - val_feat_loss: 7.5676 - val_gen_loss: 109.5789 - val_kl_loss: 85.7282 - val_vgg_loss: 16.0442
Epoch 13/15
75/75 ━━━━━━━━━━━━━━━━━━━━ 15s 194ms/step - disc_loss: 0.8542 - feat_loss: 7.3362 - gen_loss: 107.4649 - kl_loss: 83.6942 - vgg_loss: 16.0675 - val_disc_loss: 1.0853 - val_feat_loss: 7.9020 - val_gen_loss: 106.9958 - val_kl_loss: 84.2610 - val_vgg_loss: 15.8510
Epoch 14/15
75/75 ━━━━━━━━━━━━━━━━━━━━ 15s 194ms/step - disc_loss: 0.8631 - feat_loss: 7.6403 - gen_loss: 108.6401 - kl_loss: 84.5304 - vgg_loss: 16.0426 - val_disc_loss: 0.9516 - val_feat_loss: 8.8795 - val_gen_loss: 108.5215 - val_kl_loss: 83.1849 - val_vgg_loss: 16.3289
Epoch 15/15
75/75 ━━━━━━━━━━━━━━━━━━━━ 15s 194ms/step - disc_loss: 0.8939 - feat_loss: 7.5489 - gen_loss: 108.8330 - kl_loss: 85.0358 - vgg_loss: 15.9147 - val_disc_loss: 0.9616 - val_feat_loss: 8.0080 - val_gen_loss: 108.1650 - val_kl_loss: 84.7754 - val_vgg_loss: 15.9561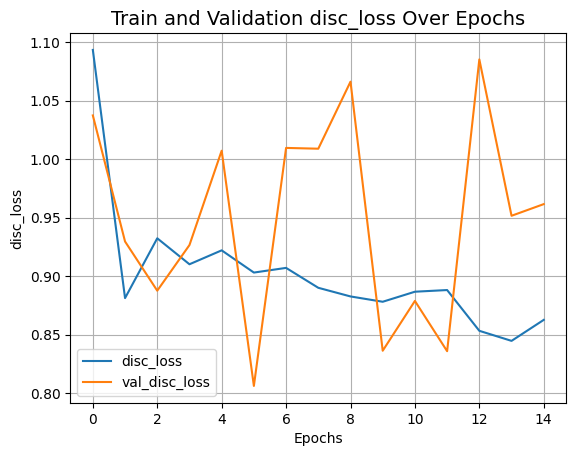

추론
val_iterator = iter(val_dataset)
for _ in range(5):
val_images = next(val_iterator)
# 정규 분포에서 latent 벡터를 샘플링합니다.
latent_vector = keras.random.normal(
shape=(gaugan.batch_size, gaugan.latent_dim), mean=0.0, stddev=2.0
)
# 가짜 이미지를 생성합니다.
fake_images = gaugan.predict([latent_vector, val_images[2]])
real_images = val_images
grid_row = min(fake_images.shape[0], 3)
grid_col = 3
f, axarr = plt.subplots(grid_row, grid_col, figsize=(grid_col * 6, grid_row * 6))
for row in range(grid_row):
ax = axarr if grid_row == 1 else axarr[row]
ax[0].imshow((real_images[0][row] + 1) / 2)
ax[0].axis("off")
ax[0].set_title("Mask", fontsize=20)
ax[1].imshow((real_images[1][row] + 1) / 2)
ax[1].axis("off")
ax[1].set_title("Ground Truth", fontsize=20)
ax[2].imshow((fake_images[row] + 1) / 2)
ax[2].axis("off")
ax[2].set_title("Generated", fontsize=20)
plt.show()결과
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 29ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 25ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 25ms/step
마지막 한마디
- 이 예제에서 사용된 데이터셋은 작은 규모입니다. 더 나은 결과를 얻으려면, 더 큰 데이터셋을 사용하는 것이 좋습니다. GauGAN 결과는 COCO-Stuff와 CityScapes 데이터셋을 사용해 입증되었습니다.
- 이 예제는 Soon-Yau Cheong의 Hands-On Image Generation with TensorFlow 책의 6장에서 영감을 받았으며, Divyansh Jha의 Implementing SPADE using fastai에서도 영감을 받았습니다.
- 이 예제가 흥미롭고 재미있다면, 우리의 레포지토리를 확인해 보세요. 우리는 현재 인기 있는 GAN과 사전 트레이닝된 모델을 다시 구현하고 있습니다. 우리의 목표는 코드의 가독성을 높이고 접근성을 개선하는 데 중점을 두는 것입니다. 우리는 먼저 이 예제 코드를 기반으로 한 GauGAN 구현을 더 큰 데이터셋으로 트레이닝한 후, 레포지토리를 공개할 계획입니다. 기여를 환영합니다!
- 최근 GauGAN2도 출시되었습니다. 여기에서 확인할 수 있습니다.
예제는 HuggingFace에서 확인 가능합니다.
| 트레이닝된 모델 | 데모 |
|---|---|