AdaIN을 사용한 신경 스타일 전송
- 원본 링크 : https://keras.io/examples/generative/adain/
- 최종 확인 : 2024-11-23
저자 : Aritra Roy Gosthipaty, Ritwik Raha
생성일 : 2021/11/08
최종 편집일 : 2021/11/08
설명 : Adaptive Instance Normalization을 사용한 신경 스타일 전송
소개
Neural Style Transfer은 하나의 이미지 스타일을 다른 이미지의 콘텐츠에 적용하는 과정입니다. 이는 Gatys et al.이 발표한 기념비적인 논문 “A Neural Algorithm of Artistic Style”에서 처음 소개되었습니다. 이 방법의 주요 한계는 알고리즘이 느린 반복 최적화 과정(slow iterative optimization process)을 사용한다는 점에서, 실행 시간이 오래 걸린다는 것입니다.
이후 Batch Normalization, Instance Normalization, Conditional Instance Normalization 등의 논문들이, Neural Style Transfer를 새로운 방식으로 수행할 수 있게 했으며, 더 이상 느린 반복 과정을 요구하지 않게 되었습니다.
이 논문들을 이어, Xun Huang과 Serge Belongie는 Adaptive Instance Normalization (AdaIN)을 제안하였으며, 이를 통해 실시간으로 임의의 스타일을 전송할 수 있게 되었습니다.
이 예시에서는 Neural Style Transfer를 위한 Adaptive Instance Normalization을 구현합니다. 아래 그림은 단 30 에포크 동안 트레이닝된 AdaIN 모델의 출력 결과를 보여줍니다.

또한 이 Hugging Face 데모를 통해, 자신의 이미지를 사용하여 모델을 체험할 수 있습니다.
셋업
필요한 패키지를 import 하는 것으로 시작합니다. 또한 재현 가능성을 위해 시드를 설정하고, 전역 변수는 우리가 원하는 대로 변경할 수 있는 하이퍼파라미터입니다.
import os
import numpy as np
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
import tensorflow_datasets as tfds
from tensorflow.keras import layers
# 전역 변수 정의.
IMAGE_SIZE = (224, 224)
BATCH_SIZE = 64
# 시간 제약을 위해 단일 에포크로 트레이닝.
# 좋은 결과를 보려면, 최소 30 에포크를 사용하세요.
EPOCHS = 1
AUTOTUNE = tf.data.AUTOTUNE스타일 전이 샘플 갤러리
Neural Style Transfer에서는 스타일 이미지와 콘텐츠 이미지가 필요합니다. 이 예시에서는 Best Artworks of All Time을 스타일 데이터셋으로, Pascal VOC을 콘텐츠 데이터셋으로 사용합니다.
이는 원본 논문의 구현과 다소 다릅니다. 원본 논문에서는 WIKI-Art을 스타일 데이터셋으로, MSCOCO을 콘텐츠 데이터셋으로 사용합니다. 이 예시에서는 최소한의 예시를 만들면서도, 재현 가능성을 보장하기 위해 이러한 변경을 했습니다.
Kaggle에서 데이터셋 다운로드
Best Artworks of All Time 데이터셋은 Kaggle에 호스팅되어 있으며, Colab에서 다음 단계를 따라 쉽게 다운로드할 수 있습니다:
Kaggle API 키가 없는 경우, 여기의 지침을 따라 Kaggle API 키를 얻으세요.
다음 명령어를 사용하여 Kaggle API 키를 업로드하세요.
from google.colab import files files.upload()아래 명령어를 사용해 API 키를 적절한 디렉터리로 옮기고 데이터셋을 다운로드하세요.
$ mkdir ~/.kaggle $ cp kaggle.json ~/.kaggle/ $ chmod 600 ~/.kaggle/kaggle.json $ kaggle datasets download ikarus777/best-artworks-of-all-time $ unzip -qq best-artworks-of-all-time.zip $ rm -rf images $ mv resized artwork $ rm best-artworks-of-all-time.zip artists.csv
tf.data 파이프라인
이 섹션에서는, 프로젝트를 위한 tf.data 파이프라인을 구축합니다.
스타일 데이터셋의 경우, 폴더에서 이미지를 디코딩하고 변환 및 리사이즈합니다.
콘텐츠 이미지는 tfds 모듈을 사용하여,
이미 tf.data 데이터셋으로 제공됩니다.
스타일과 콘텐츠 데이터 파이프라인을 준비한 후, 이 둘을 zip하여 모델이 사용할 데이터 파이프라인을 만듭니다.
def decode_and_resize(image_path):
"""이미지 파일 경로에서 이미지를 디코딩하고 리사이즈합니다.
Args:
image_path: 이미지 파일 경로.
Returns:
리사이즈된 이미지.
"""
image = tf.io.read_file(image_path)
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.convert_image_dtype(image, dtype="float32")
image = tf.image.resize(image, IMAGE_SIZE)
return image
def extract_image_from_voc(element):
"""PascalVOC 데이터셋에서 이미지를 추출합니다.
Args:
element: 데이터 딕셔너리.
Returns:
리사이즈된 이미지.
"""
image = element["image"]
image = tf.image.convert_image_dtype(image, dtype="float32")
image = tf.image.resize(image, IMAGE_SIZE)
return image
# 스타일 이미지의 파일 경로를 가져옵니다.
style_images = os.listdir("/content/artwork/resized")
style_images = [os.path.join("/content/artwork/resized", path) for path in style_images]
# 스타일 이미지를 train, val, test로 분리
total_style_images = len(style_images)
train_style = style_images[: int(0.8 * total_style_images)]
val_style = style_images[int(0.8 * total_style_images) : int(0.9 * total_style_images)]
test_style = style_images[int(0.9 * total_style_images) :]
# 스타일 및 콘텐츠 tf.data 데이터셋을 구축합니다.
train_style_ds = (
tf.data.Dataset.from_tensor_slices(train_style)
.map(decode_and_resize, num_parallel_calls=AUTOTUNE)
.repeat()
)
train_content_ds = tfds.load("voc", split="train").map(extract_image_from_voc).repeat()
val_style_ds = (
tf.data.Dataset.from_tensor_slices(val_style)
.map(decode_and_resize, num_parallel_calls=AUTOTUNE)
.repeat()
)
val_content_ds = (
tfds.load("voc", split="validation").map(extract_image_from_voc).repeat()
)
test_style_ds = (
tf.data.Dataset.from_tensor_slices(test_style)
.map(decode_and_resize, num_parallel_calls=AUTOTUNE)
.repeat()
)
test_content_ds = (
tfds.load("voc", split="test")
.map(extract_image_from_voc, num_parallel_calls=AUTOTUNE)
.repeat()
)
# 스타일 및 콘텐츠 데이터셋을 zip합니다.
train_ds = (
tf.data.Dataset.zip((train_style_ds, train_content_ds))
.shuffle(BATCH_SIZE * 2)
.batch(BATCH_SIZE)
.prefetch(AUTOTUNE)
)
val_ds = (
tf.data.Dataset.zip((val_style_ds, val_content_ds))
.shuffle(BATCH_SIZE * 2)
.batch(BATCH_SIZE)
.prefetch(AUTOTUNE)
)
test_ds = (
tf.data.Dataset.zip((test_style_ds, test_content_ds))
.shuffle(BATCH_SIZE * 2)
.batch(BATCH_SIZE)
.prefetch(AUTOTUNE)
)결과
[1mDownloading and preparing dataset voc/2007/4.0.0 (download: 868.85 MiB, generated: Unknown size, total: 868.85 MiB) to /root/tensorflow_datasets/voc/2007/4.0.0...[0m
Dl Completed...: 0 url [00:00, ? url/s]
Dl Size...: 0 MiB [00:00, ? MiB/s]
Extraction completed...: 0 file [00:00, ? file/s]
0 examples [00:00, ? examples/s]
Shuffling and writing examples to /root/tensorflow_datasets/voc/2007/4.0.0.incompleteP16YU5/voc-test.tfrecord
0%| | 0/4952 [00:00<?, ? examples/s]
0 examples [00:00, ? examples/s]
Shuffling and writing examples to /root/tensorflow_datasets/voc/2007/4.0.0.incompleteP16YU5/voc-train.tfrecord
0%| | 0/2501 [00:00<?, ? examples/s]
0 examples [00:00, ? examples/s]
Shuffling and writing examples to /root/tensorflow_datasets/voc/2007/4.0.0.incompleteP16YU5/voc-validation.tfrecord
0%| | 0/2510 [00:00<?, ? examples/s]
[1mDataset voc downloaded and prepared to /root/tensorflow_datasets/voc/2007/4.0.0. Subsequent calls will reuse this data.[0m데이터 시각화
트레이닝 전에 데이터를 시각화하는 것이 좋습니다. 우리의 전처리 파이프라인이 올바르게 작동하는지 확인하기 위해, 데이터셋에서 10개의 샘플을 시각화합니다.
style, content = next(iter(train_ds))
fig, axes = plt.subplots(nrows=10, ncols=2, figsize=(5, 30))
[ax.axis("off") for ax in np.ravel(axes)]
for (axis, style_image, content_image) in zip(axes, style[0:10], content[0:10]):
(ax_style, ax_content) = axis
ax_style.imshow(style_image)
ax_style.set_title("Style Image")
ax_content.imshow(content_image)
ax_content.set_title("Content Image")
아키텍쳐
스타일 전이 네트워크는 콘텐츠 이미지와 스타일 이미지를 입력으로 받아, 스타일이 전이된 이미지를 출력합니다. AdaIN의 저자들은 이를 위해 간단한 인코더-디코더 구조를 제안했습니다.
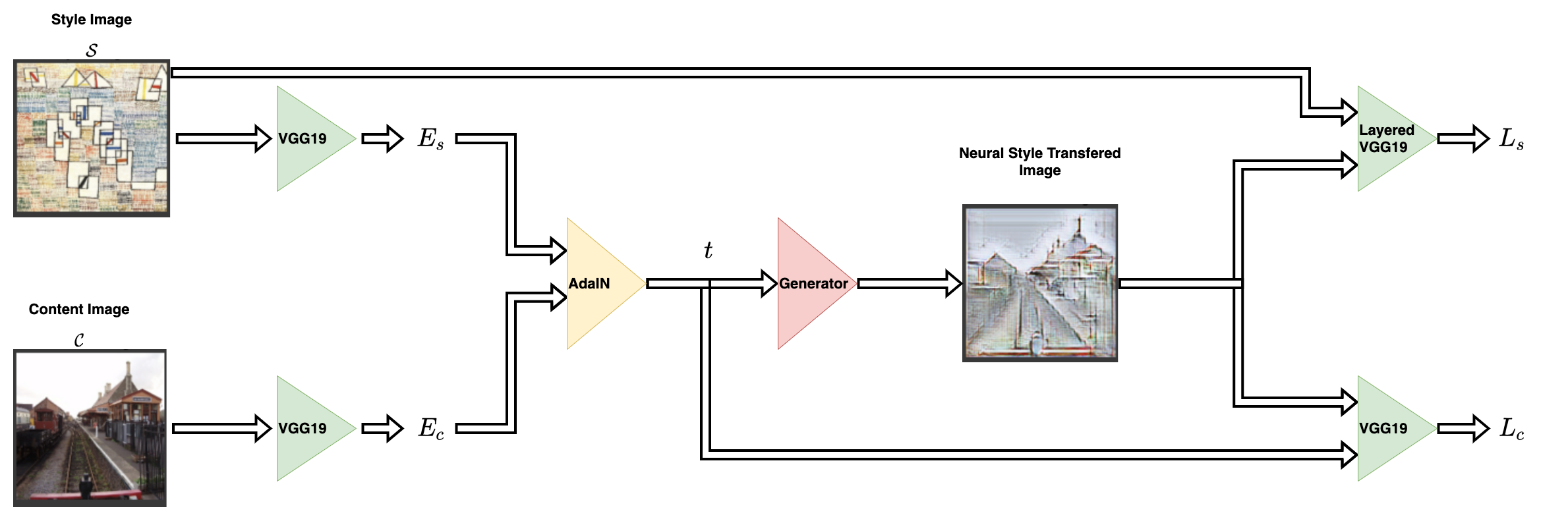
콘텐츠 이미지(C)와 스타일 이미지(S)는 모두 인코더 네트워크로 입력됩니다.
이러한 인코더 네트워크의 출력(특성 맵)은 AdaIN 레이어로 전달됩니다.
AdaIN 레이어는 결합된 특성 맵을 계산하며,
이 특성 맵은 무작위로 초기화된 디코더 네트워크에 전달됩니다.
디코더는 신경망을 통해 스타일이 전이된 이미지를 생성합니다.
$$ t = AdaIn(f_c, f_s) $$
$$ T = g(t) $$
스타일 특성 맵($f_s$)과 콘텐츠 특성 맵($f_c$)은 AdaIN 레이어로 전달됩니다. 이 레이어는 결합된 특성 맵 $t$를 생성합니다. 함수 $g$는 디코더(생성기) 네트워크를 나타냅니다.
인코더
인코더는 ImageNet에서 사전 트레이닝된 VGG19 모델의 일부입니다.
우리는 모델을 block4-conv1 레이어에서 잘라 사용합니다.
출력 레이어는 저자들이 논문에서 제안한 대로 설정됩니다.
def get_encoder():
vgg19 = keras.applications.VGG19(
include_top=False,
weights="imagenet",
input_shape=(*IMAGE_SIZE, 3),
)
vgg19.trainable = False
mini_vgg19 = keras.Model(vgg19.input, vgg19.get_layer("block4_conv1").output)
inputs = layers.Input([*IMAGE_SIZE, 3])
mini_vgg19_out = mini_vgg19(inputs)
return keras.Model(inputs, mini_vgg19_out, name="mini_vgg19")Adaptive Instance Normalization
AdaIN 레이어는 콘텐츠 이미지와 스타일 이미지의 특성을 입력으로 받습니다. 이 레이어는 다음과 같은 방정식으로 정의될 수 있습니다:
$$ AdaIn(x, y) = \sigma(y)(\frac{x-\mu(x)}{\sigma(x)})+\mu(y) $$
여기서 $\sigma$는 해당 변수에 대한 표준 편차, $\mu$는 평균을 나타냅니다. 위의 방정식에서 콘텐츠 특성 맵 $f_c$의 평균과 분산은 스타일 특성 맵 $f_s$의 평균과 분산에 맞춰집니다.
AdaIN 레이어는 저자들이 제안한 바에 따라 평균과 분산 이외의 매개변수를 사용하지 않습니다. 또한, 이 레이어는 트레이닝 가능한 매개변수를 포함하지 않습니다. 이러한 이유로 우리는 Keras 레이어 대신 Python 함수 를 사용합니다. 이 함수는 스타일과 콘텐츠 특성 맵을 받아서 이미지의 평균과 표준 편차를 계산하고, adaptive instance normalized 특성 맵을 반환합니다.
def get_mean_std(x, epsilon=1e-5):
axes = [1, 2]
# 텐서의 평균과 표준 편차를 계산합니다.
mean, variance = tf.nn.moments(x, axes=axes, keepdims=True)
standard_deviation = tf.sqrt(variance + epsilon)
return mean, standard_deviation
def ada_in(style, content):
"""AdaIN 특성 맵을 계산합니다.
Args:
style: 스타일 특성 맵.
content: 콘텐츠 특성 맵.
Returns:
AdaIN 특성 맵.
"""
content_mean, content_std = get_mean_std(content)
style_mean, style_std = get_mean_std(style)
t = style_std * (content - content_mean) / content_std + style_mean
return t디코더
저자들은 디코더 네트워크가 인코더 네트워크와 대칭적으로 반전되어야 한다고 명시했습니다.
우리는 인코더를 대칭적으로 반전시켜 디코더를 구축했으며,
특성 맵의 공간 해상도를 증가시키기 위해 UpSampling2D 레이어를 사용했습니다.
저자들은 디코더 네트워크에 어떤 정규화 레이어도 사용하지 않도록 경고하고 있으며, 실제로 배치 정규화나 인스턴스 정규화를 포함하면 전체 네트워크의 성능이 저하된다는 것을 보여줍니다.
이 부분은 전체 아키텍처 중에서 유일하게 트레이닝 가능한 부분입니다.
def get_decoder():
config = {"kernel_size": 3, "strides": 1, "padding": "same", "activation": "relu"}
decoder = keras.Sequential(
[
layers.InputLayer((None, None, 512)),
layers.Conv2D(filters=512, **config),
layers.UpSampling2D(),
layers.Conv2D(filters=256, **config),
layers.Conv2D(filters=256, **config),
layers.Conv2D(filters=256, **config),
layers.Conv2D(filters=256, **config),
layers.UpSampling2D(),
layers.Conv2D(filters=128, **config),
layers.Conv2D(filters=128, **config),
layers.UpSampling2D(),
layers.Conv2D(filters=64, **config),
layers.Conv2D(
filters=3,
kernel_size=3,
strides=1,
padding="same",
activation="sigmoid",
),
]
)
return decoder손실 함수
여기에서는 신경 스타일 전이 모델을 위한 손실 함수를 구축합니다. 저자들은 네트워크의 손실 함수를 계산하기 위해, 사전 트레이닝된 VGG-19를 사용할 것을 제안합니다. 이는 오직 디코더 네트워크를 트레이닝하는 데만 사용될 것이라는 점을 기억해야 합니다. 총 손실 (\mathcal{L}_t)은 콘텐츠 손실 ($\mathcal{L}_c$)과 스타일 손실 ($\mathcal{L}_s$)의 가중 조합입니다. $\lambda$ 항은 스타일 전이의 양을 조절하는 데 사용됩니다.
$$ \mathcal{L}_t = \mathcal{L}_c + \lambda \mathcal{L}_s $$
컨텐츠 손실
이는 콘텐츠 이미지 특성과 신경 스타일 전이 이미지 특성 간의 유클리드 거리입니다.
$$ \mathcal{L}_c = ||f(g(t))-t||_2 $$
여기서 저자들은 원본 이미지의 특성을 대상으로 사용하는 대신, AdaIn 레이어의 출력 $t$를 콘텐츠 대상으로 사용할 것을 제안합니다. 이는 수렴 속도를 높이기 위한 것입니다.
스타일 손실
보다 일반적으로 사용되는 Gram Matrix를 사용하는 대신, 저자들은 통계적 특성(평균 및 분산)의 차이를 계산할 것을 제안하며, 이는 개념적으로 더 깔끔합니다. 다음 방정식을 통해 쉽게 시각화할 수 있습니다:
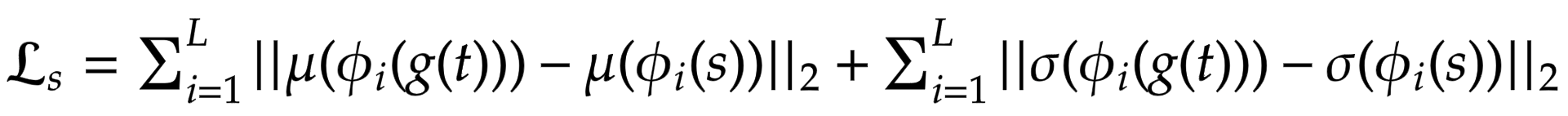
\mathcal{L}_s = \sum_{i=1}^{L} || \mu(\phi_i(g(t)))-\mu(\phi_i(s)) ||_2 + \sum_{i=1}^{L} || \sigma(\phi(g(t))) - \sigma(\phi_i(s))||_2여기서 theta는 VGG-19에서 손실을 계산하는 데 사용되는 레이어를 나타냅니다.
이 경우 해당 레이어는 다음과 같습니다:
block1_conv1block1_conv2block1_conv3block1_conv4
def get_loss_net():
vgg19 = keras.applications.VGG19(
include_top=False, weights="imagenet", input_shape=(*IMAGE_SIZE, 3)
)
vgg19.trainable = False
layer_names = ["block1_conv1", "block2_conv1", "block3_conv1", "block4_conv1"]
outputs = [vgg19.get_layer(name).output for name in layer_names]
mini_vgg19 = keras.Model(vgg19.input, outputs)
inputs = layers.Input([*IMAGE_SIZE, 3])
mini_vgg19_out = mini_vgg19(inputs)
return keras.Model(inputs, mini_vgg19_out, name="loss_net")신경 스타일 전이
이것은 트레이너 모듈입니다.
우리는 인코더와 디코더를 tf.keras.Model 서브클래스 내에 감쌉니다.
이를 통해 model.fit() 루프에서 발생하는 작업을 커스터마이즈할 수 있습니다.
class NeuralStyleTransfer(tf.keras.Model):
def __init__(self, encoder, decoder, loss_net, style_weight, **kwargs):
super().__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
self.loss_net = loss_net
self.style_weight = style_weight
def compile(self, optimizer, loss_fn):
super().compile()
self.optimizer = optimizer
self.loss_fn = loss_fn
self.style_loss_tracker = keras.metrics.Mean(name="style_loss")
self.content_loss_tracker = keras.metrics.Mean(name="content_loss")
self.total_loss_tracker = keras.metrics.Mean(name="total_loss")
def train_step(self, inputs):
style, content = inputs
# 콘텐츠와 스타일 손실을 초기화합니다.
loss_content = 0.0
loss_style = 0.0
with tf.GradientTape() as tape:
# 스타일 및 콘텐츠 이미지를 인코딩합니다.
style_encoded = self.encoder(style)
content_encoded = self.encoder(content)
# AdaIN 타겟 특성 맵을 계산합니다.
t = ada_in(style=style_encoded, content=content_encoded)
# 신경 스타일 전이된 이미지를 생성합니다.
reconstructed_image = self.decoder(t)
# 손실을 계산합니다.
reconstructed_vgg_features = self.loss_net(reconstructed_image)
style_vgg_features = self.loss_net(style)
loss_content = self.loss_fn(t, reconstructed_vgg_features[-1])
for inp, out in zip(style_vgg_features, reconstructed_vgg_features):
mean_inp, std_inp = get_mean_std(inp)
mean_out, std_out = get_mean_std(out)
loss_style += self.loss_fn(mean_inp, mean_out) + self.loss_fn(
std_inp, std_out
)
loss_style = self.style_weight * loss_style
total_loss = loss_content + loss_style
# 기울기를 계산하고, 디코더를 최적화합니다.
trainable_vars = self.decoder.trainable_variables
gradients = tape.gradient(total_loss, trainable_vars)
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
# 추적기를 업데이트합니다.
self.style_loss_tracker.update_state(loss_style)
self.content_loss_tracker.update_state(loss_content)
self.total_loss_tracker.update_state(total_loss)
return {
"style_loss": self.style_loss_tracker.result(),
"content_loss": self.content_loss_tracker.result(),
"total_loss": self.total_loss_tracker.result(),
}
def test_step(self, inputs):
style, content = inputs
# 콘텐츠와 스타일 손실을 초기화합니다.
loss_content = 0.0
loss_style = 0.0
# 스타일 및 콘텐츠 이미지를 인코딩합니다.
style_encoded = self.encoder(style)
content_encoded = self.encoder(content)
# AdaIN 타겟 특성 맵을 계산합니다.
t = ada_in(style=style_encoded, content=content_encoded)
# 신경 스타일 전이된 이미지를 생성합니다.
reconstructed_image = self.decoder(t)
# 손실을 계산합니다.
recons_vgg_features = self.loss_net(reconstructed_image)
style_vgg_features = self.loss_net(style)
loss_content = self.loss_fn(t, recons_vgg_features[-1])
for inp, out in zip(style_vgg_features, recons_vgg_features):
mean_inp, std_inp = get_mean_std(inp)
mean_out, std_out = get_mean_std(out)
loss_style += self.loss_fn(mean_inp, mean_out) + self.loss_fn(
std_inp, std_out
)
loss_style = self.style_weight * loss_style
total_loss = loss_content + loss_style
# 추적기를 업데이트합니다.
self.style_loss_tracker.update_state(loss_style)
self.content_loss_tracker.update_state(loss_content)
self.total_loss_tracker.update_state(total_loss)
return {
"style_loss": self.style_loss_tracker.result(),
"content_loss": self.content_loss_tracker.result(),
"total_loss": self.total_loss_tracker.result(),
}
@property
def metrics(self):
return [
self.style_loss_tracker,
self.content_loss_tracker,
self.total_loss_tracker,
]트레이닝 모니터 콜백
이 콜백은 각 epoch가 끝날 때마다 스타일 전이 모델의 출력을 시각화하는 데 사용됩니다. 스타일 전이의 목표는 정량적으로 측정할 수 없으며, 주관적으로 평가되어야 합니다. 이러한 이유로, 시각화는 모델을 평가하는 중요한 측면입니다.
test_style, test_content = next(iter(test_ds))
class TrainMonitor(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
# 스타일 및 콘텐츠 이미지를 인코딩합니다.
test_style_encoded = self.model.encoder(test_style)
test_content_encoded = self.model.encoder(test_content)
# AdaIN 특성 맵을 계산합니다.
test_t = ada_in(style=test_style_encoded, content=test_content_encoded)
test_reconstructed_image = self.model.decoder(test_t)
# 스타일, 콘텐츠 및 NST 이미지를 출력합니다.
fig, ax = plt.subplots(nrows=1, ncols=3, figsize=(20, 5))
ax[0].imshow(tf.keras.utils.array_to_img(test_style[0]))
ax[0].set_title(f"Style: {epoch:03d}")
ax[1].imshow(tf.keras.utils.array_to_img(test_content[0]))
ax[1].set_title(f"Content: {epoch:03d}")
ax[2].imshow(
tf.keras.utils.array_to_img(test_reconstructed_image[0])
)
ax[2].set_title(f"NST: {epoch:03d}")
plt.show()
plt.close()모델 트레이닝
이 섹션에서는 옵티마이저, 손실 함수, 그리고 트레이너 모듈을 정의합니다. 옵티마이저와 손실 함수로 트레이너 모듈을 컴파일한 후, 트레이닝을 진행합니다.
참고: 시간 제한으로 인해 모델을 한 epoch 동안만 트레이닝하지만, 좋은 결과를 보려면 최소 30 epoch 동안 트레이닝이 필요합니다.
optimizer = keras.optimizers.Adam(learning_rate=1e-5)
loss_fn = keras.losses.MeanSquaredError()
encoder = get_encoder()
loss_net = get_loss_net()
decoder = get_decoder()
model = NeuralStyleTransfer(
encoder=encoder, decoder=decoder, loss_net=loss_net, style_weight=4.0
)
model.compile(optimizer=optimizer, loss_fn=loss_fn)
history = model.fit(
train_ds,
epochs=EPOCHS,
steps_per_epoch=50,
validation_data=val_ds,
validation_steps=50,
callbacks=[TrainMonitor()],
)결과
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5
80142336/80134624 [==============================] - 1s 0us/step
80150528/80134624 [==============================] - 1s 0us/step
50/50 [==============================] - ETA: 0s - style_loss: 213.1439 - content_loss: 141.1564 - total_loss: 354.3002
50/50 [==============================] - 124s 2s/step - style_loss: 213.1439 - content_loss: 141.1564 - total_loss: 354.3002 - val_style_loss: 167.0819 - val_content_loss: 129.0497 - val_total_loss: 296.1316추론
모델을 트레이닝한 후, 이제 임의의 콘텐츠 이미지와 스타일 이미지를 테스트 데이터셋에서 사용하여 추론을 실행합니다. 생성된 출력 이미지를 확인해봅니다.
참고: 이 모델을 직접 사용해보고 싶다면, Hugging Face 데모를 이용할 수 있습니다.
for style, content in test_ds.take(1):
style_encoded = model.encoder(style)
content_encoded = model.encoder(content)
t = ada_in(style=style_encoded, content=content_encoded)
reconstructed_image = model.decoder(t)
fig, axes = plt.subplots(nrows=10, ncols=3, figsize=(10, 30))
[ax.axis("off") for ax in np.ravel(axes)]
for axis, style_image, content_image, reconstructed_image in zip(
axes, style[0:10], content[0:10], reconstructed_image[0:10]
):
(ax_style, ax_content, ax_reconstructed) = axis
ax_style.imshow(style_image)
ax_style.set_title("Style Image")
ax_content.imshow(content_image)
ax_content.set_title("Content Image")
ax_reconstructed.imshow(reconstructed_image)
ax_reconstructed.set_title("NST Image")
결론
Adaptive Instance Normalization은 실시간으로 임의의 스타일 전이를 가능하게 합니다. 또한, 스타일과 콘텐츠 이미지의 통계적 특성(평균과 표준 편차)을 정렬하는 방식으로만 이를 달성한다는 것이 저자들의 중요한 제안입니다.
참고: AdaIN은 또한 Style-GANs의 기반이 됩니다.
참조
Acknowledgement
Luke Wood에게 상세한 리뷰에 대해 감사드립니다.