Conditional GAN
- 원본 링크 : https://keras.io/examples/generative/conditional_gan/
- 최종 확인 : 2024-11-23
저자 : Sayak Paul
생성일 : 2021/07/13
최종 편집일 : 2024/01/02
설명 : 클래스 레이블을 조건으로 GAN을 트레이닝하여 손으로 쓴 숫자를 생성합니다.
생성적 적대 신경망(GAN)을 사용하면 랜덤 입력에서 새로운 이미지 데이터, 비디오 데이터 또는 오디오 데이터를 생성할 수 있습니다. 일반적으로, 랜덤 입력은 정규 분포에서 샘플링한 다음, 그럴듯한 것(이미지, 비디오, 오디오 등)으로 변환하는 일련의 변환을 거칩니다.
그러나, 간단한 DCGAN에서는 생성하는 샘플의 모양(예: 클래스)을 제어할 수 없습니다. 예를 들어, MNIST 손으로 쓴 숫자를 생성하는 GAN의 경우, 간단한 DCGAN에서는 생성하는 숫자의 클래스를 선택할 수 없습니다. 생성하는 내용을 제어하려면, (이미지 클래스와 같은) 시맨틱 입력에 따라 GAN 출력을 조건해야 합니다.
이 예에서는, 주어진 클래스에 따라 MNIST 손으로 쓴 숫자를 생성할 수 있는 조건부 GAN(Conditional GAN) 을 빌드합니다. 이러한 모델은 다양한 유용한 응용 프로그램을 가질 수 있습니다.
- 불균형 이미지 데이터 세트를 다루고 있으며, 데이터 세트를 균형 잡기 위해 왜곡된 클래스에 대한 더 많은 예를 수집하고 싶다고 가정해 보겠습니다. 데이터 수집은 그 자체로 비용이 많이 드는 프로세스가 될 수 있습니다. 대신, 조건부 GAN을 트레이닝하여, 균형이 필요한 클래스에 대한 새로운 이미지를 생성하는 데 사용할 수 있습니다.
- 생성자는 생성된 샘플을 클래스 레이블과 연관시키는 법을 배우므로, 해당 표현은 다른 다운스트림 작업에도 사용할 수 있습니다.
다음은 이 예제를 개발하는 데 사용된 참고 자료입니다.
GAN에 대한 복습이 필요한 경우, 이 리소스의 “생성적 적대 신경망(Generative adversarial networks)” 섹션을 참조할 수 있습니다.
이 예제에는 TensorFlow 2.5 이상과 다음 명령을 사용하여 설치할 수 있는 TensorFlow Docs가 필요합니다.
!pip install -q git+https://github.com/tensorflow/docsImports
import keras
from keras import layers
from keras import ops
from tensorflow_docs.vis import embed
import tensorflow as tf
import numpy as np
import imageio상수와 하이퍼파라미터
batch_size = 64
num_channels = 1
num_classes = 10
image_size = 28
latent_dim = 128MNIST 데이터 세트 로딩 및 전처리
# 우리는 트레이닝 세트와 테스트 세트에서, 사용 가능한 모든 예를 사용할 것입니다.
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
all_digits = np.concatenate([x_train, x_test])
all_labels = np.concatenate([y_train, y_test])
# 픽셀 값을 [0, 1] 범위로 조정하고,
# 이미지에 채널 차원을 추가하고,
# 레이블을 원핫 인코딩합니다.
all_digits = all_digits.astype("float32") / 255.0
all_digits = np.reshape(all_digits, (-1, 28, 28, 1))
all_labels = keras.utils.to_categorical(all_labels, 10)
# tf.data.Dataset을 생성합니다.
dataset = tf.data.Dataset.from_tensor_slices((all_digits, all_labels))
dataset = dataset.shuffle(buffer_size=1024).batch(batch_size)
print(f"Shape of training images: {all_digits.shape}")
print(f"Shape of training labels: {all_labels.shape}")결과
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
11490434/11490434 ━━━━━━━━━━━━━━━━━━━━ 0s 0us/step
Shape of training images: (70000, 28, 28, 1)
Shape of training labels: (70000, 10)생성자와 판별자의 입력 채널 수 계산
일반 (조건없는) GAN에서, 우리는 정규 분포에서 (일부 고정된 차원의) 노이즈를 샘플링하는 것으로 시작합니다. 우리의 경우, 우리는 또한 클래스 레이블을 고려해야 합니다. 우리는 생성자(노이즈 입력)의 입력 채널과 판별자(생성된 이미지 입력)에 클래스 수를 추가해야 할 것입니다.
generator_in_channels = latent_dim + num_classes
discriminator_in_channels = num_channels + num_classes
print(generator_in_channels, discriminator_in_channels)결과
138 11판별자와 생성자 생성하기
모델 정의(discriminator, generator, ConditionalGAN)는
이 예제에서 가져왔습니다.
# 판별자를 만듭니다.
discriminator = keras.Sequential(
[
keras.layers.InputLayer((28, 28, discriminator_in_channels)),
layers.Conv2D(64, (3, 3), strides=(2, 2), padding="same"),
layers.LeakyReLU(negative_slope=0.2),
layers.Conv2D(128, (3, 3), strides=(2, 2), padding="same"),
layers.LeakyReLU(negative_slope=0.2),
layers.GlobalMaxPooling2D(),
layers.Dense(1),
],
name="discriminator",
)
# 생성자를 만듭니다.
generator = keras.Sequential(
[
keras.layers.InputLayer((generator_in_channels,)),
# 128 + num_classes 개의 계수를 생성하여,
# 7x7x(128 + num_classes) 맵으로 reshape하려고 합니다.
layers.Dense(7 * 7 * generator_in_channels),
layers.LeakyReLU(negative_slope=0.2),
layers.Reshape((7, 7, generator_in_channels)),
layers.Conv2DTranspose(128, (4, 4), strides=(2, 2), padding="same"),
layers.LeakyReLU(negative_slope=0.2),
layers.Conv2DTranspose(128, (4, 4), strides=(2, 2), padding="same"),
layers.LeakyReLU(negative_slope=0.2),
layers.Conv2D(1, (7, 7), padding="same", activation="sigmoid"),
],
name="generator",
)ConditionalGAN 모델 생성
class ConditionalGAN(keras.Model):
def __init__(self, discriminator, generator, latent_dim):
super().__init__()
self.discriminator = discriminator
self.generator = generator
self.latent_dim = latent_dim
self.seed_generator = keras.random.SeedGenerator(1337)
self.gen_loss_tracker = keras.metrics.Mean(name="generator_loss")
self.disc_loss_tracker = keras.metrics.Mean(name="discriminator_loss")
@property
def metrics(self):
return [self.gen_loss_tracker, self.disc_loss_tracker]
def compile(self, d_optimizer, g_optimizer, loss_fn):
super().compile()
self.d_optimizer = d_optimizer
self.g_optimizer = g_optimizer
self.loss_fn = loss_fn
def train_step(self, data):
# 데이터를 언팩합니다.
real_images, one_hot_labels = data
# 레이블에 더미 차원을 추가하여, 이미지와 연결(concatenated)할 수 있도록 합니다.
# 이는 판별자를 위한 것입니다.
image_one_hot_labels = one_hot_labels[:, :, None, None]
image_one_hot_labels = ops.repeat(
image_one_hot_labels, repeats=[image_size * image_size]
)
image_one_hot_labels = ops.reshape(
image_one_hot_labels, (-1, image_size, image_size, num_classes)
)
# 잠재 공간에서 랜덤 지점을 샘플링하고 레이블을 연결(concatenate)합니다.
# 이는 생성자를 위한 것입니다.
batch_size = ops.shape(real_images)[0]
random_latent_vectors = keras.random.normal(
shape=(batch_size, self.latent_dim), seed=self.seed_generator
)
random_vector_labels = ops.concatenate(
[random_latent_vectors, one_hot_labels], axis=1
)
# 노이즈(레이블에 따라)를 디코딩하여, 가짜 이미지를 만듭니다.
generated_images = self.generator(random_vector_labels)
# 실제 이미지와 결합합니다.
# 여기서는 이러한 이미지와 레이블을 연결(concatenating)하고 있다는 점에 유의하세요.
fake_image_and_labels = ops.concatenate(
[generated_images, image_one_hot_labels], -1
)
real_image_and_labels = ops.concatenate([real_images, image_one_hot_labels], -1)
combined_images = ops.concatenate(
[fake_image_and_labels, real_image_and_labels], axis=0
)
# 진짜 이미지와 가짜 이미지를 구별하는 라벨을 조립합니다.
labels = ops.concatenate(
[ops.ones((batch_size, 1)), ops.zeros((batch_size, 1))], axis=0
)
# 판별기를 트레이닝시킵니다.
with tf.GradientTape() as tape:
predictions = self.discriminator(combined_images)
d_loss = self.loss_fn(labels, predictions)
grads = tape.gradient(d_loss, self.discriminator.trainable_weights)
self.d_optimizer.apply_gradients(
zip(grads, self.discriminator.trainable_weights)
)
# 잠재 공간에서 랜덤 지점을 샘플링합니다.
random_latent_vectors = keras.random.normal(
shape=(batch_size, self.latent_dim), seed=self.seed_generator
)
random_vector_labels = ops.concatenate(
[random_latent_vectors, one_hot_labels], axis=1
)
# "모든 실제 이미지(all real images)"라고 적힌 라벨을 조립합니다.
misleading_labels = ops.zeros((batch_size, 1))
# 생성기를 트레이닝시킵니다. (판별기의 가중치는 업데이트해서는 *안 됩니다*!)
with tf.GradientTape() as tape:
fake_images = self.generator(random_vector_labels)
fake_image_and_labels = ops.concatenate(
[fake_images, image_one_hot_labels], -1
)
predictions = self.discriminator(fake_image_and_labels)
g_loss = self.loss_fn(misleading_labels, predictions)
grads = tape.gradient(g_loss, self.generator.trainable_weights)
self.g_optimizer.apply_gradients(zip(grads, self.generator.trainable_weights))
# 손실을 모니터링합니다.
self.gen_loss_tracker.update_state(g_loss)
self.disc_loss_tracker.update_state(d_loss)
return {
"g_loss": self.gen_loss_tracker.result(),
"d_loss": self.disc_loss_tracker.result(),
}Conditional GAN 트레이닝
cond_gan = ConditionalGAN(
discriminator=discriminator, generator=generator, latent_dim=latent_dim
)
cond_gan.compile(
d_optimizer=keras.optimizers.Adam(learning_rate=0.0003),
g_optimizer=keras.optimizers.Adam(learning_rate=0.0003),
loss_fn=keras.losses.BinaryCrossentropy(from_logits=True),
)
cond_gan.fit(dataset, epochs=20)결과
Epoch 1/20
18/1094 [37m━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6321 - g_loss: 0.7887
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1704233262.157522 6737 device_compiler.h:186] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 24s 14ms/step - d_loss: 0.4052 - g_loss: 1.5851 - discriminator_loss: 0.4390 - generator_loss: 1.4775
Epoch 2/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.5116 - g_loss: 1.2740 - discriminator_loss: 0.4872 - generator_loss: 1.3330
Epoch 3/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.3626 - g_loss: 1.6775 - discriminator_loss: 0.3252 - generator_loss: 1.8219
Epoch 4/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.2248 - g_loss: 2.2898 - discriminator_loss: 0.3418 - generator_loss: 2.0042
Epoch 5/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6017 - g_loss: 1.0428 - discriminator_loss: 0.6076 - generator_loss: 1.0176
Epoch 6/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6395 - g_loss: 0.9258 - discriminator_loss: 0.6448 - generator_loss: 0.9134
Epoch 7/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6402 - g_loss: 0.8914 - discriminator_loss: 0.6458 - generator_loss: 0.8773
Epoch 8/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6549 - g_loss: 0.8440 - discriminator_loss: 0.6555 - generator_loss: 0.8364
Epoch 9/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6603 - g_loss: 0.8316 - discriminator_loss: 0.6606 - generator_loss: 0.8241
Epoch 10/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6594 - g_loss: 0.8169 - discriminator_loss: 0.6605 - generator_loss: 0.8218
Epoch 11/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6719 - g_loss: 0.7979 - discriminator_loss: 0.6649 - generator_loss: 0.8096
Epoch 12/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6641 - g_loss: 0.7992 - discriminator_loss: 0.6621 - generator_loss: 0.7953
Epoch 13/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6657 - g_loss: 0.7979 - discriminator_loss: 0.6624 - generator_loss: 0.7924
Epoch 14/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6586 - g_loss: 0.8220 - discriminator_loss: 0.6566 - generator_loss: 0.8174
Epoch 15/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6646 - g_loss: 0.7916 - discriminator_loss: 0.6578 - generator_loss: 0.7973
Epoch 16/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6624 - g_loss: 0.7911 - discriminator_loss: 0.6587 - generator_loss: 0.7966
Epoch 17/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6586 - g_loss: 0.8060 - discriminator_loss: 0.6550 - generator_loss: 0.7997
Epoch 18/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6526 - g_loss: 0.7946 - discriminator_loss: 0.6523 - generator_loss: 0.7948
Epoch 19/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6525 - g_loss: 0.8039 - discriminator_loss: 0.6497 - generator_loss: 0.8066
Epoch 20/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6480 - g_loss: 0.8005 - discriminator_loss: 0.6469 - generator_loss: 0.8022
<keras.src.callbacks.history.History at 0x7f541a1b5f90>트레이닝된 생성자를 사용하여 클래스 간 보간
# 먼저 조건부 GAN에서 트레이닝된 생성자를 추출합니다.
trained_gen = cond_gan.generator
# interpolation + 2(시작 이미지와 마지막 이미지) 사이에 생성될 중간 이미지의 수를 선택합니다.
num_interpolation = 9 # @param {type:"integer"}
# 보간을 위한 샘플 노이즈입니다.
interpolation_noise = keras.random.normal(shape=(1, latent_dim))
interpolation_noise = ops.repeat(interpolation_noise, repeats=num_interpolation)
interpolation_noise = ops.reshape(interpolation_noise, (num_interpolation, latent_dim))
def interpolate_class(first_number, second_number):
# 시작 및 종료 라벨을 원핫 인코딩된 벡터로 변환합니다.
first_label = keras.utils.to_categorical([first_number], num_classes)
second_label = keras.utils.to_categorical([second_number], num_classes)
first_label = ops.cast(first_label, "float32")
second_label = ops.cast(second_label, "float32")
# 두 라벨 사이의 보간 벡터를 계산합니다.
percent_second_label = ops.linspace(0, 1, num_interpolation)[:, None]
percent_second_label = ops.cast(percent_second_label, "float32")
interpolation_labels = (
first_label * (1 - percent_second_label) + second_label * percent_second_label
)
# 노이즈와 라벨을 결합하고 생성자를 통해 추론을 실행합니다.
noise_and_labels = ops.concatenate([interpolation_noise, interpolation_labels], 1)
fake = trained_gen.predict(noise_and_labels)
return fake
start_class = 2 # @param {type:"slider", min:0, max:9, step:1}
end_class = 6 # @param {type:"slider", min:0, max:9, step:1}
fake_images = interpolate_class(start_class, end_class)결과
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 427ms/step여기서, 우리는 먼저 정규 분포에서 노이즈를 샘플링한 다음,
num_interpolation 번 반복하고 그에 따라 결과를 재구성합니다.
그런 다음 레이블 항등성이 어느 정도 비율로 존재하도록,
num_interpolation 동안 균일하게 분포합니다.
fake_images *= 255.0
converted_images = fake_images.astype(np.uint8)
converted_images = ops.image.resize(converted_images, (96, 96)).numpy().astype(np.uint8)
imageio.mimsave("animation.gif", converted_images[:, :, :, 0], fps=1)
embed.embed_file("animation.gif")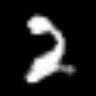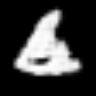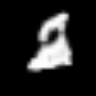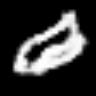
WGAN-GP와 같은 레시피를 사용하면, 이 모델의 성능을 더욱 개선할 수 있습니다. 조건 생성은 VQ-GAN, DALL-E 등과 같은, 많은 최신 이미지 생성 아키텍처에서도 널리 사용됩니다.
Hugging Face Hub에서 호스팅되는 트레이닝된 모델을 사용하고, Hugging Face Spaces에서 데모를 시도할 수 있습니다.